scrapy框架
1.scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,使用了Twisted(扭曲)异步
网络框架,可以加快下载是速度。
同步异步(过程) 阻塞非阻塞(状态)
1.scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,使用了Twisted(扭曲)异步
网络框架,可以加快下载是速度。
同步异步(过程) 阻塞非阻塞(状态)
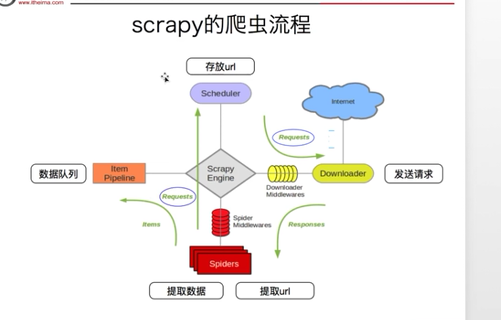

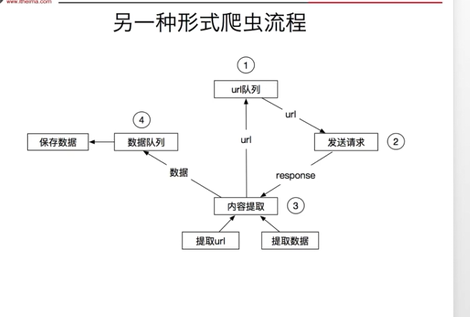
2.工作流程:
scheduler(调度器)里面存放request对象,这个对象里有url地址
scrapy engine 引擎
Downloader 下载器 根据请求做出响应,交给引擎
Spiders 爬虫 把url构造成request对象,交给调度器 将数据交给Item Pipeline
两个中间键可以对request response做一些处理
spider中间键不会对提取的数据进行处理,是专门用item pipeline来将数据进行处理,
Scrapy Engine:引擎,处理整个框架的数据流
Scheduler:调度器,接收引擎发过来的请求,将其排至队列中,当引擎再次请求时返回
Downloader:下载器,下载所有引擎发送的请求,并将获取的源代码返回给引擎,之后由引擎交给爬虫处理
Spiders:爬虫,接收并处理所有引擎发送过来的源代码,从中分析并提取item字段所需要的数据,并将需要跟进的url提交给引擎,再次进入调度器
Item Pipeline:管道,负责处理从爬虫中获取的Item,并进行后期处理
Downloader Middlewares:下载中间件,可以理解为自定义扩展下载功能的组件
Spider Middlewares:Spider中间件,自定义扩展和操作引擎与爬虫之间通信的功能组件
3.scrapy的所有命令都是在windows的终端里完成的
3.scrapy的所有命令都是在windows的终端里完成的