(1)下载kafka的jar包
spark2.1 支持kafka0.8.2.1以上的jar,我是spark2.0.2,下载的kafka_2.11-0.10.2.0
(2)Consumer代码
package com.sparkstreaming import org.apache.spark.SparkConf import org.apache.spark.streaming.Seconds import org.apache.spark.streaming.StreamingContext import org.apache.spark.streaming.kafka010.KafkaUtils import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe import org.apache.kafka.common.serialization.StringDeserializer object SparkStreamKaflaWordCount { def main(args: Array[String]): Unit = { //创建streamingContext var conf=new SparkConf().setMaster("spark://192.168.177.120:7077") .setAppName("SparkStreamKaflaWordCount Demo"); var ssc=new StreamingContext(conf,Seconds(4)); //创建topic //var topic=Map{"test" -> 1} var topic=Array("test"); //指定zookeeper //创建消费者组 var group="con-consumer-group" //消费者配置 val kafkaParam = Map( "bootstrap.servers" -> "192.168.177.120:9092,anotherhost:9092",//用于初始化链接到集群的地址 "key.deserializer" -> classOf[StringDeserializer], "value.deserializer" -> classOf[StringDeserializer], //用于标识这个消费者属于哪个消费团体 "group.id" -> group, //如果没有初始化偏移量或者当前的偏移量不存在任何服务器上,可以使用这个配置属性 //可以使用这个配置,latest自动重置偏移量为最新的偏移量 "auto.offset.reset" -> "latest", //如果是true,则这个消费者的偏移量会在后台自动提交 "enable.auto.commit" -> (false: java.lang.Boolean) ); //创建DStream,返回接收到的输入数据 var stream=KafkaUtils.createDirectStream[String,String](ssc, PreferConsistent,Subscribe[String,String](topic,kafkaParam)) //每一个stream都是一个ConsumerRecord stream.map(s =>(s.key(),s.value())).print(); ssc.start(); ssc.awaitTermination(); } }
(3)启动zk
//我是已经配置好zookeeper的环境变量了,
zoo1.cfg配置
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. dataDir=/home/zhangxs/datainfo/developmentData/zookeeper/zkdata1 # the port at which the clients will connect clientPort=2181 server.1=zhangxs:2881:3881
启动zk服务
zkServer.sh start zoo1.cfg
(4)启动kafka服务
【bin/kafka-server-start.sh config/server.properties】
[root@zhangxs kafka_2.11]# bin/kafka-server-start.sh config/server.properties [2017-03-25 18:42:03,153] INFO KafkaConfig values: advertised.host.name = null advertised.listeners = null advertised.port = null authorizer.class.name = auto.create.topics.enable = true auto.leader.rebalance.enable = true background.threads = 10 broker.id = 0 broker.id.generation.enable = true broker.rack = null compression.type = producer connections.max.idle.ms = 600000 controlled.shutdown.enable = true controlled.shutdown.max.retries = 3 controlled.shutdown.retry.backoff.ms = 5000 controller.socket.timeout.ms = 30000 create.topic.policy.class.name = null default.replication.factor = 1 delete.topic.enable = false fetch.purgatory.purge.interval.requests = 1000 group.max.session.timeout.ms = 300000 group.min.session.timeout.ms = 6000 host.name = inter.broker.listener.name = null inter.broker.protocol.version = 0.10.2-IV0 leader.imbalance.check.interval.seconds = 300
(5)(重新打开一个终端)启动生产者进程
[root@zhangxs kafka_2.11]# bin/kafka-console-producer.sh --broker-list 192.168.177.120:9092 --topic test
(6)将代码打成jar,jar名【streamkafkademo】,放到spark_home/jar/ 下面
(7)提交spark应用程序(消费者程序)
./spark-submit --class com.sparkstreaming.SparkStreamKaflaWordCount /usr/local/development/spark-2.0/jars/streamkafkademo.jar 10
(8)在生产者终端上输入数据
zhang xing sheng
(9)打印结果
17/03/25 19:06:36 INFO cluster.CoarseGrainedSchedulerBackend$DriverEndpoint: Launching task 99 on executor id: 0 hostname: 192.168.177.120. 17/03/25 19:06:36 INFO storage.BlockManagerInfo: Added broadcast_99_piece0 in memory on 192.168.177.120:35107 (size: 1913.0 B, free: 366.3 MB) 17/03/25 19:06:36 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 99.0 (TID 99) in 18 ms on 192.168.177.120 (1/1) 17/03/25 19:06:36 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 99.0, whose tasks have all completed, from pool 17/03/25 19:06:36 INFO scheduler.DAGScheduler: ResultStage 99 (print at SparkStreamKaflaWordCount.scala:34) finished in 0.019 s 17/03/25 19:06:36 INFO scheduler.DAGScheduler: Job 99 finished: print at SparkStreamKaflaWordCount.scala:34, took 0.023450 s ------------------------------------------- Time: 1490439996000 ms ------------------------------------------- (null,zhang xing sheng)
遇到过的问题:
(1)在使用eclipse编写消费者程序时发现没有KafkaUtils类。 这个jar是需要另下载的。然后build到你的工程里就可以了
maven
<dependency><groupId>org.apache.spark</groupId><artifactId>spark-streaming_2.11</artifactId><version>2.1.0</version></dependency>
jar下载
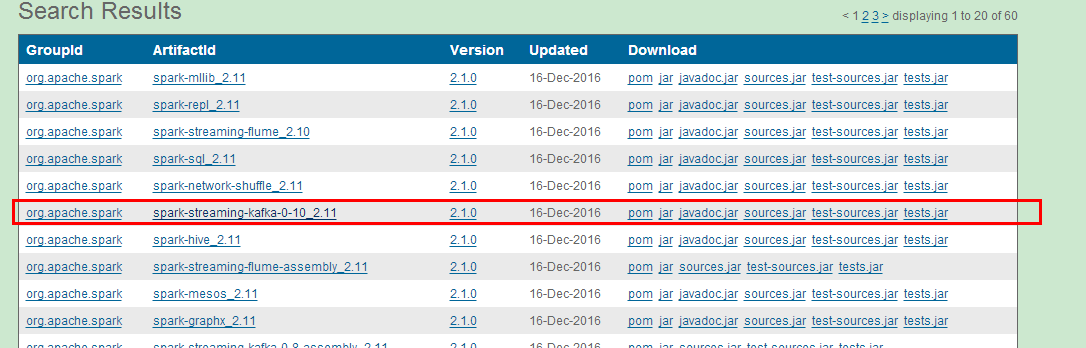
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/kafka/common/serialization/StringDeserializer at com.sparkstreaming.SparkStreamKaflaWordCount$.main(SparkStreamKaflaWordCount.scala:25) at com.sparkstreaming.SparkStreamKaflaWordCount.main(SparkStreamKaflaWordCount.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
------------------------------------------------------------------------ Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/streaming/kafka010/KafkaUtils$ at com.sparkstreaming.SparkStreamKaflaWordCount$.main(SparkStreamKaflaWordCount.scala:33) at com.sparkstreaming.SparkStreamKaflaWordCount.main(SparkStreamKaflaWordCount.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
这个需要你将【spark-streaming-kafka-0-10_2.11-2.1.0】,【kafka-clients-0.10.2.0】这两个jar添加到 spark_home/jar/路径下就可以了。(这个只是我这个工程里缺少的jar)