序列化是指把内存里的数据类型转换成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘和网络传输时只能接受bytes
一、pickle
把python对象写入到文件中的一种解决方案,但是写入到文件的是bytes. 所以这东西不是给人看的. 是给机器看的.
##
bs = pickle.dumps(obj) 把对象转为bytes
obj = pickle.loads(bs) 把bytes转为对象
pickle.dump(obj,fielname) 把对象写入到文件
obj = pickle.load(filename) 从文件中拿对象


1 import pickle 2 3 class Cat: 4 def __init__(self,color,name): 5 self.name = name 6 self.color = color 7 8 def he(self): 9 print("喝水") 10 11 def chi(self): 12 print("%s吃小鱼" % self.name) 13 c = Cat('黑','小花') 14 print(c) 15 16 bs = pickle.dumps(c) #将对象转为bytes 17 # print(bs) 18 19 cc = pickle.loads(b'x80x03c__main__ Cat qx00)x81qx01}qx02(Xx04x00x00x00nameqx03Xx06x00x00x00xe5xb0x8fxe8x8axb1qx04Xx05x00x00x00colorqx05Xx03x00x00x00xe9xbbx91qx06ub.' 20 ) #将bytes转为对象 21 # pickle.loads 是拿着bytes的存储的对象信息和类的地址再去造一个对象,如果类增加了方法,造的对象也会具有该方法 22 print(cc) 23 cc.chi() 24 cc.he() # 25 print(cc.name,cc.color) 26 27 28 print("-------写入文件-------------") 29 pickle.dump(c,open("cat.txt",mode="wb")) #将对象写到文件中 30 #Write a pickled representation of the given object to the open file. 31 32 c2 = pickle.load(open("cat.txt",mode="rb")) #从文件拿到对象 33 c2.chi() 34 print(c2.name) 35 36 print("------写入多个-------") 37 c1 = Cat("黑","小黑") 38 print(c1) 39 c2 = Cat('白','大白') 40 c3 = Cat('灰','灰灰') 41 lst = [c1,c2,c3] 42 43 pickle.dump(lst,open("duocat.txt",mode="wb")) 44 45 l = pickle.load(open("duocat.txt",mode='rb')) 46 for dc in l: 47 dc.chi() 48 print(dc)
二、shelve
shelve提供python的持久化操作。什么叫持久化操作呢? 就是把数据写到硬盘上。在操作shelve的时候非常的像操作一个字典。
d = shelve.open('文件名') #打开文件,会自动生成一个 .dat 文件
d[key] =value #赋值
d[key] #拿值
d[key] = newvalue #修改
d.close() #关闭文件
注意:
修改shelve文件时要加writeback =True ,这是让内存中数据回写到文件。
1 import shelve 2 3 # d = shelve.open("shelve") 4 # d["小数据库"]= "shelve" 5 # d.close() 6 7 d = shelve.open("shelve") 8 print(d['小数据库']) 9 d.close() 10 11 #修改 12 d = shelve.open('shelve') 13 d['小数据库'] = '字典' 14 d.close() 15 16 c = shelve.open('shelve') 17 print(c['小数据库']) 18 c.close() 19 20 #存储复杂字典 21 # di = shelve.open('shelve') 22 # di['wf'] = {"name":"汪峰",'wife':{'name':'章子怡','hobby':'看电影'}} 23 # di.close() 24 # 25 # dp = shelve.open('shelve') 26 # print(dp['wf']) 27 # dp.close() 28 29 #修改复杂字典 30 31 di = shelve.open('shelve',writeback=True) # 32 di['wf']['wife']['hobby'] ="听音乐" 33 di.close() 34 35 dp = shelve.open('shelve') 36 print(dp['wf']) 37 dp.close()
三、json
json是我们前后端交互的枢纽,相当于编程界的普通话。json全称javascript object notation. 翻译过来叫js对象简谱。
#用json实现前后端交互:
我们的程序是 在python中写的,但是前端那边是用JS来解析json的。所以,我们需要把我们程序产生的字典转化成json格式的json串(字符串),然后网络传输,前端接收到之后,怎么处理是它的事情。
常用操作:
json.dumps(dic,ensure_ascii=False) 把字典转换成json字符串 参数ensure_ascii=False可以让json处理中文字符
json.loads() 把json字符串转化成字典
json.dump() 把字典转换成json字符串. 写入到文件
json.load() 把文件中的json字符串读取. 转化成字典
1 import json 2 3 # 把字典转化成json字符串 4 dic = {"a": "女王", "b": "萝莉", "c": "小清新"} 5 s = json.dumps(dic) 6 print(s) # {"a": "u5973u738b", "b": "u841du8389", "c": 7 "u5c0fu6e05u65b0"} 8 9 # 把字典转化成json字符串 10 s = json.dumps(dic, ensure_ascii=False) #加一个参数处理成中文 11 print(s) # {"a": "女王", "b": "萝莉", "c": "小清新"} 12 13 #把json字符串转成字典 14 s = '{"a": "女王", "b": "萝莉", "c": "小清新"}' 15 dic = json.loads(s) 16 print(type(dic), dic) 17 18 #把对象打散成json写入到文件中 19 dic = {"a": "女王", "b": "萝莉", "c": "小清新"} 20 f = open("test.json", mode="w", encoding="utf-8") 21 json.dump(dic, f, ensure_ascii=False) 22 f.close() 23 24 #从文件中读取一个json 25 f = open("test.json", mode="r", encoding="utf-8") 26 dic = json.load(f) 27 f.close() 28 print(dic)
# # 我们可以向文件中写入多个json串,但是读取就不行了,因为写的话多个字典写到了一行,但读的时候一行里有多个字典就不好区分,所以无法正常读取。
如何解决呢?
两套方案. 方案一. 把所有的内容准备好统一 进行写入和读取. 但这样处理, 如果数据量小还好. 数据量大的话, 就不够友好了. 方案二. 不用 dump. 改用dumps和loads. 对每一行分别进行写入和读取处理.
1 import json 2 lst = [{"a": 1}, {"b": 2}, {"c": 3}] 3 # 分行写入 4 f = open("test.json", mode="w", encoding="utf-8") 5 for el in lst: 6 s = json.dumps(el, ensure_ascii=True) + " " 7 f.write(s) 8 f.close() 9 # 读取 10 f = open("test.json", mode="r", encoding="utf-8") 11 for line in f: 12 dic = json.loads(line.strip()) 13 print(dic) 14 f.close()
四、configparser模块
该模块用于配置文件,比如配置windows的 ini格式的文件。
可以包含一个或多个节(section),每个节可以有多个参数(键=值).
整个文件相当于一个大字典,每节相当于一个小字典,可以像字典一样进行操作。
#配置文件样式
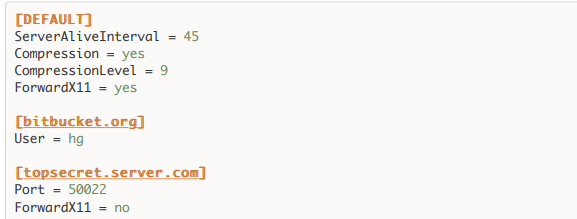
#用python初始化一个配置文件
1 初始化一个配置文件 .ini后缀 2 config = configparser.ConfigParser() #创建对象 3 config['DEFAULT'] = { 4 "sleep": 1000, 5 "session-time-out": 30, 6 "user-alive": 999999 7 } 8 config['TEST-DB'] = { 9 "db_ip": "192.168.17.189", 10 "port": "3306", 11 "u_name": "root", 12 "u_pwd": "123456" 13 } 14 config['168-DB'] = { 15 "db_ip": "152.163.18.168", 16 "port": "3306", 17 "u_name": "root", 18 "u_pwd": "123456" 19 } 20 config['173-DB'] = { 21 "db_ip": "152.163.18.173", 22 "port": "3306", 23 "u_name": "root", 24 "u_pwd": "123456" 25 } 26 f = open("db.ini", mode="w") 27 config.write(f) # 写入文件 28 f.flush() 29 f.close()
#读取文件信息
1 config = configparser.ConfigParser() 2 config.read("db.ini") # 读取文件 3 print(config.sections()) # 获取到section. 章节...DEFAULT是给每个章节都配备的信息 4 print(config.get("DEFAULT", "SESSION-TIME-OUT")) # 从xxx章节中读取到xxx信息 5 # 也可以像字典一样操作 6 print(config["TEST-DB"]['DB_IP']) 7 print(config["173-DB"]["db_ip"]) #可以不区分大小写 8 for k in config['168-DB']: 9 print(k) 10 for k, v in config["168-DB"].items(): 11 print(k, v) 12 print(config.options('168-DB')) # 同for循环,找到'168-DB'下所有键 13 print(config.items('168-DB')) #找到'168-DB'下所有键值对 14 print(config.get('168-DB','db_ip')) # 152.163.18.168 get方法Section下的key对应的value
#增删改操作
1 # 先读取. 然后修改. 最后写回文件 2 config = configparser.ConfigParser() 3 config.read("db.ini") # 读取文件 4 # 添加一个章节 5 # config.add_section("189-DB") 6 # config["189-DB"] = { 7 # "db_ip": "167.76.22.189", 8 # "port": "3306", 9 # "u_name": "root", 10 # "u_pwd": "123456" 11 # } 12 # 修改信息 13 config.set("168-DB", "db_ip", "10.10.10.168") 14 # 删除章节 15 config.remove_section("173-DB") 16 # 删除元素信息 17 config.remove_option("168-DB", "u_name") 18 # 写回文件 19 config.write(open("db.ini", mode="w"))