1.SKEP采用RoBERTa作为基线模型。RoBERTa相对于BERT的改进之处如下:
(1)去除了BERT中的NSP任务
(2)增加了batch size的大小,并且增加了训练的数据
(3)采用了动态mask的方式
(4)BERT使用的是字符级编码方式,但是RoBERTa使用的是byte-level text encoding
2.SKEP在BERT的预训练过程中加入了情感知识,这样更有利于情感分类任务。
SKEP通过PMI方法从句子中自动挖掘情感知识,情感知识包括情感词、词的极性和方面-情感对,其中方面-情感对的提取是通过简单的约束完成的(情感词和它所描述的名词之间的距离不会超过3).
情感掩蔽(删除这些识别出来的情感信息,产生一个损坏的版本),屏蔽序列的过程按照如下过程:(1)最多随机选择两个方面-情感对被mask (2)对于没有被屏蔽的情感词,随机选择其中的一部分,将它的标记替换成mask,被屏蔽的token总数不超过10%。(3)如果第二步中情感词的token比例不足10%,那么就随机去mask其他的字。
之后就进行情感预训练,情感预训练的目标优化函数 (Sentiment Pre-training Objectives)有3个目标优化函数组成,分别为Sentiment Word Objectives(
)、Word Polarity Objectives(
)和Aspect-sentiment Pair Objectives(
)。
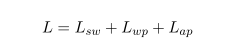
Sentiment Word Objectives( )情感词预测,恢复被mask的情感词标记,它的目标是将在整个词汇表中生成的规范化向量中原始情感词的概率最大化。
Word Polarity Objectives( )词极性预测 对于被mask的情感词,预测它的极性。
Aspect-sentiment Pair Objectives( )方面-情感对预测 是为了捕捉方面和情感之间的关系,成对的词之间并不相互排斥,但是在BERT里面,每个词是被独立预测的,并不存在依存关系。在方面-情感对预测中使用的是多标签分类,通过[CLS]标记来预测方面-情感对。
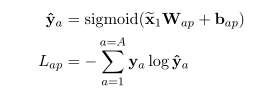
公式中的x1是[CLS]的输出向量,A是损坏序列中被mask的方面-情感对数量,ya是方面-情感对中的稀疏表示,每一个元素代表词汇表中的一个标记,如果情感对中包含相应的token,那么它的值为1。因为对方面-情感对的预测是多标签分类,所以输出的向量中会有多个1出现。
3.对于模型的分析
(1)情感知识的作用 通过对目标的比较,我们认为情绪知识是有帮助的,且知识的多样性有利于提高绩效。这也鼓励我们在未来使用更多类型的知识,使用更好的方法。
(2)多标签优化的效果 提出了多标签分类方法来处理方面-情感对中的依赖关系。在方面级分类和意见角色标注方面,多标签分类效率较高,最多可提高0.6个点。这表明多标签分类确实更好地捕捉了方面和情感之间的依赖关系,也说明了处理这种依赖关系的必要性。
(3)在方面-情感对预测中有两种方式,一种是通过[CLS]来进行对句子的预测,这种方法成为sent-vector方法。另一种是将两个单词的最终向量 串联成一对,成为Pair-vector方法,这两种方法的性能差不多,但是使用单个向量进行预测效率更高,因此在SKEP模型中采用了sent-vector方法进行了方面-情感对的预测。