1)方法1:
re.search(r'xx', str)
2)方法2:
pattern = re.compile(r'xxx')
pattern.search(str)
两种方法效率图表如下:
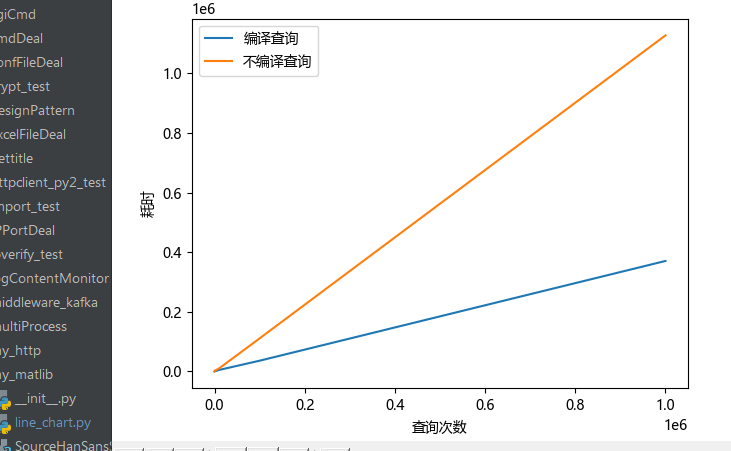
分析可知,随着查询次数的增加,编译后查询的方式明显快于不编译直接查询
原因:分析正则查询源码,发现查询方法底层实际都有两步调用,以 search 为例
方法1中re.search() 的调用流程实质为: search --------> re._compile(pattern, flags).search(string)
方法2中的调用流程为: pattern.search(string)
两相比较,多次调用的情况下,方法1重复执行了 re._compile(pattern, flags), 而方法2仅执行一次。