遗传算法 一次次求得最优解
进化策略 有效避免局部最优(过拟合) 并行能力计算
强化学习
什么都不懂->找到规律 给你的行为打分
核心思想:同样的行为拿到高分,并避免低分的行为 分数导向性

不理解环境:从环境中得到反馈
理解环境:为现实世界建模,多出来个虚拟环境
通过过往的经验理解现实世界是怎样的,并建立一个模型来模拟现实世界的反馈 现实模拟两世界中都可以玩耍
通过想象来预判要发生的所有情况,根据想象中的情况选择最好的那种,并根据这种情况来采取下一步的策略
基于概率 Policy Gradients
通过感官分析所处的环境,直接算出下一步采取行动的概率,根据概率采取行动,每一种动作都可能被选中,只是可能性不同
基于价值:决策部分更为肯定,毫不留情就选价值最高的 (连续的动作无能为力)Q Learning Sarsa
Actor-Critic 基于概率做出动作,并对做出的动作给出动作的价值
Q Learning
off-policy 不怕死
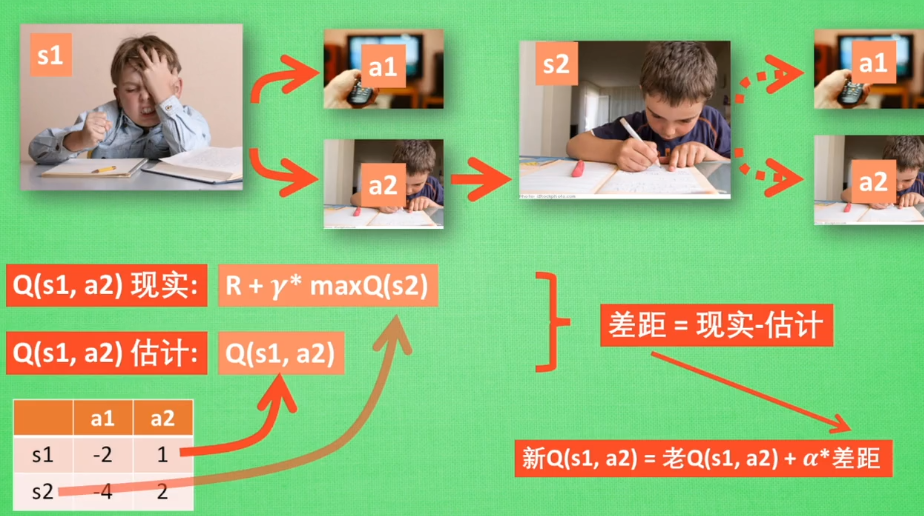

greedy 决策上的一种策略
a 学习效率 决定这次误差有多少要被学习 <1
y 未来奖励的衰减值
缺点:所有记录都在表格里,很快表格空间被用完,无法处理复杂的问题
Sarsa
![]()
on-policy 在线学习 单步更新 更保守、安全
Sarsa(lambda) 更行选择的步数 衰变值
lambda 0为单步更新1为回合更新 介于0~1之间 (离宝藏越近更新力度越大)
回合更新:走的步数都是为了得到宝藏所要学习的步
DQN(deep q network)
Policy Gradients
直接输出动作 连续区间内选择动作
误差反相传递 增加被选的概率 奖惩
神经网络
数学或计算机模型
生物神经网络
刺激产生新的连接,让信号通过新的连接传递而形成反馈
加了层之后想不到那么远 梯度消失

人脸识别

神经网络中的黑盒
将宝宝当作特征,feature 将神经网络第一层加工后的宝宝当作代表特征 -再次加工的代表特征--》例外代表特征 只有计算机看的懂
Tensorflow
安装:pip install --index-url http://mirrors.aliyun.com/pypi/simple/ tensorflow
逻辑回归
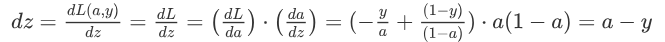
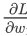
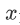
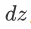
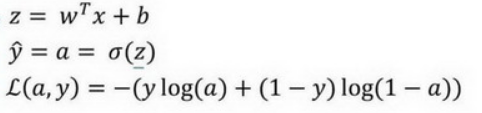 损失函数 代价 1/m * 损失 参数的总代价
损失函数 代价 1/m * 损失 参数的总代价
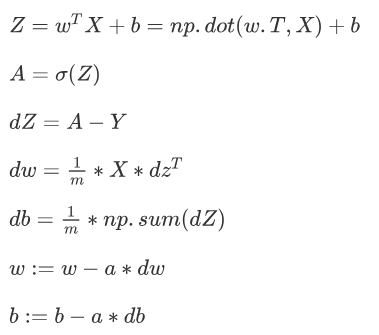
训练集-----------学生的课本;学生 根据课本里的内容来掌握知识。
验证集------------作业,通过作业可以知道 不同学生学习情况、进步的速度快慢。
测试集-----------考试,考的题是平常都没有见过,考察学生举一反三的能力。
偏差高 训练集误差高 更大的网络
方差高 训练集和测试集之间相差的误差高 数据
人眼辨别的错误率高 —— 最优误差高 | 贝叶斯误差