一、数据类型
1. 数据类型
数字(整形,长整形,浮点型,复数)
字符串
字节串(字节bytes类型)
列表
元组
字典
集合
2. 按照以下几个点展开数据类型的学习
#======================================基本使用====================================== #1、用途 #2、定义方式 #3、常用操作+内置的方法 #======================================该类型总结==================================== #存一个值or存多个值 #有序or无序 #可变or不可变(1、可变:值变,id不变。可变==不可hash 2、不可变:值变,id就变。不可变==可hash)
一.数字
整型与浮点型
#整型int 作用:年纪,等级,身份证号,qq号等整型数字相关 定义: age=10 #本质age=int(10) #浮点型float 作用:薪资,身高,体重,体质参数等浮点数相关 salary=3000.3 #本质salary=float(3000.3) #二进制,十进制,八进制,十六进制


#长整形(了解) 在python2中(python3中没有长整形的概念): >>> num=2L >>> type(num) <type 'long'> #复数(了解) >>> x=1-2j >>> x.real 1.0 >>> x.imag -2.0
二.字符串
#作用:名字,性别,国籍,地址等描述信息 #定义:在单引号双引号三引号内,由一串字符组成 name='pie' #优先掌握的操作: #1、按索引取值(正向取+反向取) :只能取 #2、切片(顾头不顾尾,步长) #3、长度len #4、成员运算in和not in #5、移除空白strip #6、切分split #7、循环
基本操作
#1、strip,lstrip,rstrip #2、lower,upper #3、startswith,endswith #4、format的三种玩法 #5、split,rsplit #6、join #7、replace #8、isdigit
#strip name='*egon**' print(name.strip('*')) print(name.lstrip('*')) print(name.rstrip('*')) #lower,upper name='egon' print(name.lower()) print(name.upper()) #startswith,endswith name='alex_SB' print(name.endswith('SB')) print(name.startswith('alex')) #format的三种玩法 res='{} {} {}'.format('egon',18,'male') res='{1} {0} {1}'.format('egon',18,'male') res='{name} {age} {sex}'.format(sex='male',name='egon',age=18) #split name='root:x:0:0::/root:/bin/bash' print(name.split(':')) #默认分隔符为空格 name='C:/a/b/c/d.txt' #只想拿到顶级目录 print(name.split('/',1)) name='a|b|c' print(name.rsplit('|',1)) #从右开始切分 #join tag=' ' print(tag.join(['egon','say','hello','world'])) #可迭代对象必须都是字符串 #replace name='alex say :i have one tesla,my name is alex' print(name.replace('alex','SB',1)) #isdigit:可以判断bytes和unicode类型,是最常用的用于于判断字符是否为"数字"的方法 age=input('>>: ') print(age.isdigit()) 示例
其他操作
#find,rfind,index,rindex,count name='egon say hello' print(name.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引 # print(name.index('e',2,4)) #同上,但是找不到会报错 print(name.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有 #center,ljust,rjust,zfill name='egon' print(name.center(30,'-')) print(name.ljust(30,'*')) print(name.rjust(30,'*')) print(name.zfill(50)) #用0填充 #expandtabs name='egon hello' print(name) print(name.expandtabs(1)) #captalize,swapcase,title print(name.capitalize()) #首字母大写 print(name.swapcase()) #大小写翻转 msg='egon say hi' print(msg.title()) #每个单词的首字母大写 #is数字系列 #在python3中 num1=b'4' #bytes num2=u'4' #unicode,python3中无需加u就是unicode num3='四' #中文数字 num4='Ⅳ' #罗马数字 #isdigt:bytes,unicode print(num1.isdigit()) #True print(num2.isdigit()) #True print(num3.isdigit()) #False print(num4.isdigit()) #False #isdecimal:uncicode #bytes类型无isdecimal方法 print(num2.isdecimal()) #True print(num3.isdecimal()) #False print(num4.isdecimal()) #False #isnumberic:unicode,中文数字,罗马数字 #bytes类型无isnumberic方法 print(num2.isnumeric()) #True print(num3.isnumeric()) #True print(num4.isnumeric()) #True #三者不能判断浮点数 num5='4.3' print(num5.isdigit()) print(num5.isdecimal()) print(num5.isnumeric()) ''' 总结: 最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景 如果要判断中文数字或罗马数字,则需要用到isnumeric ''' #is其他 print('===>') name='egon123' print(name.isalnum()) #字符串由字母或数字组成 print(name.isalpha()) #字符串只由字母组成 print(name.isidentifier()) print(name.islower()) print(name.isupper()) print(name.isspace()) print(name.istitle()) 示例
三 、列表
#作用:多个装备,多个爱好,多门课程,多个女朋友等 #定义:[]内可以有多个任意类型的值,逗号分隔 my_girl_friends=['alex','wupeiqi','yuanhao',4,5] #本质my_girl_friends=list([...]) 或 l=list('abc') #优先掌握的操作: #1、按索引存取值(正向存取+反向存取):即可存也可以取 #2、切片(顾头不顾尾,步长) #3、长度 #4、成员运算in和not in #5、追加 #6、删除 #7、循环
#ps:反向步长 l=[1,2,3,4,5,6] #正向步长 l[0:3:1] #[1, 2, 3] #反向步长 l[2::-1] #[3, 2, 1] #列表翻转 l[::-1] #[6, 5, 4, 3, 2, 1]
四 、元组
#作用:存多个值,对比列表来说,元组不可变(是可以当做字典的key的),主要是用来读 #定义:与列表类型比,只不过[]换成() age=(11,22,33,44,55)本质age=tuple((11,22,33,44,55)) #优先掌握的操作: #1、按索引取值(正向取+反向取):只能取 #2、切片(顾头不顾尾,步长) #3、长度 #4、成员运算in和not in #5、循环
五、字典
#作用:存多个值,key-value存取,取值速度快 #定义:key必须是不可变类型,value可以是任意类型 info={'name':'egon','age':18,'sex':'male'} #本质info=dict({....}) 或 info=dict(name='egon',age=18,sex='male') 或 info=dict([['name','egon'],('age',18)]) 或 {}.fromkeys(('name','age','sex'),None) #优先掌握的操作: #1、按key存取值:可存可取 #2、长度len #3、成员运算in和not in #4、删除 #5、键keys(),值values(),键值对items() #6、循环
练习
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中 即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
a={'k1':[],'k2':[]}
c=[11,22,33,44,55,66,77,88,99,90]
for i in c:
if i>66:
a['k1'].append(i)
else:
a['k2'].append(i)
print(a)
2 统计s='hello jqh jqh say hello sb sb'中每个单词的个数 结果如:{'hello': 2, 'jqh': 2, 'say': 1, 'sb': 2}
s='hello jqh jqh say hello sb sb' l=s.split() dic={} for item in l: if item in dic: dic[item]+=1 else: dic[item]=1 print(dic)
六、集合
#作用:去重,关系运算, #定义: 知识点回顾 可变类型是不可hash类型 不可变类型是可hash类型 #定义集合: 集合:可以包含多个元素,用逗号分割, 集合的元素遵循三个原则: 1:每个元素必须是不可变类型(可hash,可作为字典的key) 2:没有重复的元素 3:无序 注意集合的目的是将不同的值存放到一起,不同的集合间用来做关系运算,无需纠结于集合中单个值 #优先掌握的操作: #1、长度len #2、成员运算in和not in #3、|合集 #4、&交集 #5、-差集 #6、^对称差集 #7、== #8、父集:>,>= #9、子集:<,<=
maths={'李四','张三','王五','赵铜蛋','张锡蛋','jqh','赵六'}
arts={'zxx','pie','张三','张锡蛋','jqh','陈独秀'}
#取及报名math课程又报名art课程的学员:交集
print(maths & arts)
print(maths.intersection(arts))
#取所有报名暑假班课程的学员:并集
print(maths | arts)
print(maths.union(arts))
#取只报名math课程的学员: 差集
print(maths - arts)
print(maths.difference(arts))
#取只报名art课程的学员: 差集
print(arts - maths)
print(arts.difference(maths))
# 取没有同时报名两门课程的学员:对称差集
print(maths ^ arts)
print(maths.symmetric_difference(arts))
数据类型总结
按存储空间的占用分(从低到高)
数字 字符串 集合:无序,即无序存索引相关信息 元组:有序,需要存索引相关信息,不可变 列表:有序,需要存索引相关信息,可变,需要处理数据的增删改 字典:无序,需要存key与value映射的相关信息,可变,需要处理数据的增删改
按存值个数区分
| 标量/原子类型 | 数字,字符串 |
| 容器类型 | 列表,元组,字典 |
按可变不可变区分
| 可变 | 列表,字典 |
| 不可变 | 数字,字符串,元组 |
按访问顺序区分
| 直接访问 | 数字 |
| 顺序访问(序列类型) | 字符串,列表,元组 |
| key值访问(映射类型) | 字典 |
数字: >>> a = 111 >>> id(a) 1549733776 >>> a = 222 >>> id(a) 1549737328 结论:数字类型的变量值变更后内存地址发生改变 字符串: >>> a = "abcdefg" >>> id(a) 2363386268560 >>> a = "abcdefgggggg" >>> id(a) 2363386295024 元组: >>> a = ('aa','bb','cc') >>> id(a) 2363384788456 >>> a = ('aa','bb','dd') >>> id(a) 2363384789896 结论:元组类型的变量值改变后内存地址发生变化 列表: >>> a = {'name':'zhangsan','age':'33'} >>> id(a) 2363384325384 >>> a['name'] = 'lisi' >>> a {'name': 'lisi', 'age': '33'} >>> id(a) 2363384325384 结论:字典类型的变量值发生变化后内存地址未变更 汇总:当变量值为数字,字符串,元组数据类型时,数值发生变化后内存地址变更,以为着创建了一个新对象。因此不可变数据类型为:数字,字符串,元组。 当变量值为列表,字典数据类型时,数值发生变化后内存地址未变更,以为着变更后依然是在同一个对象,因此可变数据类型为:列表,字典。
二、字符编码
#1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 #2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,
此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。
只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了
unicode----->encode-------->utf-8
utf-8-------->decode---------->unicode
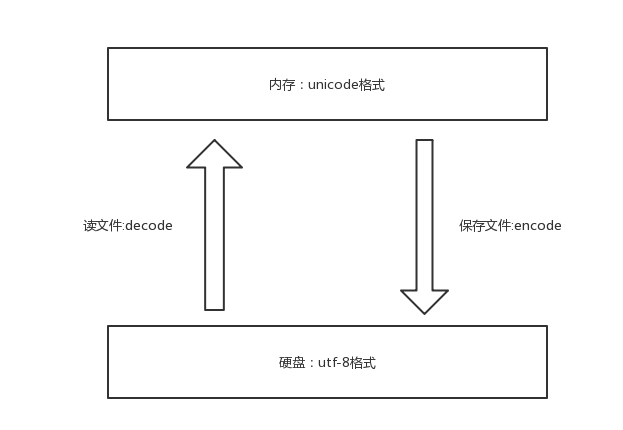
#补充: 浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器 如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的结果。
在python3 中也有两种字符串类型str和bytes
str是unicode
#coding:gbk x='上' #当程序执行时,无需加u,'上'也会被以unicode形式保存新的内存空间中, print(type(x)) #<class 'str'> #x可以直接encode成任意编码格式 print(x.encode('gbk')) #b'xc9xcf' print(type(x.encode('gbk'))) #<class 'bytes'>
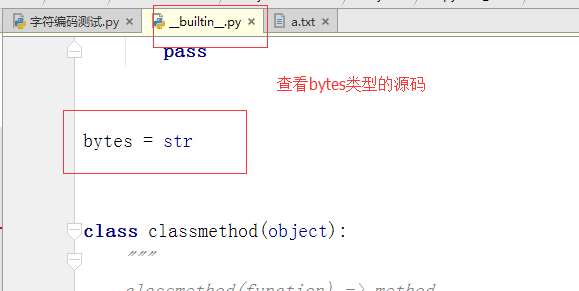
很重要的一点是:看到python3中x.encode('gbk') 的结果xc9xcf正是python2中的str类型的值,而在python3是bytes类型,在python2中则是str类型
于是我有一个大胆的推测:python2中的str类型就是python3的bytes类型,于是我查看python2的str()源码,发现
三、文件处理
1.什么是文件处理:
#coding:utf-8 ''' 1 什么是文件 文件是操作系统为用户/应用程序提供的一种操作硬盘的抽象单位 2 为何要用文件 用户/应用程序对文件的读写操作会由操作系统转换成具体的硬盘操作 所以用户/应用程序可以通过简单的读写文件来间接地控制复杂的硬盘的存取操作 实现将内存中的数据永久保存到硬盘中 user=input('>>>>: ') #user="pie " 3 如何用文件 文件操作的基本步骤: f=open(...) #打开文件,拿到一个文件对象f,f就相当于一个遥控器,可以向操作系统发送指令 f.read() # 读写文件,向操作系统发送读写文件指令 f.close() # 关闭文件,回收操作系统的资源 上下文管理: with open(...) as f: pass '''
open(r'D:PY_data a.txt') f=open(r'a.txt',encoding='utf-8') #向操作系统发送请求,要求操作系统打开文件 print(f) # f的值是一个文件对象 print(f.read()) f.close() # 向操作系统发送请求,要求操作系统关闭打开的文件 print(f) f.read() 强调:一定要在程序结束前关闭打开的文件 # 上下文管理with with open(r'a.txt',encoding='utf-8') as f, open('b.txt',encoding='utf-8') as f1: print(f.read()) print(f1.read())
2.文件详细操作
with open('a.txt',mode='rt',encoding='utf-8') as f: data=f.read() print(data,type(data)) with open('1.png',mode='rt',encoding='utf-8') as f: data=f.read() with open('1.png',mode='rb',) as f: data=f.read() print(data,type(data)) with open('a.txt',mode='rb',) as f: data=f.read() # print(data,type(data)) print(data.decode('utf-8')) with open('a.txt',mode='rt',encoding='utf-8') as f: data=f.read() print(data)
(1) r: 只读模式L(默认的) 1 当文件不存时,会报错 2 当文件存在时,文件指针指向文件的开头 with open('a.txt',mode='rt',encoding='utf-8') as f: res1=f.read() print('111===>',res1) res2=f.read() print('222===>',res2) print(f.read()) print(f.readable()) print(f.writable()) print(f.readline()) print(f.readline()) for line in f: print(line) l=[] for line in f: l.append(line) print(l) print(f.readlines()) (2) w: 只写模式 1 当文件不存时,新建一个空文档 2 当文件存在时,清空文件内容,文件指针跑到文件的开头 with open('c.txt',mode='wt',encoding='utf-8') as f: print(f.readable()) print(f.writable()) # print(f.read()) # f.write('哈哈哈') f.write('你愁啥 ') f.write('瞅你咋地 ') f.write('1111 2222 333 4444 ') info=['pie:123 ','jqh:456 ','zxx:123 '] for line in info: f.write(line) # f.writelines(info) with open('c.txt',mode='rb') as f: print(f.read()) with open('c.txt',mode='wb') as f: f.write('哈哈哈 '.encode('utf-8')) f.write('你愁啥 '.encode('utf-8')) f.write('瞅你咋地 '.encode('utf-8')) (3) a: 只追加写模式 1 当文件不存时,新建一个空文档,文件指针跑到文件的末尾 2 当文件存在时,文件指针跑到文件的末尾 with open('c.txt',mode='at',encoding='utf-8') as f: print(f.readable()) print(f.writable()) # f.read() f.write('虎老师:123 ') 在文件打开不关闭的情况下,连续的写入,下一次写入一定是基于上一次写入指针的位置而继续的 with open('d.txt',mode='wt',encoding='utf-8') as f: f.write('虎老师1:123 ') f.write('虎老师2:123 ') f.write('虎老师3:123 ') with open('d.txt',mode='wt',encoding='utf-8') as f: f.write('虎老师4:123 ')
3.可读可写模式
可读可写: r+t w+t a+t with open('a.txt',mode='r+t',encoding='utf-8') as f: # print(f.readable()) # print(f.writable()) msg=f.readline() print(msg) f.write('xxxxxxxxxxx ')
4.控制文件内指针的移动
f.seek 文件内指针移动,只有t模式下的read(n),n代表的字符的个数 除此以外文件内指针的移动都是以字节为单位 with open('a.txt',mode='rt',encoding='utf-8') as f: msg=f.read(1) print(msg) with open('a.txt',mode='rb') as f: msg=f.read(3) print(msg.decode('utf-8')) f.seek(offset,whence)有两个参数: offset: 代表控制指针移动的字节数 whence: 代表参照什么位置进行移动 whence = 0: 参照文件开头(默认的),特殊???,可以在t和b模式下使用 whence = 1: 参照当前所在的位置,必须在b模式下用 whence = 2: 参照文件末尾,必须在b模式下用 with open('a.txt',mode='rt',encoding='utf-8') as f: f.seek(6,0) msg=f.read(1) print(msg) with open('a.txt',mode='rb') as f: f.seek(3,0) msg=f.read(3) print(msg.decode('utf-8')) with open('a.txt',mode='rb') as f: msg=f.read(3) # print(msg.decode('utf-8')) print(f.tell()) # f.seek(6,0) f.seek(3,1) msg1=f.read(3) print(msg1.decode('utf-8')) with open('a.txt',mode='rb') as f: msg=f.read(3) # print(msg.decode('utf-8')) print(f.tell()) # f.seek(6,0) f.seek(3,1) msg1=f.read(3) print(msg1.decode('utf-8')) with open('a.txt',mode='rb') as f: # f.seek(0,2) # print(f.tell()) f.seek(-3,2) msg=f.read(3) print(msg.decode('utf-8')) with open('access.log',mode='rb') as f: f.seek(0,2) # 当前位置是147bytes while True: line=f.readline() # 当前位置是196bytes # print(f.tell()) if len(line) == 0: # 没有新的一行内容追加进来 pass else: # 有新的一行内容追加进来 print(line.decode('utf-8'),end='') with open('access.log',mode='rb') as f: f.seek(0,2) # 当前位置是147bytes while True: line=f.readline() # 当前位置是196bytes if len(line) != 0: print(line.decode('utf-8'),end='') with open('a.txt',mode='r+t',encoding='utf-8') as f: f.truncate(6)
五、文件修改的两种方式
(1)修改文件的方式一: 1 将文件内容由硬盘全部读入内存 2 在内存中完成修改 3 将内存中修改后的结果覆盖写回硬盘 with open('d.txt',mode='rt',encoding='utf-8') as f: all_data=f.read() print(all_data,type(all_data)) with open('d.txt',mode='wt',encoding='utf-8') as f: f.write(all_data.replace('jqh','dsb')) ------------------------------------------------------------------------------------------------ 错误的做法 with open('d.txt',mode='rt',encoding='utf-8') as f1,open('d.txt',mode='wt',encoding='utf-8') as f2: all_data=f1.read() f2.write(all_data.replace('dsb','jqh'))
(2)修改文件的方式二: 1 以读的方式打开源文件,以写的方式打开一个临时文件 2 从源文件中每读一样内容修改完毕后写入临时文件,直到源文件读取完毕 3 删掉源文件,将临时文件重命名为源文件名 import os with open('d.txt',mode='rt',encoding='utf-8') as read_f,open('.d.txt.swap',mode='wt',encoding='utf-8') as write_f: for line in read_f: write_f.write(line.replace('dsb','jqh')) os.remove('d.txt') os.rename('.d.txt.swap','d.txt')
(3)两种方法对比:
方式一:
优点: 在文件修改的过程中硬盘上始终一份数据
缺点: 占用内存过多,不适用于大文件
方式二:
优点: 同一时刻在内存中只存在源文件的一行内容,不会过多地占用内存
缺点: 在文件修改的过程中会出现源文件与临时文件共存,硬盘上同一时刻会有两份数据,即在修改的过程中会过多的占用硬盘