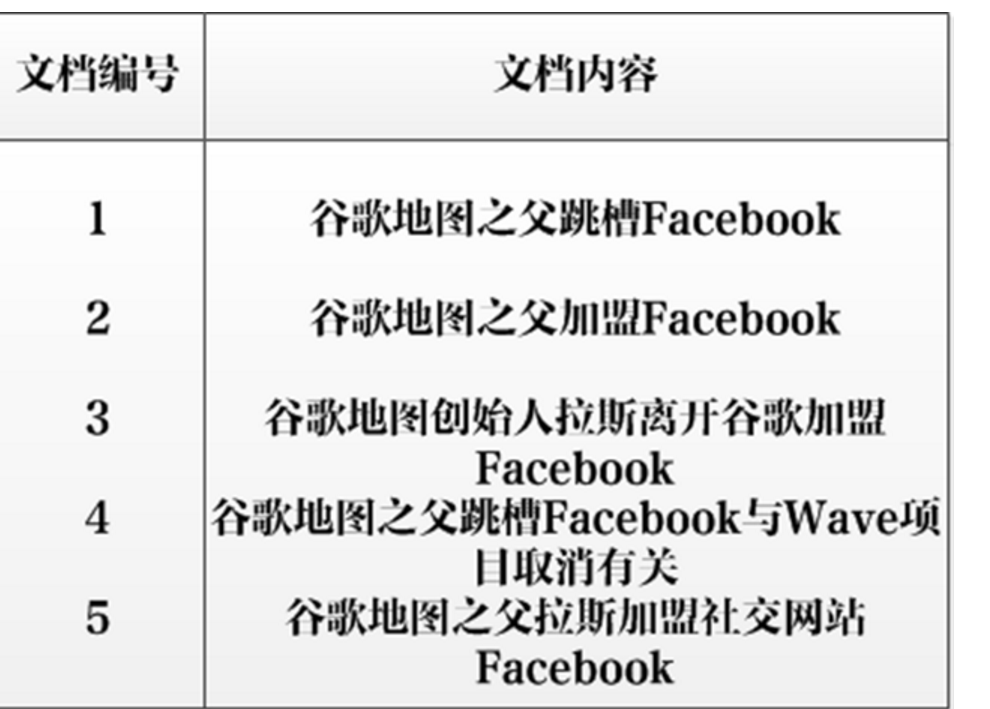
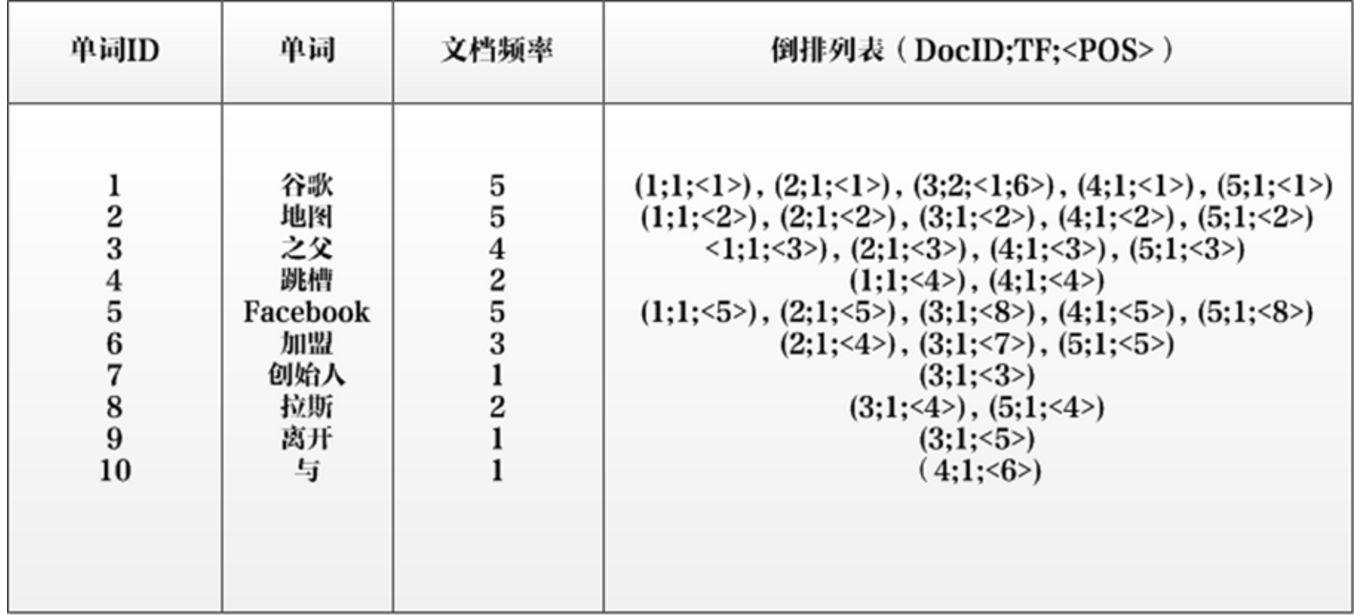
看别人的用jieba来实现.基本实现了搜索引擎基本功能.效率O(N)
通过inverted_index这个函数可以不停的把文件放到这个词典库里面.不知道百度什么的怎么处理网络上那么多数据.挨个存很难都存一遍.空间效率很慢


''' 倒排索引:https://blog.csdn.net/okiwilldoit/article/details/51362839 ''' ''' 先学分词系统jieba:pip install jieba即可. ''' import jieba s = u'我想和我女朋友一起去我的北京故宫博物院参观我的屋子和闲逛。' cut = jieba.cut(s) print ('output') print (cut) #返回的是一个迭代器.这对大数据很叼.我的理解是因为 #迭代器可以随时暂停,然后恢复继续上面的工作继续迭代 #数据太大也可以跑跑停停不用一直等,可以随时看结果 print (','.join(cut))#居然花了10秒! 精准模式.也是最常用的,第二次跑有cache就用了0.8s print (','.join(jieba.cut(s,cut_all = True)))#可见全模式就是把文本分成尽可能多的词。 print (','.join(jieba.cut_for_search(s)))#搜索引擎模式介于上面2者中间 #import jieba.posseg as psg ##下面一行返回的是分词后各个词性 ##print ([(x.word,x.flag) for x in psg.cut(s)])#x是字符串的意思,这一行太卡了我就注释掉了, #from collections import Counter#利用Counter这个容器可以返回频率top多少的词,但是速度很慢. #c = Counter(s).most_common(20) #print (c) ##下面学习用户字典: #txt = u'欧阳建国是创新办主任也是欢聚时代公司云计算方面的专家' #print (','.join(jieba.cut(txt))) #jieba.load_userdict('user_dict.txt')#注意这个词典,在同目录下,然后编码用笔记本打开另存为utf-8即可. #print (','.join(jieba.cut(txt)))#效果不错 ''' 下面可以进行倒排索引了 ''' #不要的虚词: _STOP_WORDS = frozenset([ 'a', 'about', 'above', 'above', 'across', 'after', 'afterwards', 'again', 'against', 'all', 'almost', 'alone', 'along', 'already', 'also', 'although', 'always', 'am', 'among', 'amongst', 'amoungst', 'amount', 'an', 'and', 'another', 'any', 'anyhow', 'anyone', 'anything', 'anyway', 'anywhere', 'are', 'around', 'as', 'at', 'back', 'be', 'became', 'because', 'become', 'becomes', 'becoming', 'been', 'before', 'beforehand', 'behind', 'being', 'below', 'beside', 'besides', 'between', 'beyond', 'bill', 'both', 'bottom', 'but', 'by', 'call', 'can', 'cannot', 'cant', 'co', 'con', 'could', 'couldnt', 'cry', 'de', 'describe', 'detail', 'do', 'done', 'down', 'due', 'during', 'each', 'eg', 'eight', 'either', 'eleven', 'else', 'elsewhere', 'empty', 'enough', 'etc', 'even', 'ever', 'every', 'everyone', 'everything', 'everywhere', 'except', 'few', 'fifteen', 'fify', 'fill', 'find', 'fire', 'first', 'five', 'for', 'former', 'formerly', 'forty', 'found', 'four', 'from', 'front', 'full', 'further', 'get', 'give', 'go', 'had', 'has', 'hasnt', 'have', 'he', 'hence', 'her', 'here', 'hereafter', 'hereby', 'herein', 'hereupon', 'hers', 'herself', 'him', 'himself', 'his', 'how', 'however', 'hundred', 'ie', 'if', 'in', 'inc', 'indeed', 'interest', 'into', 'is', 'it', 'its', 'itself', 'keep', 'last', 'latter', 'latterly', 'least', 'less', 'ltd', 'made', 'many', 'may', 'me', 'meanwhile', 'might', 'mill', 'mine', 'more', 'moreover', 'most', 'mostly', 'move', 'much', 'must', 'my', 'myself', 'name', 'namely', 'neither', 'never', 'nevertheless', 'next', 'nine', 'no', 'nobody', 'none', 'noone', 'nor', 'not', 'nothing', 'now', 'nowhere', 'of', 'off', 'often', 'on', 'once', 'one', 'only', 'onto', 'or', 'other', 'others', 'otherwise', 'our', 'ours', 'ourselves', 'out', 'over', 'own', 'part', 'per', 'perhaps', 'please', 'put', 'rather', 're', 'same', 'see', 'seem', 'seemed', 'seeming', 'seems', 'serious', 'several', 'she', 'should', 'show', 'side', 'since', 'sincere', 'six', 'sixty', 'so', 'some', 'somehow', 'someone', 'something', 'sometime', 'sometimes', 'somewhere', 'still', 'such', 'system', 'take', 'ten', 'than', 'that', 'the', 'their', 'them', 'themselves', 'then', 'thence', 'there', 'thereafter', 'thereby', 'therefore', 'therein', 'thereupon', 'these', 'they', 'thickv', 'thin', 'third', 'this', 'those', 'though', 'three', 'through', 'throughout', 'thru', 'thus', 'to', 'together', 'too', 'top', 'toward', 'towards', 'twelve', 'twenty', 'two', 'un', 'under', 'until', 'up', 'upon', 'us', 'very', 'via', 'was', 'we', 'well', 'were', 'what', 'whatever', 'when', 'whence', 'whenever', 'where', 'whereafter', 'whereas', 'whereby', 'wherein', 'whereupon', 'wherever', 'whether', 'which', 'while', 'whither', 'who', 'whoever', 'whole', 'whom', 'whose', 'why', 'will', 'with', 'within', 'without', 'would', 'yet', 'you', 'your', 'yours', 'yourself', 'yourselves', 'the']) import os import jieba import re import sys def word_index(text): words = word_split(text) words = words_cleanup(words) return words def word_split(text): word_list = [] pattern = re.compile(u'[u4e00-u9fa5]+')#提取中文,unicode编码u4e00-u9fa5的一个或者多个字符. jieba_list = list(jieba.cut(text)) time = {} for c in (jieba_list): if c in time: # record appear time time[c] += 1 else: time.setdefault(c, 0) #time第一次设为0是python自己语法这么定的, #text.index(c,t)返回text中c出现第t+1次的index.语法就是这么奇怪. #所以time里面写i表示这个单词出现i+1次, if pattern.search(c): # if Chinese word_list.append((len(word_list), (text.index(c, time[c]), c))) continue if c.isalnum(): # if English or number word_list.append((len(word_list), (text.index(c, time[c]), c.lower()))) # include normalize return word_list #先做单词的预处理,把上面分好的word_list给words_cleanup做筛选 def words_cleanup(words): #index 是单词在word_list中编号,offset是单词在text中下标,word就是单词. cleaned_words = [] for index, (offset, word) in words: # words-(word index for search,(letter offset for display,word)) if word in _STOP_WORDS: continue cleaned_words.append((index, (offset, word))) return cleaned_words def inverted_index(text): words = word_split(text) words = words_cleanup(words) inverted = {} for index, (offset, word) in words:#words就是洗完的数据. locations = inverted.setdefault(word, [])#把洗完的数据根据word重新归类.同一个word放一起 locations.append((index, offset)) return inverted #最后得到的就是倒查索引的结果这个字典.value是 第几个次,偏移量(text里面下标) a=inverted_index('路上看到就发了开始的路路路路路路路')#a是倒排索引的字典,下面给这个字典加几个功能.都很简单 #对倒排索引继续添加功能:这个功能是把旧的inverted倒排字典跟新的doc_index倒排字典做合并. #下面的方法就是继续加了一层索引是doc_id.这样倒排索引变成了 #key:word value:{doc_id1,....doc_idn} 然后每一个doc_idi对应一个列表 #列表中每一项是(index,offset) 这样就做成了一个完善的多文件系统中找关键字的位置的倒排索引 #使用的时候只需要从inverted={},用inverted_index_add往里面加即可. def inverted_index_add(inverted, doc_id, doc_index): for word, locations in doc_index.items(): indices = inverted.setdefault(word, {}) indices[doc_id] = locations return inverted from functools import reduce def search(inverted, query): word = [word for _ , (offset, word) in word_index(query) if word in inverted][0] doc_set=inverted[word].keys() #doc_set 得到的是所有含query这个单词的文件编号. output=[] if doc_set: for doc in doc_set:#遍历所有的有效文档 for a in inverted[word][doc]: #打印一点word左边的字符和右边的字符 output.append((doc,a[0],word)) return output inverted={} doc_index = inverted_index('我我的我的是我的我的') a=inverted_index_add(inverted, 1, doc_index) doc_index = inverted_index('我想和我女朋友一起去我的北京故宫博物院参观我的屋子和闲逛') b=inverted_index_add(inverted, 2, doc_index) print(inverted) print(search(inverted,'我')) #结果:[(1, 0, '我'), (1, 1, '我'), (1, 3, '我'), (1, 6, '我'), (1, 8, '我'), (2, 0, '我'), (2, 3, '我'), (2, 7, '我'), (2, 11, '我')] #表示第一个文章第0个字符是我...............这样就做到了搜索引擎.给一个字或者词,他会返回他 #所在的哪篇文章中的第几个字符. #具体还需要加入搜索结果的优先级.这样优先级高的写在前面给用户看.简单排序即可.实现.