注:这里主要是爬取自己喜欢的图片,并存到该文件中
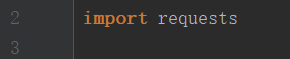
第一步:导包requests
import requests
第二步:这里我爬取的是图片,所以这里属于图片路径,如果是其它的,就填其它所属的路径
url= "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1607909203&di=30652d3d2a369269793ff69a9fd5eae6&src=http://a2.att.hudong.com/27/81/01200000194677136358818023076.jpg"

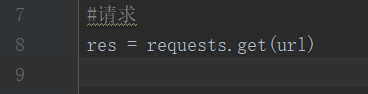
第三步:进行请求
res = requests.get(url)
第四步:保存数据(有两种方式)
方式一:
#保存 f = open("图片.jpg","wb") #这里'b'代表是二进制,“w”代表写的方式,“图片.jpg”是保存时所取得名字,也可以根据自己来 #进行写入信息 f.write(res.content) #释放资源 f.close()
方式二(方式二要比方式一常用):
with open("图片.jpg","wb") as f: f.write(res.content)
注:运行成功之后,该文件中会有“图片.jpg”的文件存在
整体代码:


#简单使用requests库 import requests #路径 url= "https://ss0.bdstatic.com/94oJfD_bAAcT8t7mm9GUKT-xh_/timg?image&quality=100&size=b4000_4000&sec=1607909203&di=30652d3d2a369269793ff69a9fd5eae6&src=http://a2.att.hudong.com/27/81/01200000194677136358818023076.jpg" #请求 res = requests.get(url) #保存 #方式一 f = open("图片.jpg","wb") #这里'b'代表是二进制 #进行写入信息 f.write(res.content) #释放资源 f.close() #方式二 # with open("图片.jpg","wb") as f: # f.write(res.content)