中文分词器
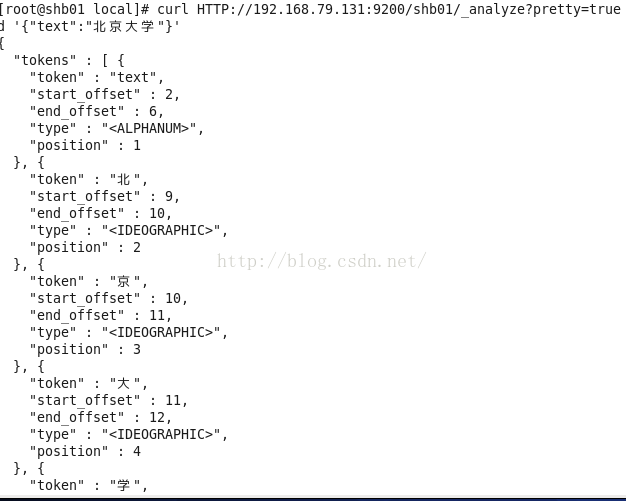
在lunix下执行下列命令,可以看到本来应该按照中文”北京大学”来查询结果es将其分拆为”北”,”京”,”大”,”学”四个汉字,这显然不符合我的预期。这是因为Es默认的是英文分词器我需要为其配置中文分词器。
curlHTTP://192.168.79.131:9200/shb01/_analyze?pretty=true -d'{"text":"北京大学"}'
Es整合ik不直接用ik官网的工具包,需要将ik工具包封装成es插件才行,这个已经有人封装好了可以在github上下载elasticsearch-analysis-ik
1:在github上下载ik插件源码
https://github.com/medcl/elasticsearch-analysis-ik
2:下载后解压缩在根目录下使用maven对其进行编译。
编译后把target/release目录下的elasticsearch-analysis-ik-1.3.0.zip上传到/usr/local/elasticsearch-1.4.4/plugins/analysis-ik目录下然后使用unzip解压。
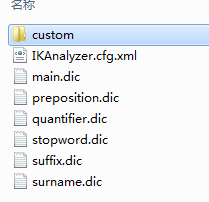
把下载的ik插件中config目录下的文件拷贝到/usr/local/elasticsearch-1.4.4/config目录下,这些文件时ik的配置文件,custom是自定义词库文件。
3:修改elasticsearch.yml文件,把ik分词器设置为es的默认分词器
index.analysis.analyzer.default.type:ik
4:重启es,注意es中的每个节点都要进行上述配置。
自定义分词器
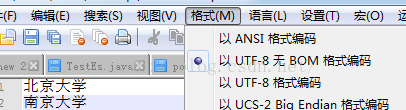
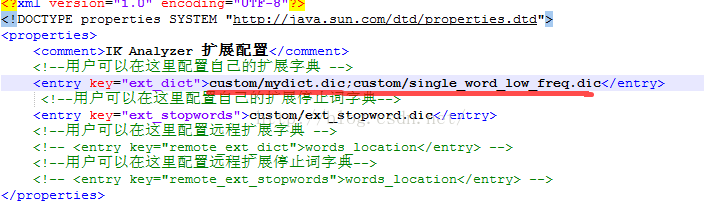
1:创建一个dic文件,编码格式必须为utf-8无BOM格式,每个词一行多个词需要换行。
2:将自定义的dic文件上传到/usr/local/elasticsearch-1.4.4/config/custom目录下
3:修改ik的配置文件/usr/local/elasticsearch-1.4.4/config/IKAnalyzer.cfg.xml,在其中指定自定义的dic文件。
4:重启es