Deep Cross-Modal Hashing
关键词:cross-Modal, deep learning
因为cross-modal hashing的低存储和高效的查询能力,被广泛用于多媒体的相似度检索中。本论文提出了一个deep cross-modal hashing(DCMH),首次将feature learning和hash-code learning结合到同一个框架中。
DCMH的框架:
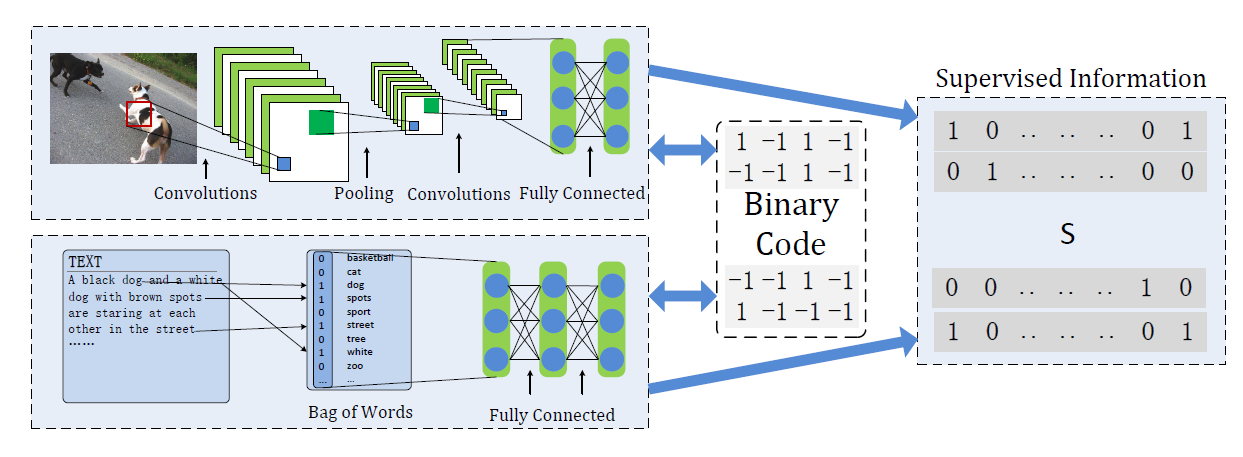
该框架包含两个deep Neural Network,一个是提取image的feature,另一个提取text中的feature。
CNN的结构为:

其中包含五个conv layer和三个fc layer,LRN表示加入了Local Response Normalization,
BoW的结构为:

根据上面的feature learning得到hash code,
其中DCMH的objective function是
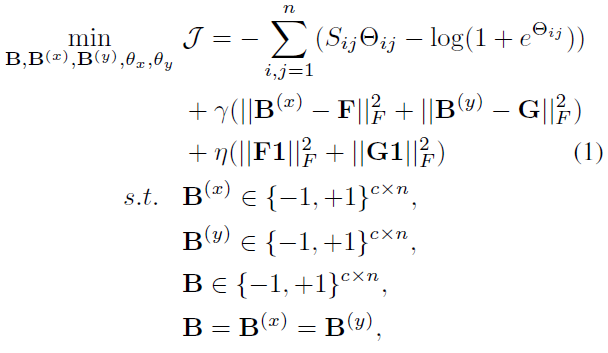
最后多次实验,发现如果两个模态同一个类的训练样本的binary code设置为一致,会取得更好的效果。
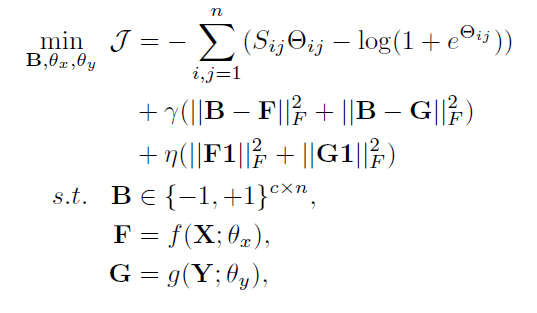
learning method
采取了一种交叉学习的策略,同时对 X, Y 和B进行学习。保持X与Y的网络对B进行training,然后保持B的参数不变而对X与Y的网络进行training。

当固定Y网络和B时,对X网络进行优化:
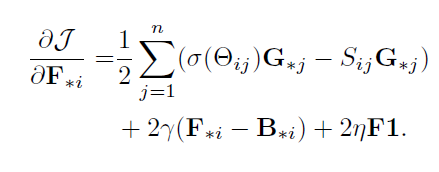
当固定X网络和B时,对y网络进行优化:
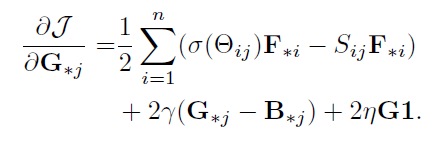
当固定X,Y网络和时,对B进行优化:
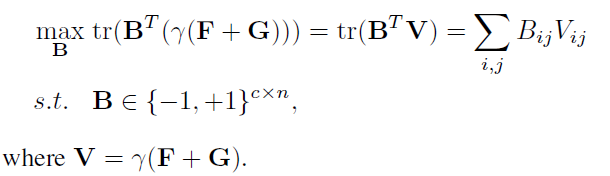
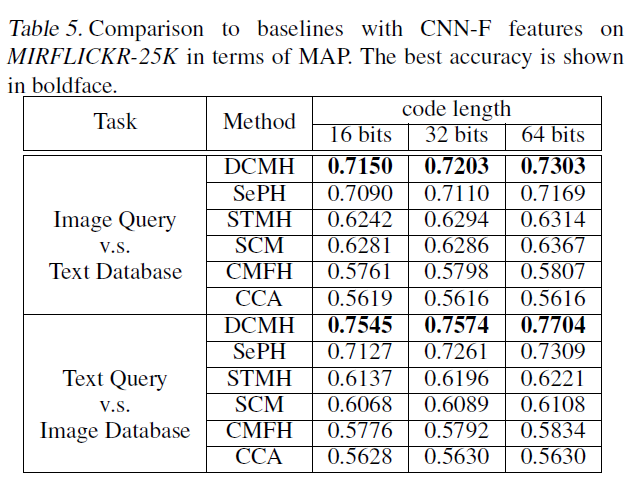
实验效果:
个人感受:
用deep learning工具加入cross-modal这个领域,且第一次完成了end-to-end的框架的设计。