问题描述:项目中导出execl数据量非常大,导致了页面长时间得不到响应而崩溃掉了,所以导出execl失败!
处理方案:前端采用定时刷新+进度条方式,后端导出采用缓存线程实现导出,导出改用每次请求后端直接返回进度条数值,开启一个线程让它去执行查询与导出操作。当导出执行完成将进度条写成100返回给前端,前端判断100后关闭进度条加载后端一个下载接口,将数据写出到浏览器
代码参考:

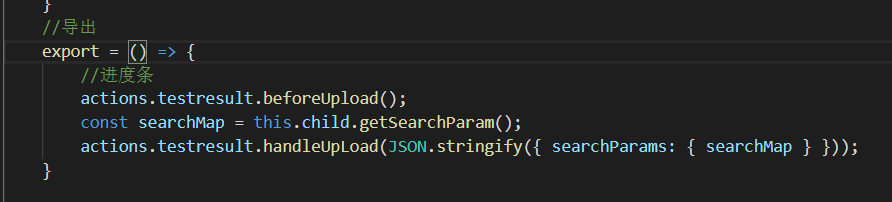
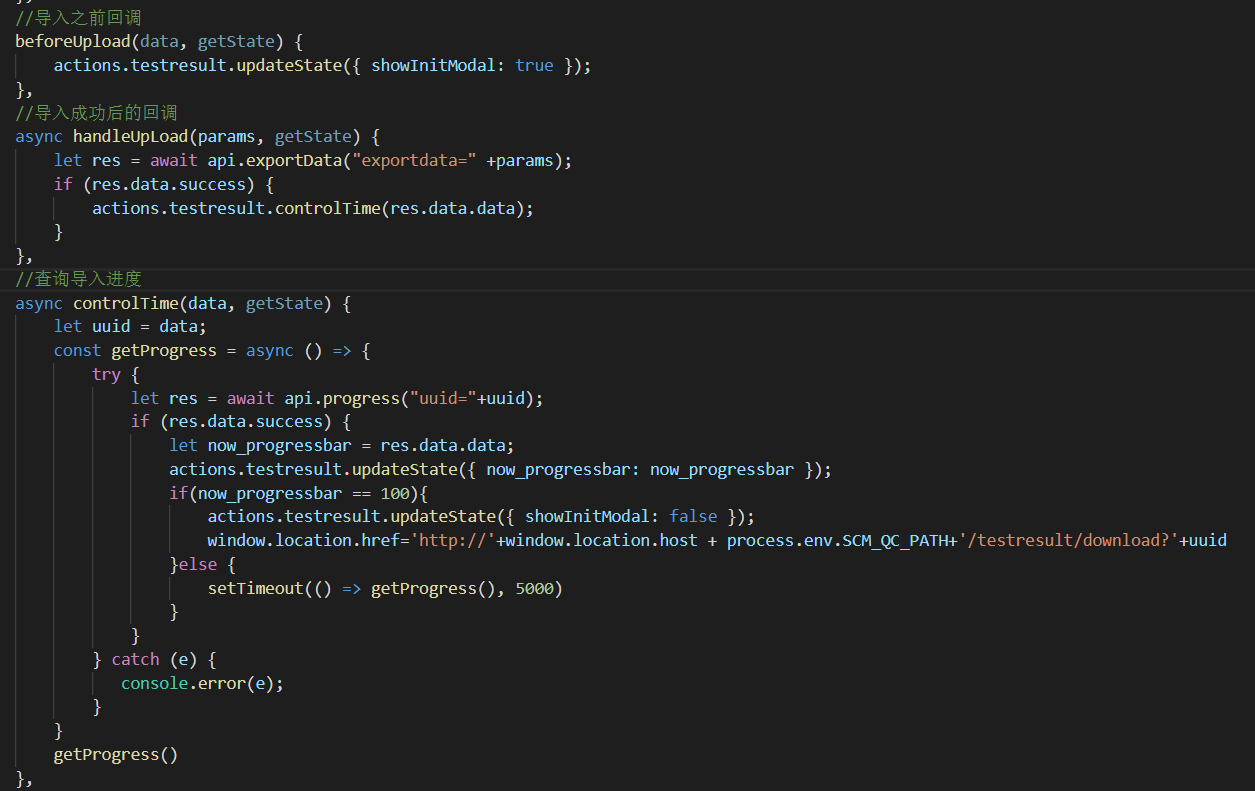
后端代码参考:
/**
* 获取进度查询
*
* @param uuid
* @return
*/
@RequestMapping(value = "/progress", method = RequestMethod.POST)
public @ResponseBody Result progress(@RequestParam String uuid) {
Result result = new Result();
result.setData(cacheManager.get(uuid));
result.setSuccess(true);
return result;
}
/**
* 获取进度查询
*
* @param uuid
* @return
*/
@RequestMapping(value = "/progress", method = RequestMethod.POST)
public @ResponseBody Result progress(@RequestParam String uuid) {
Result result = new Result();
result.setData(cacheManager.get(uuid));
result.setSuccess(true);
return result;
}
/**
* 导出
*
* @param request
* @param response
* @return
*/
@SuppressWarnings({ "static-access", "unchecked" })
@RequestMapping(value = "/excelExport", method = RequestMethod.POST)
public @ResponseBody Result exportData(@RequestParam String exportdata,
HttpServletRequest request, HttpServletResponse response) {
Result result = new Result();
String uuid = UUID.randomUUID().toString();
result.setData(uuid);
cacheManager.setex(uuid, 0, 600);
executor.submit(new Runnable() {
@Override
public void run() {
try {
Map<String, List<TestResultVO>> exportMap = new LinkedHashMap<String, List<TestResultVO>>();
PageVO pageVO = JSONObject.parseObject(exportdata,
PageVO.class);
if (pageVO.getSearchParams() == null) {
ExceptionUtils.wrapBusinessException("当前参数数据有误");
}
List<TestResultVO> testvos = resultMapper
.getTestResultList(pageVO.getSearchParams());
cacheManager.setex(uuid, 7, 600);
for (TestResultVO vo : testvos) {
List<ResultVO> resultVOs = vo.getResults();
StringBuffer sb = new StringBuffer(
"{'sampleno':'样品编号','samplename':'样品名称','sampledatestr':'取样日期','uploadtime':'上传时间','batch':'批次','furnaceno':'炉号','furnacetimes':'炉次'");
if (vo.getSampledate() != null) {
vo.setSampledatestr(new SimpleDateFormat(
"yyyy-MM-dd").format(vo.getSampledate()));// 将取样日期转化为yyyy-MM-dd格式导出
}
if (resultVOs != null && resultVOs.size() > 0) {
Field fields[] = vo.getClass().getDeclaredFields();
for (int i = 0; i < resultVOs.size(); i++) {
if (i == resultVOs.size() - 1) {
sb.append(",'element")
.append(i + 1)
.append("':'")
.append(resultVOs.get(i)
.getItemname()
+ "("
+ resultVOs.get(i)
.getMeasdocname()
+ ")").append("'}");
} else {
sb.append(",'element")
.append(i + 1)
.append("':'")
.append(resultVOs.get(i)
.getItemname()
+ "("
+ resultVOs.get(i)
.getMeasdocname()
+ ")").append("'");
}
// 将子表元素值反射到主表自定义字段,以便导出使用
for (Field field : fields) {
String lastzf = null;
if (i > 8) {// 将子表元素根据下标+1与主表截取最后两位相同的赋值
lastzf = field.getName().substring(
field.getName().length() - 2);
} else {// 将子表元素根据下标+1与主表截取最后一位相同的赋值
lastzf = field.getName().substring(
field.getName().length() - 1);
}
if (NumberUtils.isDigits(lastzf)) {// 判断该类型是否为整数字符串
if (Integer.valueOf(lastzf) == i + 1) {
field.setAccessible(true);
field.set(vo, resultVOs.get(i)
.getConfirmvalue());
field.setAccessible(false);
}
}
}
}
} else {
sb.append("}");
}
List<TestResultVO> list = new ArrayList<TestResultVO>();
list.add(vo);
Boolean falg = true;// 这段逻辑处理不同元素名称,相同元素个数的情况
for (Map.Entry<String, List<TestResultVO>> enMap : exportMap
.entrySet()) {
if (enMap.getKey().contains(sb.toString())) {
falg = false;
enMap.getValue().addAll(list);
}
}
if (falg) {
exportMap.put(sb.toString(), list);
}
}
// }
// 获取浏览器信息,对文件名进行重新编码
String fileName = "化验结果查询"+uuid+".xlsx";
File directory = new File("");// 参数为空
String courseFile = directory.getCanonicalPath();
isDirExist(courseFile + "/export");
String path = courseFile
+ "/export/" + fileName;
OutputStream os = new FileOutputStream(path);
ExcelExportImportUtils.ListtoExecl(exportMap, os,uuid);
//因为分布式原因将流转成二进制存入缓存,进度条100时直接取缓存值
FileInputStream input = new FileInputStream(path);
byte[] b = InputStreamToByte(input);
cacheManager.setex(qcTestResultURL+uuid,b, 600);
cacheManager.setex(uuid, 100, 600);
File file = new File(path);
input.close();
//删除服务器文件
file.delete();
os.flush();
os.close();
} catch (Exception e) {
e.printStackTrace();
}
}
});
log.info("end method exportData,return" + result);
return result;
}
这里说下为什么写出的时候redis没存文件地址而是存了二进制流,因为项目是分布式部署,所以写地址进度条100的时候有可能找到的服务器与你写入的机器不是同一个,所以这里我直接缓存了二进制流,在下面直接取流给浏览器
/**
* 进度条100的时候将文件流写出到浏览器
* @Title: download
* @author zhangdengke
* @Description: TODO
* @param @param req
* @param @param res
* @param @return
* @return Result
* @throws
*/
@RequestMapping(value = "/download", method = RequestMethod.GET)
public @ResponseBody Result download(HttpServletRequest req, HttpServletResponse res) {
Result result = new Result();
String uuid = req.getQueryString().substring(0);
String fileName = "化验结果查询"+".xlsx";
OutputStream out = null;
try {
String agent = req.getHeader("User-Agent"); // 获取浏览器
if (agent.contains("Firefox")) {
Base64Encoder base64Encoder = new Base64Encoder();
fileName = "=?utf-8?B?"
+ base64Encoder.encode(fileName.getBytes("utf-8"))
+ "?=";
} else if (agent.contains("MSIE")) {
fileName = URLEncoder.encode(fileName, "utf-8");
} else if (agent.contains("Safari")) {
fileName = new String(fileName.getBytes("utf-8"),
"ISO8859-1");
} else {
fileName = URLEncoder.encode(fileName, "utf-8");
}
//设置返回的信息头
res.setHeader("Content-Disposition",
"attachment;filename="
+ fileName);
res.setContentType("application/vnd.ms-excel");
byte[] b = cacheManager.get(qcTestResultURL+uuid);
out = res.getOutputStream();
out.write(b);
} catch (Exception e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}finally{
try {
out.flush();
out.close();
} catch (IOException e) {
// TODO 自动生成的 catch 块
e.printStackTrace();
}
}
return result;
}
/**
* @param 当前文件夹路径
* */
public void isDirExist(String fileDir) {
File file = new File(fileDir);
if (!file.exists()) {
file.mkdir();
}
}
public static byte[] InputStreamToByte(InputStream iStrm) throws IOException {
ByteArrayOutputStream bytestream = new ByteArrayOutputStream();
int ch;
while ((ch = iStrm.read()) != -1)
{
bytestream.write(ch);
}
byte imgdata[]=bytestream.toByteArray();
bytestream.close();
return imgdata;
}
导出公共类:
package com.yonyou.scm.qc.core.utils;
import java.io.InputStream;
import java.io.OutputStream;
import java.lang.reflect.Field;
import java.math.BigDecimal;
import java.sql.Timestamp;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Date;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import net.sf.json.JSONObject;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.ss.usermodel.BorderStyle;
import org.apache.poi.ss.usermodel.HorizontalAlignment;
import org.apache.poi.ss.usermodel.VerticalAlignment;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFCellStyle;
import org.apache.poi.xssf.usermodel.XSSFFont;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.stereotype.Component;
import org.springframework.web.context.ContextLoader;
import com.yonyou.iuap.cache.CacheManager;
/**
* Excel导出导出数据工具类
*
* @author zhangdke
* @date 2019年12月4日
*
*/
public class ExcelExportImportUtils {
static int sheetsize = 2000;
static int sheetsize1 = 50000;
@Autowired
private CacheManager cacheManager;
/**
* @Description: 导入到EXCEL(单行表头)
* @param data
* 导入到excel中的数据
* @param out
* 数据写入的文件
* @param fields
* 需要注意的是这个方法中的map中:每一列对应的实体类的英文名为键,excel表格中每一列名为值
*/
public static <T> void ListtoExecl(List<T> data, OutputStream out,
Map<String, String> fields) throws Exception {
XSSFWorkbook workbook = new XSSFWorkbook();
// 如果导入数据为空,则抛出异常。
if (data == null || data.size() == 0) {
workbook.close();
throw new Exception("导入的数据为空");
}
// 根据data计算有多少页sheet
int pages = data.size() / sheetsize;
if (data.size() % sheetsize > 0) {
pages += 1;
}
// 提取表格的字段名(英文字段名是为了对照中文字段名的)
String[] egtitles = new String[fields.size()];
String[] cntitles = new String[fields.size()];
Iterator<String> it = fields.keySet().iterator();
int count = 0;
while (it.hasNext()) {
String egtitle = (String) it.next();
String cntitle = fields.get(egtitle);
egtitles[count] = egtitle;
cntitles[count] = cntitle;
count++;
}
// 添加数据
for (int i = 0; i < pages; i++) {
int rownum = 0;
// 计算每页的起始数据和结束数据
int startIndex = i * sheetsize;
int endIndex = (i + 1) * sheetsize - 1 > data.size() ? data.size()
: (i + 1) * sheetsize - 1;
// 创建每页,并创建第一行
XSSFSheet sheet = workbook.createSheet();
XSSFRow row = sheet.createRow(rownum);
// 在每页sheet的第一行中,添加字段名
for (int f = 0; f < cntitles.length; f++) {
XSSFCell cell = row.createCell(f);
cell.setCellValue(cntitles[f]);
}
rownum++;
// 将数据添加进表格
for (int j = startIndex; j < endIndex; j++) {
row = sheet.createRow(rownum);
T item = data.get(j);
for (int h = 0; h < cntitles.length; h++) {
Field fd = item.getClass().getDeclaredField(egtitles[h]);
fd.setAccessible(true);
Object o = fd.get(item);
String value = o == null ? "" : o.toString();
XSSFCell cell = row.createCell(h);
cell.setCellValue(value);
}
rownum++;
}
}
// 将创建好的数据写入输出流
workbook.write(out);
// 关闭workbook
workbook.close();
}
/**
*
* @Title: 出入参数为map时的导出方式
* @author zhangdke
* @Description: TODO
* @param @param data
* @param @param out
* @param @param fields
* @param @throws Exception
* @return void
* @throws
*/
public static <T> void ListMaptoExecl(List<Map<String, Object>> data, OutputStream out,
Map<String, Object> fields) throws Exception {
XSSFWorkbook workbook = new XSSFWorkbook();
// 如果导入数据为空,则抛出异常。
if (data == null || data.size() == 0) {
workbook.close();
throw new Exception("导入的数据为空");
}
// 根据data计算有多少页sheet
int pages = data.size() / sheetsize;
if (data.size() % sheetsize > 0) {
pages += 1;
}
// 提取表格的字段名(英文字段名是为了对照中文字段名的)
String[] egtitles = new String[fields.size()];
String[] cntitles = new String[fields.size()];
Iterator<String> it = fields.keySet().iterator();
int count = 0;
while (it.hasNext()) {
String egtitle = (String) it.next();
String cntitle = (String) fields.get(egtitle);
egtitles[count] = egtitle;
cntitles[count] = cntitle;
count++;
}
// 添加数据
for (int i = 0; i < pages; i++) {
int rownum = 0;
// 计算每页的起始数据和结束数据
int startIndex = i * sheetsize;
int endIndex = (i + 1) * sheetsize - 1 > data.size() ? data.size()
: (i + 1) * sheetsize - 1;
// 创建每页,并创建第一行
XSSFSheet sheet = workbook.createSheet();
XSSFRow row = sheet.createRow(rownum);
// 在每页sheet的第一行中,添加字段名
for (int f = 0; f < cntitles.length; f++) {
XSSFCell cell = row.createCell(f);
cell.setCellValue(cntitles[f]);
}
rownum++;
// 将数据添加进表格
for (int j = startIndex; j < endIndex; j++) {
row = sheet.createRow(rownum);
Map<String, Object> map = data.get(j);
for (int h = 0; h < cntitles.length; h++) {
Object o = map.get(egtitles[h]);
String value = o == null ? "" : o.toString();
XSSFCell cell = row.createCell(h);
cell.setCellValue(value);
}
rownum++;
}
// 必须在单元格设值以后进行
// 设置为根据内容自动调整列宽
for (int k = 0; k < cntitles.length; k++) {
sheet.autoSizeColumn(k);
}
// 处理中文不能自动调整列宽的问题
setSizeColumn(sheet, cntitles.length);
}
// 将创建好的数据写入输出流
workbook.write(out);
// 关闭workbook
workbook.close();
}
/**
* @Description: 导入到EXCEL(表头合并,数据单列)
* @param data
* 导入到excel中的数据
* @param out
* 数据写入的文件
* @param fields
* 需要注意的是这个方法中的map中:每一列对应的实体类的英文名为键,excel表格中每一列名为值
* @param workbook
* 创建好表头的XSSFWorkbook对象
*/
public static <T> void ListtoComplexExecl(List<T> data, OutputStream out,
Map<String, String> fields, XSSFWorkbook workbook) throws Exception {
// 提取表格的字段名(英文字段名是为了对照中文字段名的)
String[] egtitles = new String[fields.size()];
String[] cntitles = new String[fields.size()];
Iterator<String> it = fields.keySet().iterator();
int count = 0;
while (it.hasNext()) {
String egtitle = (String) it.next();
String cntitle = fields.get(egtitle);
egtitles[count] = egtitle;
cntitles[count] = cntitle;
count++;
}
// 添加数据
int rownum = workbook.getNumberOfSheets() + 1;
// 单页
XSSFSheet sheet = workbook.getSheetAt(0);
XSSFRow row = sheet.createRow(rownum);
// 将数据添加进表格
for (int i = 0; i < data.size(); i++) {
row = sheet.createRow(rownum);
T item = data.get(i);
for (int h = 0; h < cntitles.length; h++) {
Field fd = item.getClass().getDeclaredField(egtitles[h]);
fd.setAccessible(true);
Object o = fd.get(item);
String value = o == null ? "" : o.toString();
XSSFCell cell = row.createCell(h);
cell.setCellValue(value);
}
rownum++;
}
// 将创建好的数据写入输出流
workbook.write(out);
// 关闭workbook
workbook.close();
}
/**
* @Description: 导入到excel中的数据
* @param in
* excel文件
* @param entityClass
* excel中每一行数据的实体类
* @param fields
* 字段名字
* @return List<T>
*/
public static <T> List<T> ExecltoList(InputStream in, Class<T> entityClass,
Map<String, String> fields) throws Exception {
List<T> resultList = new ArrayList<T>();
XSSFWorkbook workbook = new XSSFWorkbook(in);
// excel中字段的中英文名字数组
String[] egtitles = new String[fields.size()];
String[] cntitles = new String[fields.size()];
Iterator<String> it = fields.keySet().iterator();
int count = 0;
while (it.hasNext()) {
String cntitle = (String) it.next();
String egtitle = fields.get(cntitle);
egtitles[count] = egtitle;
cntitles[count] = cntitle;
count++;
}
// 得到excel中sheet总数
int sheetcount = workbook.getNumberOfSheets();
if (sheetcount == 0) {
workbook.close();
throw new Exception("Excel文件中没有任何数据");
}
// 数据的导出
for (int i = 0; i < sheetcount; i++) {
XSSFSheet sheet = workbook.getSheetAt(i);
if (sheet == null) {
continue;
}
// 每页中的第一行为标题行,对标题行的特殊处理
XSSFRow firstRow = sheet.getRow(0);
int celllength = firstRow.getLastCellNum();
String[] excelFieldNames = new String[celllength];
LinkedHashMap<String, Integer> colMap = new LinkedHashMap<String, Integer>();
// 获取Excel中的列名
for (int f = 0; f < celllength; f++) {
XSSFCell cell = firstRow.getCell(f);
excelFieldNames[f] = cell.getStringCellValue().trim();
// 将列名和列号放入Map中,这样通过列名就可以拿到列号
for (int g = 0; g < excelFieldNames.length; g++) {
colMap.put(excelFieldNames[g], g);
}
}
// 由于数组是根据长度创建的,所以值是空值,这里对列名map做了去空键的处理
colMap.remove(null);
// 判断需要的字段在Excel中是否都存在
// 需要注意的是这个方法中的map中:中文名为键,英文名为值
boolean isExist = true;
List<String> excelFieldList = Arrays.asList(excelFieldNames);
for (String cnName : fields.keySet()) {
if (!excelFieldList.contains(cnName)) {
isExist = false;
break;
}
}
// 如果有列名不存在,则抛出异常,提示错误
if (!isExist) {
workbook.close();
throw new Exception("Excel中缺少必要的字段,或字段名称有误");
}
// 将sheet转换为list
for (int j = 1; j <= sheet.getLastRowNum(); j++) {
XSSFRow row = sheet.getRow(j);
// 根据泛型创建实体类
T entity = entityClass.newInstance();
// 给对象中的字段赋值
for (Entry<String, String> entry : fields.entrySet()) {
// 获取中文字段名
String cnNormalName = entry.getKey();
// 获取英文字段名
String enNormalName = entry.getValue();
// 根据中文字段名获取列号
int col = colMap.get(cnNormalName);
// 获取当前单元格中的内容
String content = row.getCell(col).toString().trim();
// 给对象赋值
setFieldValueByName(enNormalName, content, entity);
}
resultList.add(entity);
}
}
workbook.close();
return resultList;
}
/**
* @MethodName : setFieldValueByName
* @Description : 根据字段名给对象的字段赋值
* @param fieldName
* 字段名
* @param fieldValue
* 字段值
* @param o
* 对象
*/
private static void setFieldValueByName(String fieldName,
Object fieldValue, Object o) throws Exception {
Field field = getFieldByName(fieldName, o.getClass());
if (field != null) {
field.setAccessible(true);
// 获取字段类型
Class<?> fieldType = field.getType();
// 根据字段类型给字段赋值
if (String.class == fieldType) {
field.set(o, String.valueOf(fieldValue));
} else if ((Integer.TYPE == fieldType)
|| (Integer.class == fieldType)) {
field.set(o, Integer.parseInt(fieldValue.toString()));
} else if ((Long.TYPE == fieldType) || (Long.class == fieldType)) {
field.set(o, Long.valueOf(fieldValue.toString()));
} else if ((Float.TYPE == fieldType) || (Float.class == fieldType)) {
field.set(o, Float.valueOf(fieldValue.toString()));
} else if ((Short.TYPE == fieldType) || (Short.class == fieldType)) {
field.set(o, Short.valueOf(fieldValue.toString()));
} else if ((Double.TYPE == fieldType)
|| (Double.class == fieldType)) {
field.set(o, Double.valueOf(fieldValue.toString()));
} else if (Character.TYPE == fieldType) {
if ((fieldValue != null)
&& (fieldValue.toString().length() > 0)) {
field.set(o,
Character.valueOf(fieldValue.toString().charAt(0)));
}
} else if (Date.class == fieldType) {
field.set(o, new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
.parse(fieldValue.toString()));
} else if (BigDecimal.class == fieldType) {
field.set(o, new BigDecimal(fieldValue.toString()));
} else {
field.set(o, fieldValue);
}
} else {
throw new Exception(o.getClass().getSimpleName() + "类不存在字段名 "
+ fieldName);
}
}
/**
* @MethodName : getFieldByName
* @Description : 根据字段名获取字段
* @param fieldName
* 字段名
* @param clazz
* 包含该字段的类
* @return 字段
*/
private static Field getFieldByName(String fieldName, Class<?> clazz) {
// 拿到本类的所有字段
Field[] selfFields = clazz.getDeclaredFields();
// 如果本类中存在该字段,则返回
for (Field field : selfFields) {
if (field.getName().equals(fieldName)) {
return field;
}
}
// 否则,查看父类中是否存在此字段,如果有则返回
Class<?> superClazz = clazz.getSuperclass();
if (superClazz != null && superClazz != Object.class) {
return getFieldByName(fieldName, superClazz);
}
// 如果本类和父类都没有,则返回空
return null;
}
/**
* @Title: 生成动态多表头execl
* @author zhangdke
* @Description: TODO
* @param map
* @param out
* @return void
* @throws
*/
public static <T> void ListtoExecl(Map<String, List<T>> map,
OutputStream out,String rediskey) throws Exception {
XSSFWorkbook workbook = new XSSFWorkbook();
// 如果导入数据为空,则抛出异常。
if (map.isEmpty()) {
workbook.close();
throw new Exception("导入的数据为空");
}
XSSFCellStyle headStyle = getHeadStyle(workbook);//表头样式
XSSFCellStyle bodyStyle = getBodyStyle(workbook);//表体样式
int size = 0;//行
XSSFSheet sheet = workbook.createSheet();
ApplicationContext context = ContextLoader.getCurrentWebApplicationContext();
CacheManager cacheManager = context.getBean(CacheManager.class);
int provalue = 93/map.size();//服务器写出execl时间大约为93%,计算每次执行百分比,每次执行更新缓存
for (Map.Entry<String, List<T>> entry : map.entrySet()) {
int redisvalue = cacheManager.get(rediskey);
redisvalue = redisvalue+provalue;//
cacheManager.setex(rediskey,redisvalue, 600);
List<T> list = entry.getValue();
Map<String, String> fields = (Map<String, String>) JSONObject
.fromObject(entry.getKey());
// 提取表格的字段名(英文字段名是为了对照中文字段名的)
String[] egtitles = new String[fields.size()];
String[] cntitles = new String[fields.size()];
Iterator<String> it = fields.keySet().iterator();
int count = 0;
while (it.hasNext()) {
String egtitle = (String) it.next();
String cntitle = fields.get(egtitle);
egtitles[count] = egtitle;
cntitles[count] = cntitle;
count++;
}
XSSFRow row = sheet.createRow(size);
// 添加表头信息
for (int f = 0; f < cntitles.length; f++) {
XSSFCell cell = row.createCell(f);
cell.setCellValue(cntitles[f]);
cell.setCellStyle(headStyle);
}
for (T t : list) {
size++;
row = sheet.createRow(size);
for (int h = 0; h < cntitles.length; h++) {
Field fd = t.getClass().getDeclaredField(egtitles[h]);
fd.setAccessible(true);
Object o = fd.get(t);
String value = typeConversion(o);
XSSFCell cell = row.createCell(h);
cell.setCellValue(value);
cell.setCellStyle(bodyStyle);
}
}
size++;
// 必须在单元格设值以后进行
// 设置为根据内容自动调整列宽
for (int k = 0; k < cntitles.length; k++) {
sheet.autoSizeColumn(k);
}
// 处理中文不能自动调整列宽的问题
setSizeColumn(sheet, cntitles.length);
}
// 将创建好的数据写入输出流
workbook.write(out);
// 关闭workbook
workbook.close();
}
/**
* @Title: 自适应列宽度中文支持
* @author zhangdke
* @Description: TODO
* @param sheet
* @param size
* @return void
* @throws
*/
private static void setSizeColumn(XSSFSheet sheet, int size) {
for (int columnNum = 0; columnNum < size; columnNum++) {
int columnWidth = sheet.getColumnWidth(columnNum) / 256;
for (int rowNum = 0; rowNum < sheet.getLastRowNum(); rowNum++) {
XSSFRow currentRow;
// 当前行未被使用过
if (sheet.getRow(rowNum) == null) {
currentRow = sheet.createRow(rowNum);
} else {
currentRow = sheet.getRow(rowNum);
}
if (currentRow.getCell(columnNum) != null) {
XSSFCell currentCell = currentRow.getCell(columnNum);
if (currentCell.getCellType() == XSSFCell.CELL_TYPE_STRING) {
int length = currentCell.getStringCellValue()
.getBytes().length;
if (columnWidth < length) {
columnWidth = length;
}
}
}
}
sheet.setColumnWidth(columnNum, columnWidth * 256);
}
}
/**
* @Title: 字符串转换规则
* @author zhangdke
* @Description: TODO
* @param columnVal
* @return String
* @throws
*/
private static String typeConversion(Object columnVal) throws Exception {
String value = null;
if (null == columnVal) {
value = "";
} else {
if (columnVal.getClass().equals(Timestamp.class)) {
DateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Timestamp timestamp = (Timestamp) columnVal;
value = sdf.format(timestamp);
} else {
value = columnVal.toString();
}
}
return value;
}
/**
* @Title: 表头样式
* @author zhangdke
* @Description: TODO
* @param workbook
* @return XSSFCellStyle
* @throws
*/
private static XSSFCellStyle getHeadStyle(XSSFWorkbook workbook){
// 字体样式
XSSFFont xssfFont = workbook.createFont();
// 加粗
xssfFont.setBold(true);
// 字体名称
xssfFont.setFontName("楷体");
// 字体大小
xssfFont.setFontHeight(12);
// 表头样式
XSSFCellStyle headStyle = workbook.createCellStyle();
// 设置字体css
headStyle.setFont(xssfFont);
// 竖向居中
headStyle.setVerticalAlignment(VerticalAlignment.CENTER);
// 横向居中
headStyle.setAlignment(HorizontalAlignment.CENTER);
// 边框
headStyle.setBorderBottom(BorderStyle.THIN);
headStyle.setBorderLeft(BorderStyle.THIN);
headStyle.setBorderRight(BorderStyle.THIN);
headStyle.setBorderTop(BorderStyle.THIN);
return headStyle;
}
/**
* @Title: 表体样式
* @author zhangdke
* @Description: TODO
* @param workbook
* @return XSSFCellStyle
* @throws
*/
private static XSSFCellStyle getBodyStyle(XSSFWorkbook workbook){
// 内容字体样式
XSSFFont contFont = workbook.createFont();
// 加粗
contFont.setBold(false);
// 字体名称
contFont.setFontName("楷体");
// 字体大小
contFont.setFontHeight(11);
// 内容样式
XSSFCellStyle bodyStyle = workbook.createCellStyle();
// 设置字体css
bodyStyle.setFont(contFont);
// 竖向居中
bodyStyle.setVerticalAlignment(VerticalAlignment.CENTER);
// 横向居中
bodyStyle.setAlignment(HorizontalAlignment.CENTER);
// 边框
bodyStyle.setBorderBottom(BorderStyle.THIN);
bodyStyle.setBorderLeft(BorderStyle.THIN);
bodyStyle.setBorderRight(BorderStyle.THIN);
bodyStyle.setBorderTop(BorderStyle.THIN);
return bodyStyle;
}
}