1、Scala安装
(1)解压文件
ubuntu@Ubuntu:~$ sudo tar -zxvf scala-2.10.4.gz -C /opt

(2) 环境变量配置
ubuntu@Ubuntu:~$ sudo gedit /etc/profile
#SCALA
export SCALA_HOME=/opt/scala-2.10.4
export PATH=$PATH:$SCALA_HOME/bin
ubuntu@Ubuntu:~$ source /etc/profile

2、Spark安装
(1)解压文件
ubuntu@Ubuntu:~$ sudo tar -zxvf spark-1.6.0-bin-hadoop.gz -C /home/hnu

(2)环境变量配置
ubuntu@Ubuntu:~$ sudo gedit /etc/profile
#SPARK
export SPARK_HOME=/home/hnu/spark-1.6.0-bin-hadoop
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
ubuntu@Ubuntu:~$ source /etc/profile
(3)配置Spark
ubuntu@Ubuntu:/home/hnu/spark-1.6.0-bin-hadoop/conf$ sudo cp spark-env.sh.template spark-env.sh
ubuntu@Ubuntu:/home/hnu/spark-1.6.0-bin-hadoop/conf$ sudo gedit spark-env.sh
#spark
export JAVA_HOME=/opt/jdk1.8.0_91
export SCALA_HOME=/opt/scala-2.10.4
export SPARK_MASTER_IP=127.0.0.1
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/home/hnu/hadoop-2.6.0/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/home/hnu/hadoop-2.6.0/bin/hadoop classpath)
(4)赋予权限
root@Ubuntu:/home/hnu# chown -R hnu:hadoop spark-1.6.0-bin-without-hadoop/
(5)启动Spark
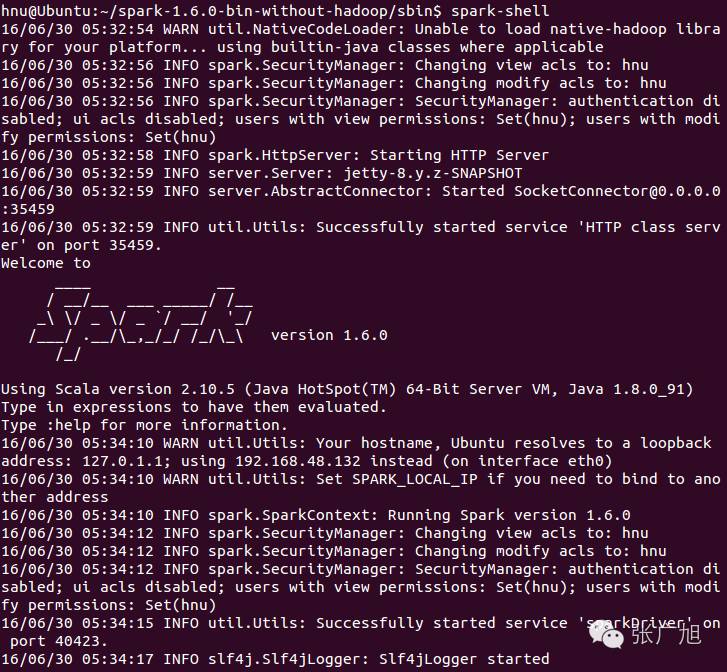
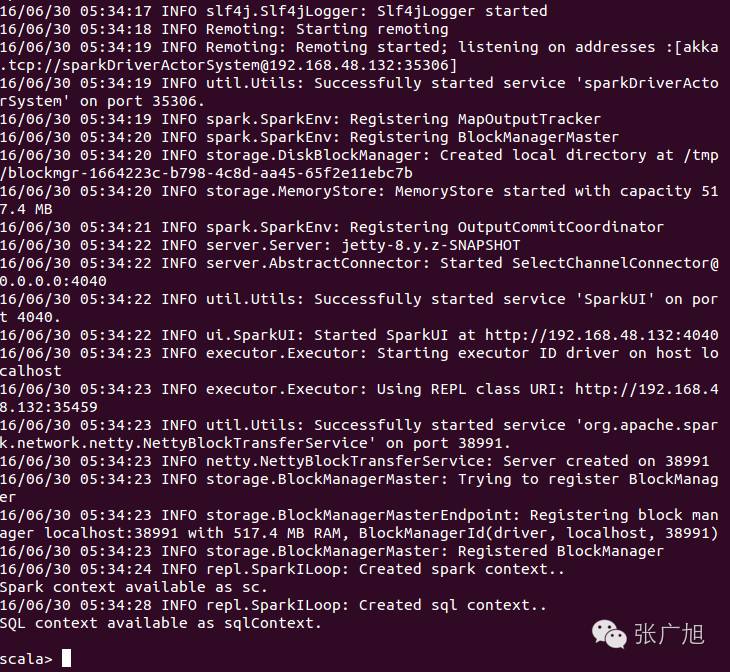
hnu@Ubuntu:~/spark-1.6.0-bin-hadoop/sbin$ ./start-all.sh

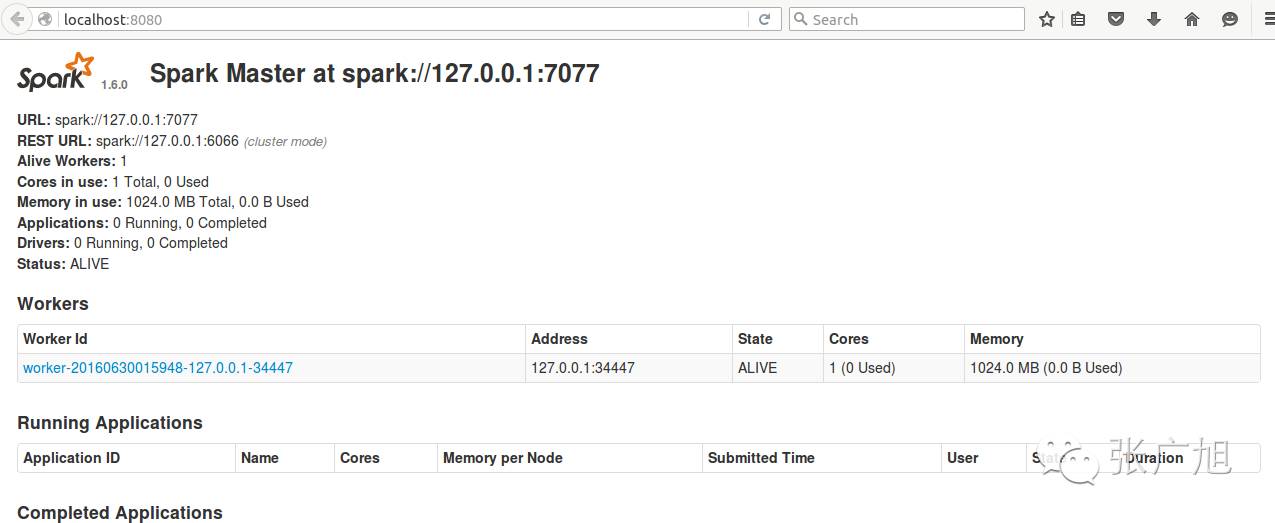
http://localhost:8080/
hnu@Ubuntu:~/spark-1.6.0-bin-hadoop/sbin$ spark-shell