上节回顾
在第一篇博文(Hadoop入坑之路(一))中,讲述了HDFS如何在服务器上搭建以及命令行客户端的一些基本命令的用法。这一节中主要讲在Java客户端上,实现Windows与HDFS服务器的数据的交互。
客户端与HDFS的数据交互
在运行Java客户端时,需要从官网上下载hadoop的源码包进行编译为windows版本的安装包,并且需要将Hadoop添加到系统环境变量中。
启动Eclipse,新建一个Java项目,添加lib文件。将目录/share/hadoop/common、/share/common/lib、/share/hadoop/hdfs/lib以及/share/hadoop/hdfs下的jar包添加到Java项目的lib文件夹中,并添加到调试环境中。
上传文件到HDFS:
public class HdfsClient { public static void main(String[] args) throws IOException, InterruptedException, URISyntaxException { /** * configuration参数对象的机制: * 构造时,会先加载jar包中的默认配置 xx-default.xml * 再加载用户配置xx-default.xml,覆盖掉默认参数 * * 构造完成后,还可以conf.set("p", "n"),会再次覆盖用户配置文件中的参数值 */ //new Configuration()会从项目的classpath中自动加载core-defult.xml hdfs-defult.xml hdfs-site.xml等文件 Configuration conf = new Configuration(); //指定本客户端上传文件到hdfs时需要保存的副本为:2 conf.set("dfs.replication", "2"); //指定本客户端上传文件到hdfs时切块的规格大小:64M conf.set("dfs.blocksize", "64m"); //构造一个访问指定HDFS系统的客户端对象:参数1:HDFS系统的URI,参数2:客户端指定的参数,参数3:客户身份(用户名) FileSystem fs = FileSystem.get(new URI("hdfs://222.18.157.50:9000/"), conf, "root"); //上传一个文件到hdfs中 fs.copyFromLocalFile(new Path("C:\xxx\xx\xx\xxxx.txt"), new Path("/")); fs.close(); } }
从HDFS下载文件:
public class HdfsClient { FileSystem fs = null; @Before public void init() throws IOException, InterruptedException, URISyntaxException { //new Configuration()会从项目的classpath中自动加载core-defult.xml hdfs-defult.xml hdfs-site.xml等文件 Configuration conf = new Configuration(); //指定本客户端上传文件到hdfs时需要保存的副本为:2 conf.set("dfs.replication", "2"); //指定本客户端上传文件到hdfs时切块的规格大小:64M conf.set("dfs.blocksize", "64m"); //构造一个访问指定HDFS系统的客户端对象:参数1:HDFS系统的URI,参数2:客户端指定的参数,参数3:客户身份(用户名) fs = FileSystem.get(new URI("hdfs://222.18.157.50:9000/"), conf, "root"); } /** * 从HDFS中下载文件到本地磁盘 * @throws Exception * @throws IllegalArgumentException */ @Test public void testGet() throws IllegalArgumentException, Exception { fs.copyToLocalFile(new Path("/xxx.txt"), new Path("F:\")); fs.close(); } }
在HDFS内部移动(修改)文件名称
/** * 在HDFS内部移动(修改)文件名称 * @throws IOException * @throws IllegalArgumentException */ @Test public void testRename() throws Exception { fs.rename(new Path("/office激活.txt"), new Path("/install.log")); fs.close(); }
在HDFS中创建文件夹
/** * 在HDFS中创建文件夹 * @throws IOException * @throws IllegalArgumentException */ @Test public void testMkdir() throws IllegalArgumentException, IOException { fs.mkdirs(new Path("/client/java")); fs.mkdirs(new Path("/client/command")); fs.close(); }
在HDFS中删除文件或文件夹
/** * 在HDFS中删除文件或文件夹 * @throws IOException * @throws IllegalArgumentException */ @Test public void testRm() throws IllegalArgumentException, IOException { fs.delete(new Path("/install.log"), false); fs.close(); }
查询HDFS中制定目录下的文件信息
/** * 查询HDFS指定目录下的文件信息 * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testLs() throws FileNotFoundException, IllegalArgumentException, IOException { // 只查询文件信息,不返回文件夹信息 RemoteIterator<LocatedFileStatus> iter = fs.listFiles(new Path("/client/java"), true); while(iter.hasNext()) { LocatedFileStatus status = iter.next(); System.out.println("文件全路径:" + status.getPath()); System.out.println("块大小:" + status.getBlockSize()); System.out.println("文件长度:" + status.getLen()); System.out.println("副本数量:" + status.getReplication()); System.out.println("快信息:" + Arrays.toString(status.getBlockLocations())); System.out.println("所属用户:" + status.getOwner()); System.out.println("========华==丽==的==分==割==线========"); } fs.close(); }
查询HDFS中指定目录下的文件和文件夹信息
/** * 查询HDFS指定目录下的文件和文件夹信息 * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testLs2() throws FileNotFoundException, IllegalArgumentException, IOException { FileStatus[] liststatus = fs.listStatus(new Path("/client/")); for(FileStatus status : liststatus) { System.out.println("文件全路径:" + status.getPath()); System.out.println(status.isDirectory() ? "这是文件夹" : "这是文件"); System.out.println("块大小:" + status.getBlockSize()); System.out.println("文件长度:" + status.getLen()); System.out.println("副本数量:" + status.getReplication()); System.out.println("========华==丽==的==分==割==线========"); } fs.close(); }
读取HDFS中文件内容
/** * 读取HDFS中的文件内容 * @throws IOException * @throws IllegalArgumentException */ @Test public void testReadData() throws IllegalArgumentException, IOException { FSDataInputStream in =fs.open(new Path("/doc/HadoopReadMe.txt")); BufferedReader br = new BufferedReader(new InputStreamReader(in)); String line = null; while((line = br.readLine()) != null) { System.out.println(line); } br.close(); in.close(); fs.close(); }
读取HDFS中指定偏移量范围的内容
/** * 读取HDFS中文件指定偏移量范围的内容 * @throws IOException * @throws IllegalArgumentException */ @Test public void testRandomReadData() throws IllegalArgumentException, IOException { FSDataInputStream in = fs.open(new Path("/doc/HadoopReadMe.txt")); // 指定读取的起始位置 in.seek(32); // 指定读取长度:读取64个字节 byte[] buf =new byte[64]; in.read(buf); System.out.println(new String(buf)); in.close(); fs.close(); }
往HDFS中写文件内容
/** * 往HDFS中的文件写数据 * @throws IOException * @throws IllegalArgumentException */ @Test public void testWriteData() throws IllegalArgumentException, IOException { FSDataOutputStream out = fs.create(new Path("/client/java/testPic.jpg")); FileInputStream in =new FileInputStream("C:\xxx\xx\Desktop\xxxx\xxxx\xxxx.png"); byte[] buf = new byte[1024]; int read = 0; while((read = in.read(buf)) != -1) { out.write(buf, 0, read); } in.close(); out.close(); fs.close(); }
将Hadoop项目提交到集群
Mapreduce框架,以 Wordcount 为例:
第一步:创建 Mapper 类:
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; /** * KEYIN: 是map task 读取到的数据的key的类型,是一行的起始偏移量Long * VALUEIN: 是map task 读取到的数据的value的类型,是一行的内容String * * KEYOUT: 是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,返回的是单词String * VALUEOUT: 是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,返回的是整数Integer * * - 在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的序列化机制产生的数据量比较冗余, * - 就会导致数据在mapreduce运行过程中传输效率低,所以hadoop专门设计了自己的序列化机制,那么mapreduce中传输的数据类型就必须实现Hadoop自己的接口 * * Hadoop为jdk中的基本类型Long, String, Integer, Float等数据类型封装了自己的序列化机制 * - 接口类型:LongWritable, Text, IntWritable, FloatWritable * * @author ZhangChao * */ public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { // cut words String[] words = value.toString().split(" "); for (String word : words) { context.write(new Text(word), new IntWritable()); } } }
第二步:创建 Reducer 类:
import java.io.IOException; import java.util.Iterator; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WordcountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int count = 0; Iterator<IntWritable> iterator = values.iterator(); while(iterator.hasNext()) { IntWritable value = iterator.next(); count += value.get(); } context.write(key, new IntWritable(count)); } }
第三步:将项目提交到 Hadoop 集群
方式一:将项目提交到 Linux 上:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 如果要在Hadoop集群的某台机器上启动这个job提交的客户端的话, * conf里面就不需要指定fs.defaultFS mapreduce.framework.name * * 因为在集群机器中,用hadoop jar xxx.jar xx.xx.xx.MainClass 命令来启动客户端main方法时, * hadoop jar这个命令会将所在机器上的hadoop安装目录中的jar包和配置文件加载到运行时的classpath中, * 那么,我们的客户端main方法中的 new Configuration() 语句就会加载classpath中的配置文件,自然就 * 会有了 fs.defaultFS 、 mapreduce.framework.name 和 yarn.resourcemanager.hostname 这些参数配置。 * * @author ZhangChao * */ public class JobSubmitLinux { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(JobSubmitLinux.class); job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); job.setNumReduceTasks(3); boolean res = job.waitForCompletion(true); System.out.println(res); System.exit(res?0:1); } }
方式二:提交到Windows本地:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class JobSubmiterWindowsLocal { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "file:///"); conf.set("mapreduce.framework.name", "local"); Job job = Job.getInstance(conf); job.setJarByClass(JobSubmitLinux.class); job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReduce.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path output = new Path("f:/mrdata/wordcount/output"); FileSystem fs = FileSystem.get(conf); if(fs.exists(output)) { fs.delete(output, true); } FileInputFormat.setInputPaths(job, new Path("f:/mrdata/wordcount/input")); FileOutputFormat.setOutputPath(job, output); job.setNumReduceTasks(3); boolean res = job.waitForCompletion(true); System.out.println(res); System.exit(res?0:1); } }
方式三:
import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * - 用于提交mapreduce job的客户端程序 * - 功能: * - 1. 封装本次job运行时所需要的必要参数 * - 2. 与yarn进行交互,将mapreduce程序成功的启动、运行 * @author ZhangChao * */ public class JobSubmit { public static void main(String[] args) throws Exception { // 0.在代码中设置JVM系统参数,用于给job对象来获取访问HDFS的用户身份 System.setProperty("HADOOP_USER_NAME", "root"); Configuration conf = new Configuration(); // 1.设置job运行时需要访问的默认系统文件 conf.set("fs.defaultFS", "hdfs://hdp-master:9000"); // 2.设置提交到哪儿去运行 conf.set("mapreduce.framework.name", "yarn"); conf.set("yarn.resourcemanager.hostname", "hdp-master"); conf.set("mapreduce.app-submission.cross-platform","true"); Job job = Job.getInstance(conf); // 1.封装参数:jar包所在的位置 // job.setJar("f:/wc.jar"); job.setJarByClass(JobSubmit.class); // 2.封装参数:本次job索要调动的mapper,reducer实现类 job.setMapperClass(WordcountMapper.class); job.setReducerClass(WordcountReduce.class); // 3.封装参数:本次job的mapper, reducer实现类产生的结果数据的key, value类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 4.封装参数:本次job要处理的输入数据集所在路径、最终结果的输出路径 Path output = new Path("/wordcount/output"); FileSystem fs = FileSystem.get(new URI("hdfs:222.18.157.50"), conf, "root"); if(fs.exists(output)) { fs.delete(output, true); } FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); FileOutputFormat.setOutputPath(job, output);// 注意:输出路径必须不存在 // 5.封装参数:想要启动reduce task的数量 job.setNumReduceTasks(2); // 6.提交job给yarn boolean res = job.waitForCompletion(true); System.out.println(res); } }
本地运行Hadoop项目
由于将本地创建的 Mapreduce 项目每次都需要提交到集群上才能运行,此步骤较为的繁琐,且不便于项目的调试。因此可以在 Windows 本地安装 Hadoop,这样就可以避免每次运行项目都需要提交到集群的繁琐步骤。
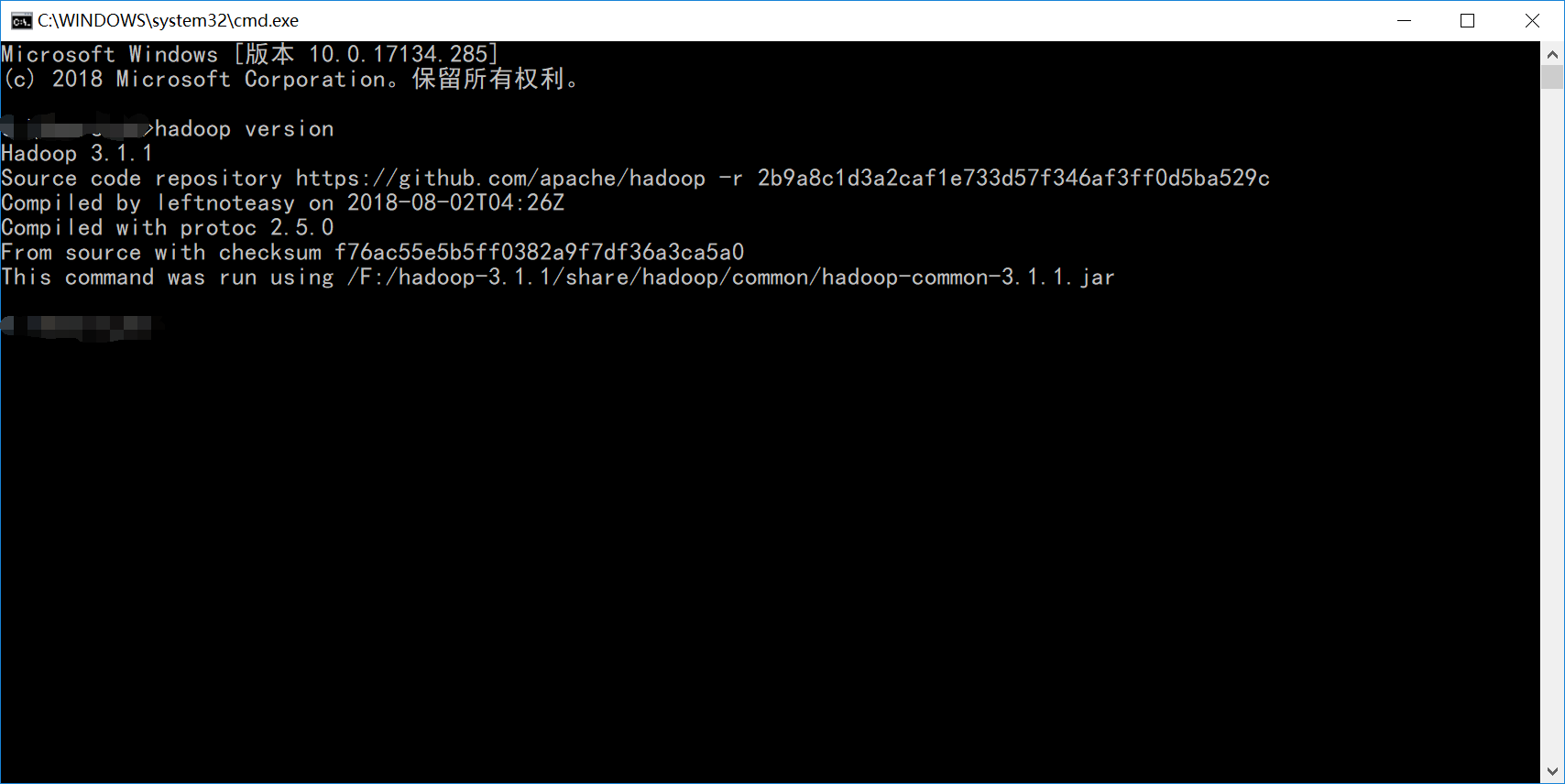
下载 Hadoop 安装包,并配置到系统环境变量中。输入 hadoop version 命令测试 hadoop 安装是否成功。
将安装的 $HADOOP_HOME/bin 文件夹替换为 Windows 下编译好的文件夹。(安装的版本是hadoop3.1.1,将bin文件夹替换为3.1.1版本的即可,点击获取3.1.1版本的 bin 文件)。具体暗转hadoop步骤见博客https://blog.csdn.net/songhaifengshuaige/article/details/79575308
测试项目
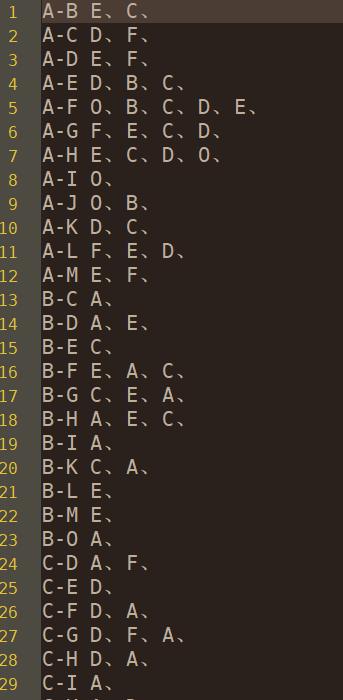
寻找共同好友,源数据如图所示。为了实现寻找共同好友的目的,可以分为两步走:

第一步:将好友作为 key,用户作为 value。根据mapreduce的数据分发机制以及处理按照“好友-用户”的格式,将数据进行第一步处理。
package mr.friends; import java.io.IOException; import java.util.ArrayList; import java.util.Collections; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class CommonFirendsOne { public static class CommonFirendsOneMapper extends Mapper<LongWritable, Text, Text, Text> { Text k = new Text(); Text v = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { String[] userAndFirends = value.toString().split(":"); String user = userAndFirends[0]; v.set(user); String[] firends = userAndFirends[1].split(","); for (String f : firends) { k.set(f); context.write(k, v); } } } public static class CommonFriendsOneReducer extends Reducer<Text, Text, Text, Text> { Text k = new Text(); @Override protected void reduce(Text friend, Iterable<Text> users, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { ArrayList<String> userList = new ArrayList<String>(); for (Text user : users) { userList.add(user.toString()); } Collections.sort(userList); for (int i = 0; i < userList.size() - 1; ++i) { for (int j = i + 1; j < userList.size(); ++j) { k.set(userList.get(i) + "-" + userList.get(j)); context.write(k, friend); } } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(CommonFirendsOne.class); job.setMapperClass(CommonFirendsOneMapper.class); job.setReducerClass(CommonFriendsOneReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); Path output = new Path("f:\mrdata\friends\step1-output"); FileSystem fs = FileSystem.get(conf); if (fs.exists(output)) { fs.delete(output, true); } FileInputFormat.setInputPaths(job, new Path("f:\mrdata\friends\input")); FileOutputFormat.setOutputPath(job, output); boolean res = job.waitForCompletion(true); System.out.println(res); } }
第二步:完成共同好友统计
package mr.friends; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class CommonFriendsTwo { public static class CommonFriendsTwoMapper extends Mapper<LongWritable, Text, Text, Text> { Text k = new Text(); Text v = new Text(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { String[] split = value.toString().split(" "); k.set(split[0]); v.set(split[1]); context.write(k, v); } } public static class CommonFriendsTwoReducer extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> value, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { StringBuilder sb = new StringBuilder(); for (Text v : value) { sb.append(v.toString()).append("、"); } context.write(key, new Text(sb.toString())); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(CommonFriendsTwo.class); job.setMapperClass(CommonFriendsTwoMapper.class); job.setReducerClass(CommonFriendsTwoReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); Path output = new Path("f:\mrdata\friends\step2-output"); FileSystem fs = FileSystem.get(conf); if (fs.exists(output)) { fs.delete(output, true); } FileInputFormat.setInputPaths(job, new Path("f:\mrdata\friends\step1-output")); FileOutputFormat.setOutputPath(job, output); boolean res = job.waitForCompletion(true); System.out.println(res); } }
结果如图所示: