To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and being are stored as showed in Figure 1.
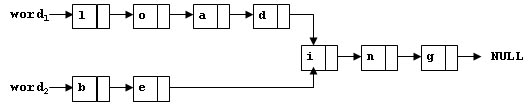
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤105), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
Sample Output 1:
67890
Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
Sample Output 2:
-1
思路:
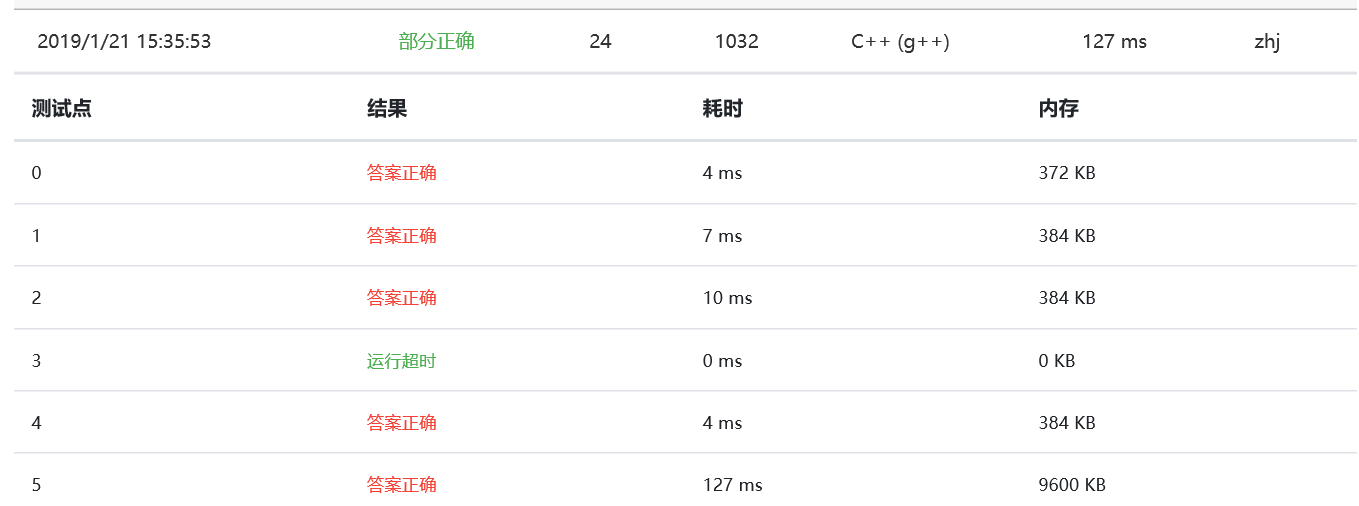
1、我最开始的思路是把第一个链表的每一个地址全部放在set中,然后遍历第二个链表,在set中查找地址,如果有则输出,结果:
不知道为什么第三个会超时,不应该是第五个吗?
代码如下:
#include<iostream> #include<vector> #include<algorithm> #include<queue> #include<string> #include<map> #include<set> using namespace std; set<int> s; struct Node { char data; int next; }; map<int,Node> mp; int main() { int addressA,addressB,n; scanf("%d%d%d",&addressA,&addressB,&n); for(int i=0; i<n; i++) { Node temp; int add1; scanf("%d %c%d",&add1,&temp.data,&temp.next); //cout<<add1<<" "<<temp.data<<" "<<temp.next<<endl; mp[add1]=temp; } int temp=addressA; s.insert(temp); while(mp[temp].next!=-1) { temp=mp[temp].next; s.insert(temp); // temp= } temp=addressB; bool flag=true; while(mp[temp].next!=-1) { if(s.find(temp)!=s.end()) { printf("%05d",temp); //cout<<temp; flag=false; break; } temp=mp[temp].next; } if(flag) { printf("-1"); //cout<<"-1"; } return 0; }
2、参考柳婼的代码之后才知道只要遍历两次就可以了,不过我使用的是map所以还是回超时,所以只能在输入的时候顺便做一些处理。
#include<iostream> #include<vector> #include<algorithm> #include<queue> #include<string> #include<map> #include<set> using namespace std; set<int> s; struct Node { char data=' '; int next=-1; bool visit=false; }; map<int,Node> mp; int main() { int addressA,addressB,n,next; scanf("%d%d%d",&addressA,&addressB,&n); int temp=addressA; Node node; mp[-1]=node; for(int i=0; i<n; i++) { int add1; scanf("%d %c%d",&add1,&node.data,&node.next); mp[add1]=node; if(temp==add1) { mp[temp].visit=true; temp=node.next; } } if(temp!=-1) { while(mp[temp].next!=-1) { mp[temp].visit=true; temp=mp[temp].next; } } temp=addressB; // bool flag=true; while(mp[temp].next!=-1) { if(mp[temp].visit==true) { printf("%05d",temp); //cout<<temp; return 0; } temp=mp[temp].next; } printf("-1"); return 0; }