表扫描、索引扫描、索引查找三者的区别
日常工作中我们常听到这个三个名词,都是什么意思呢?什么情况下会出现上面的情况?以及出现了上面的情况我们该如何优化能使我们的sql执行效率更高?下面我们就带这这3个问题进入我们的主题 “Sqlserver表索引优化入门一”
先看一条sql,从这条sql我们逐一的引入这个三个概念
SELECT OrderId,OrderPhoneHash,SeriesName FROM dbo.Order_Info_Back WHERE SeriesName='翼虎'
表扫描:


看表扫描出现了,再看下我们这张表的设计
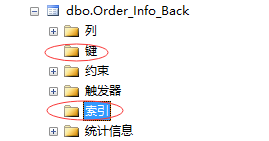
大家发现了没这张表没有主键没有任何索引,所以这时候对这张表的查询走的是表扫描(Table Scan)
索引扫描:
下面我们为这张表增加一个聚集索引
ALTER TABLE [dbo].[Order_Info_Back] ADD CONSTRAINT [PK_Order_Info_Back] PRIMARY KEY CLUSTERED
(
[ID] ASC
)
再执行上面的sql语句,看看会出现什么情况。


表扫描变成了索引扫描,准确的说应该是聚集索引扫描。这时候大家看其实sql执行的性能没有任何提升,为什么?从概念上来讲表扫描就是把表里的数据一行一行的扫描一遍然后返回结果,而索引扫描是先找到索引的区域然后遍历这个区域的数据从而返回结果。这样讲的话性能应该有所提升才对啊,之所以我们的这个例子性能没有提升是因为我们并没有对我们的查询条件建立索引,所以即便走了索引扫描也是相当于整表的遍历,性能并没有什么提升。
好吧,我们为我们的这张表添加一个非聚集索引
索引查找:
CREATE NONCLUSTERED INDEX [IX_OrderInfo_SeriesName] ON [dbo].[Order_Info_Back]
(
[SeriesName] ASC
)
执行上面sql。
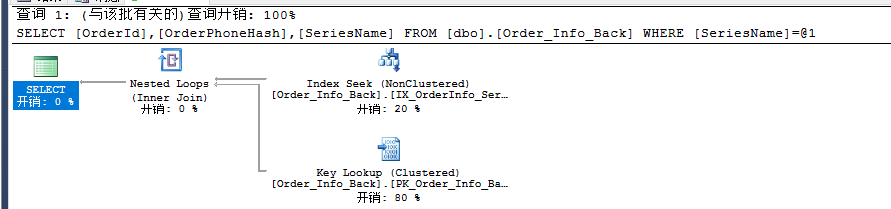

我靠这次性能提升明显逻辑读由原来的5952变成了 17 质的飞跃提升了350倍,但是大家会发现 出现了一个KeyLookup (Clustered)这么个玩意这个东西消耗了我们80%的性能,能不能把这玩意给优化掉呢?
好先理解下为什么会出现这个东东。查询计划使用我们创建的“IX_OrderInfo_SeriesName”非聚集索引来执行查找返回结果,对于OrderId,OrderPhoneHash这个两个字段并不是索引的一部分,查询引擎必须返回到基表中再查询一次然后返回结果。这个过程就产生了Key Lookup 。好既然知道这东西是怎么产生的了,那下面就来消除这个Key Lookup,很简单不让查询引擎再查一次不就的了。怎么办?传说中的覆盖索引,就是把select 的字段都加到索引当中,好不好使试下就知道了
CREATE NONCLUSTERED INDEX [IX_OrderInfo_SeriesName] ON [dbo].[Order_Info_Back]
(
[OrderId] ASC,
[OrderPhoneHash] ASC,
[SeriesName] ASC
)
执行sql


果然按我们的预期key Lookup 消除了,但是这时候我们发现逻辑读取上去了,上面的索引查找变成了索引扫描,还不如不消除的好。为什么多加了几个索引字段索引查找就变成了索引扫描了。到这里大家可以猜下原因了
经过实践尝试发现,索引查找和索引扫描和索引字段的顺序有关我们把where或者on的条件的字段调整到前面再执行下sql看下结果


神奇的发现不但消除了 Key Lookup 而且还变成了索引查找,逻辑读只有3 性能再次提升由上面最好的 17变成了3
索引包含:
上面的sql 我们基本上优化到了极致,但是大家都知道索引创建的太多也会有问题。插入、删除、修改的性能会受到影响。有没有办法减少这样的影响并且性能不受影响呢?答案当然是有了,这就是“索引包含”。
先上sql
CREATE NONCLUSTERED INDEX [IX_OrderInfo_SeriesName] ON [dbo].[Order_Info_Back]
(
[SeriesName] ASC
)
INCLUDE ( [OrderId],
[OrderPhoneHash])
执行sql


神奇的发现逻辑读再次减少,这回真正的优化到了极致。
至于索引和索引包含他们之间又有什么区别,这个涉及到sqlserver数据底层存储的问题,后面会专门把这个拿出来讲解下。