【spark API 函数讲解 详细 】https://www.iteblog.com/archives/1399#reduceByKey
[重要API接口,全面 】 http://spark.apache.org/docs/1.1.1/api/python/pyspark.rdd.RDD-class.html
********
[广播变量】 http://www.csdn.net/article/1970-01-01/2824552
调用广播变量通过:a.value,广播变量可以用在定义的函数的内部。
lt15=sc.broadcast(lt13.collect())
def matrix(p):
temp1=[p[0],p[1]]
for i in lt15.value:
if i in p[2]:
temp1.append(1)
else:
temp1.append(0)
return temp1
spark-submit --master yarn-cluster --executor-memory 5g --num-executors 50 特征工程最终版本.py
#下面这种方法尚未试过
spark-submit --name ${mainClassName} --driver-memory ${driverMemory} --conf spark.akka.frameSize=100
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
--num-executors ${numExecutors} --executor-memory ${executorMemory} --master yarn-cluster ${jarPath}
#提交sql脚本
./bin/spark-sql --master yarn --num-executors 3 --executor-memory 15g --executor-cores 4 -f /home/etl/script/gailunlfile/user_keep_info.sql
0、官方文档:http://spark.apache.org/docs/latest/ml-guide.html
1、http://itindex.net/detail/52732-spark-编程-笔记
spark RDD格式数据集转换:http://blog.csdn.net/chenjieit619/article/details/52861940
对RDD操作的各接口解释: http://www.360doc.com/content/16/0819/12/16883405_584310256.shtml
[Spark与Pandas中DataFrame的详细对比] http://blog.csdn.net/bitcarmanlee/article/details/52002225
1、在hadoop 中输入 pyspark 进入python开发环境;输入spark-shell 进去scala编程环境
2、scala> val r2=sc.textFile("1.txt") 把源数据转换为RDD格式
r2.first() 查看第一条数据
r2.take(5) 查看前5条数据
3、
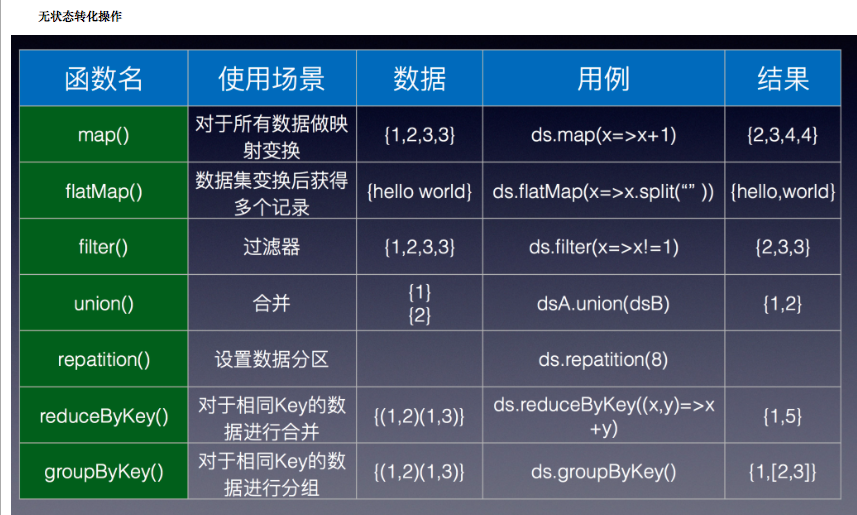
4、spark 从labelPoint数据中筛选出符合标签值得数据组合成新的labelpoint数据
==============================
def parsePoint(line): #把rdd数据转换成Labelpoint 格式数据
values=[float(x) for x in line.split(' ')]
return LabeledPoint(values[0],values[1:])
================================
def filterPoint(p): #筛选labelpoint数据,符合条件的留下,不符合条件的删除,返回一个新的labelpoint数据
if(p.label == 0):
return LabeledPoint(p.label,p.features)
else:
None
===================================
data1=sc.textFile('hdfs://getui-bi-hadoop/user/zhujx/1029_IOS_features_sex')
parsedata=data1.map(parsePoint) #调用函数,将数据转化为LabeledPoint 格式
bb=parsedata.filter(filterPoint) #调用函数,筛选出符合条件的数据,返回的还是labelpoint格式数据,不符合的数据已经被删掉了
数据集bb就可以带入模型了
===================================
抽样语句:
splitdata=parsedata.randomSplit((0.8,0.2))
traindata=splitdata[0]
testdata=splitdata[1]
********************************
下面是在python中对RDD的生成,以及一些基本的Transformation,Action操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
# -*- coding:utf-8 -*-from pyspark import SparkContext, SparkConffrom pyspark.streaming import StreamingContextimport mathappName ="jhl_spark_1" #你的应用程序名称master= "local"#设置单机conf = SparkConf().setAppName(appName).setMaster(master)#配置SparkContextsc = SparkContext(conf=conf)# parallelize:并行化数据,转化为RDDdata = [1, 2, 3, 4, 5]distData = sc.parallelize(data, numSlices=10) # numSlices为分块数目,根据集群数进行分块# textFile读取外部数据rdd = sc.textFile("./c2.txt") # 以行为单位读取外部文件,并转化为RDDprint rdd.collect()# map:迭代,对数据集中数据进行单独操作def my_add(l): return (l,l)data = [1, 2, 3, 4, 5]distData = sc.parallelize(data) # 并行化数据集result = distData.map(my_add)print (result.collect()) # 返回一个分布数据集# filter:过滤数据def my_add(l): result = False if l > 2: result = True return resultdata = [1, 2, 3, 4, 5]distData = sc.parallelize(data)#并行化数据集,分片result = distData.filter(my_add)print (result.collect())#返回一个分布数据集# zip:将两个RDD对应元素组合为元组x = sc.parallelize(range(0,5))y = sc.parallelize(range(1000, 1005))print x.zip(y).collect()#union 组合两个RDDprint x.union(x).collect()# Aciton操作# collect:返回RDD中的数据rdd = sc.parallelize(range(1, 10))print rddprint rdd.collect()# collectAsMap:以rdd元素为元组,以元组中一个元素作为索引返回RDD中的数据m = sc.parallelize([('a', 2), (3, 4)]).collectAsMap()print m['a']print m[3]# groupby函数:根据提供的方法为RDD分组:rdd = sc.parallelize([1, 1, 2, 3, 5, 8])def fun(i): return i % 2result = rdd.groupBy(fun).collect()print [(x, sorted(y)) for (x, y) in result]# reduce:对数据集进行运算rdd = sc.parallelize(range(1, 10))result = rdd.reduce(lambda a, b: a + b)print result |
除上述以外,对RDD还存在一些常见数据操作如:
name()返回rdd的名称
min()返回rdd中的最小值
sum()叠加rdd中所有元素
take(n)取rdd中前n个元素
count()返回rdd的元素个数