索引以及算法
1、简介
InnoDB存储引擎支持一下几种索引:
- B+树索引
- 全文索引
- 哈希索引
B+树就是常规意义的索引,不是二叉树,而是balance树。B+索引常常被误解的是,通过B+索引只能找到被查找数据所在的数据页。然后在内存中查找对应的数据。
2、数据结构和算法
2.1、二分查找法

数据页中就是按照二分查找来进行具体数据的查找。
3.1、B+树结构
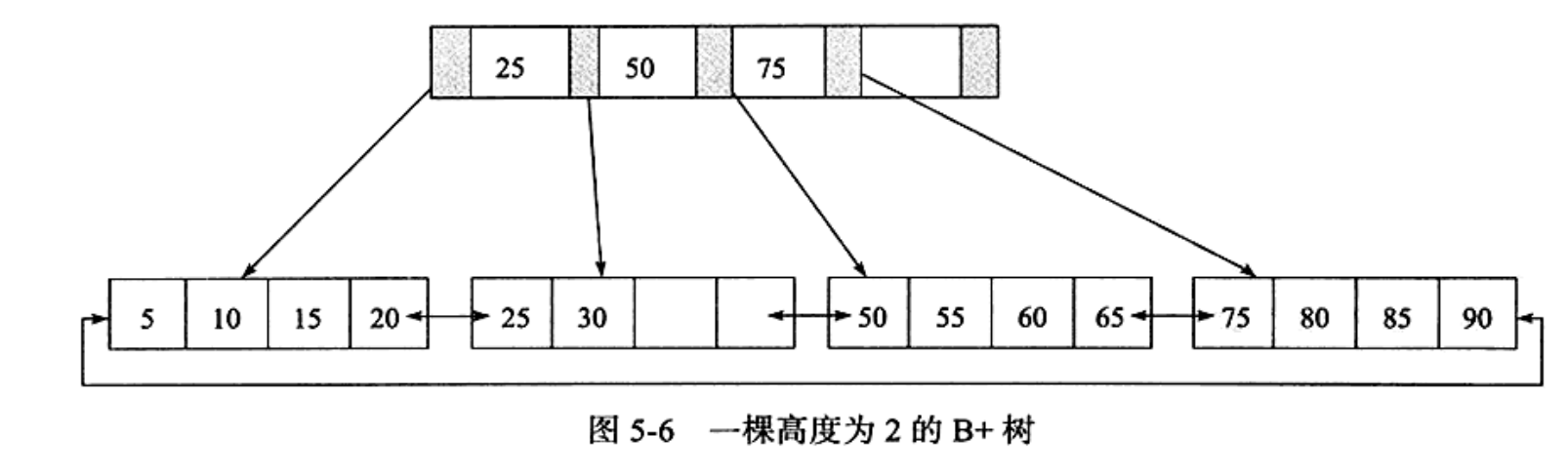
三种插入方式

例子展示三种插入方式:
插入28,leaf page、index page都没有满,直接插入即可
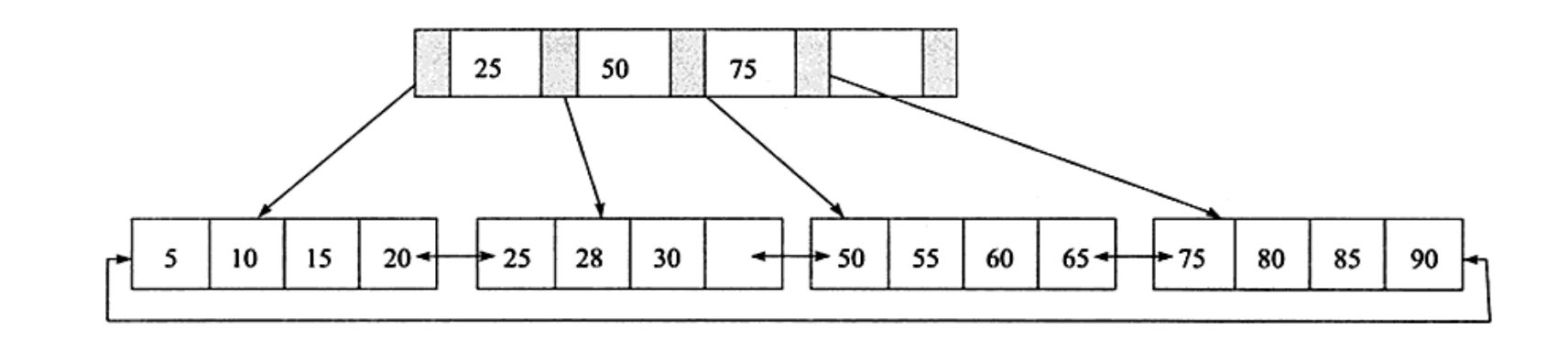
插入70这个元素,leaf page满了,index page没有满。
插入leaf page的情况应该为 50、55、80、65、70,中间元素为60,将60放入大index page

然后插入95,这个时候leaf page和index page都满了,这个时候满足第三种情况。
首先leaf page变成:75、80、85、90、95,中间元素为85,将85放到index page,leaf page变成 【75、80】、【85、90、95】
index page变成:25、50、60、75、85,中间元素为60,将index page拆分为【25、50】、【75、85】
3.2 B+树索引分类
- 聚集索引:叶子节点存放一整行数据
- 辅助索引:方便提高查询效率的索引
聚集索引只能有一个,查询优化器多数情况采用聚集索引
3.2.2 辅助索引
辅助索引也叫做非聚集索引
是不是应该加某个字段的非聚集索引
区分度越大越应该加索引,如果所有记录某个字段只有几个值,加索引的意义就很低。
具体的公式
show index from t_opp_info;
查看表中索引的情况,关键关注cardinality

公式为var = cardinality/总记录数量,var越接近1,索引的作用越大。
3.2.3 联合索引的用法
index a,bc
index a
select * from t where a = ''会使用索引a
select * from t where a= '' and b = '' 会使用索引abc
select * from t where a= '' and b = '' and c= '' 会使用索引abc
select * from t where a= '' order by b 会使用索引abc
select * from t where a= '' order by b,c 会使用索引abc
select * from t where a= '' order by c 不是使用索引
因为索引abc会把数据按照abc的方式去排序
3.2.4 覆盖索引
覆盖索引指的是引擎不需要回聚集索引去查全部数据,仅仅在索引的二叉树上就可以查出来需要的数据,不需要回表。
3.2.5 索引不生效的情况
3.2.6 哈希算法
适合那些热数据,不可能把全表都放到缓存中。
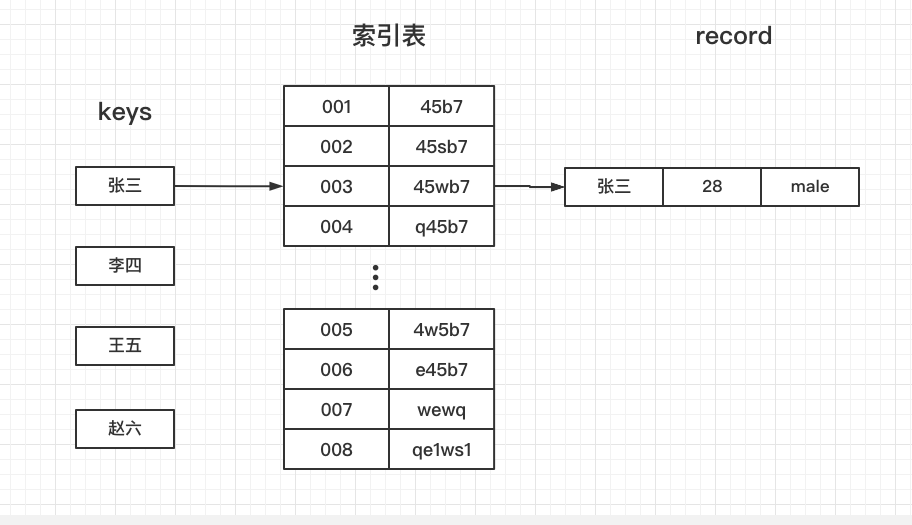
select * from t where name = '张三'
hash(‘张三’)=003,然后从索引表的开始遍历,3次后找到hash相等的,hash值后面跟着记录所在的位置。但是该位置上可能有多条数据,这个时候遍历查找符合的元素。