import lxml.etree as etree
# 1). 将html内容转化成xpath可以解析/匹配的格式;
#html = """
#<!DOCTYPE html>
#<html>
#<head lang="en">......
selector = etree.HTML(html)
str = selector.xpath('//div[@id="content"]/ul[@id="ul"]/li/text()')
# 全文里搜索div标签-->筛选id = content的所有div标签--->再筛选出ul标签里id='ul'的标签---->li标签--->提取文字
# 输出的str为列表
print(str)
print(type(str)) # str为列表类型
根据文本匹配
pyquery
# pyquery 根据包含的字符定位所属标签
doc("script:contains(美丽心情19840606)")
>>> [<script>]
xpath
# 等于值
//a[text()="文本"]
# 模糊匹配
//a[contains(text(),"文本")]
# 根据属性值匹配
<a class="tb-gold-icon" title="金牌卖家" href="//www.taobao.com/go/act/jpmj.php" target="_blank"></a>
//a[contains(@title, "金牌卖家")]
xpath兄弟节点 引用链接

/following-sibling::*[1] 选择到了第一个元素后,再指定选取兄弟节点【第几个兄弟节点】
WebDriverWait(i,10).until(EC.presence_of_element_located((By.XPATH,'//span[contains(text(),"状态:")]/following-sibling::*[1]'))).text
查找兄弟标签
# 定位同级的下一个a标签
//a[text()="文本"]/following-sibling::a[1]
# 定位同级的上一个a标签
//a[text()="文本"]/preceding-sibling::a[1]
# 定位当前节点的父节点
//a[text()="文本"]/..
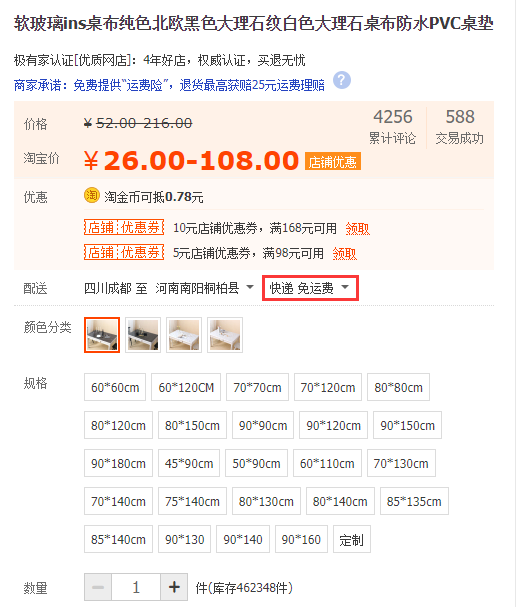
使用方法
根据文本匹配
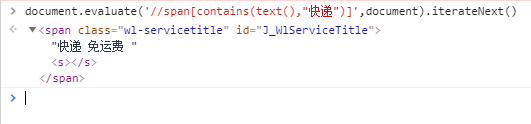
document.evaluate('//span[contains(text(),"快递")]',document).iterateNext()
根据属性class匹配
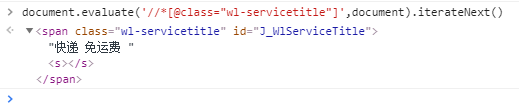
document.evaluate('//*[@class="wl-servicetitle"]',document).iterateNext()
根据属性ID匹配

document.evaluate('//*[@id="J_WlServiceTitle"]',document).iterateNext()
定位同级的下一个a标签

document.evaluate('//span[contains(text(),"浙江")]/following-sibling::span[1]',document).iterateNext()
定位当前节点的父节点

document.evaluate('//span[contains(text(),"快递")]//../../..',document).iterateNext()
query选择器和xpath合用
>>> type(doc('#J_RateCounter')[0].xpath('//span')[0])
>>> <class 'lxml.html.HtmlElement'>

query选择器根据属性A获取节点属性B的值

1、#先定位到父节点,再从父节点找指定节点
例如: 注意不能直接用
driver.find_element_by_xpath('//*[@id="branch_inquiry"]').find_element_by_class_name('city-picker-span')
用法
-
-
from selenium import webdriver
-
from selenium.webdriver.common.by import By
-
from selenium.webdriver.common.keys import Keys
-
from selenium.webdriver.support.ui import Select
-
from selenium.common.exceptions import NoSuchElementException
-
from selenium.common.exceptions import NoAlertPresentException
-
import unittest, time, re
-
-
driver = webdriver.Chrome()
-
driver.get("http://intl.sit.sf-express.com:8980/")
-
from selenium.webdriver import ActionChains
-
-
driver.find_element_by_xpath('/html/body/div[3]/div[2]/a[5]').click()
-
-
service_coverage = driver.find_element_by_xpath('//*[@id="range_inquiry"]').find_element_by_class_name('city-picker-span')
-
print(service_coverage.text)
-
2、不是同一级的xpath 定位方法
driver.find_element_by_xpath("//input[@id='cityAddress1']/following-sibling::span").click()
3、由父节点定位子节点
-
-
print driver.find_element_by_id('B').find_element_by_tag_name('div').text
-
-
-
print driver.find_element_by_xpath("//div[@id='B']/div").text
-
-
-
print driver.find_element_by_css_selector('div#B>div').text
-
-
-
print driver.find_element_by_css_selector('div#B div:nth-child(1)').text
-
-
-
print driver.find_element_by_css_selector('div#B div:nth-of-type(1)').text
-
-
-
print driver.find_element_by_xpath("//div[@id='B']/child::div").text
4、由子节点定位父节点
-
-
print driver.find_element_by_xpath("//div[@id='C']/../..").text
-
-
print driver.find_element_by_xpath("//div[@id='C']/parent::*/parent::div").text
5、由弟弟节点定位哥哥节点
-
-
print driver.find_element_by_xpath("//div[@id='D']/../div[1]").text
-
-
print driver.find_element_by_xpath("//div[@id='D']/preceding-sibling::div[1]").text
6、由哥哥节点定位弟弟节点
-
-
print driver.find_element_by_xpath("//div[@id='D']/../div[3]").text
-
-
print driver.find_element_by_xpath("//div[@id='D']/following-sibling::div[1]").text
-
-
print driver.find_element_by_xpath("//div[@id='D']/following::*").text
-
-
print driver.find_element_by_css_selector('div#D + div').text
-
-
print driver.find_element_by_css_selector('div#D ~ div').text
7、其他Xapth定位方法
-
第一种方法:通过绝对路径做定位(相信大家不会使用这种方式)
-
By.xpath("html/body/div/form/input")
-
-
-
-
第四种方法:使用xpath属性定位(结合第2、第3中方法可以使用)
-
By.xpath("//input[@id='kw1']")
-
By.xpath("//input[@type='name' and @name='kw1']")
-
-
By.xpath("//input[start-with(@id,'nice')
-
By.xpath("//input[ends-with(@id,'很漂亮')
-
By.xpath("//input[contains(@id,'那么美')]")
-