常用的数据库有关系数据库和NOSQL数据库。python支持各种类型的数据库。但是写数据库有一个很麻烦的地方就是要经常写数据库语句,如果你不想写数据库语句的话,那么在flask中可以使用sqlalchemy的方式来进行数据库操作。
首先安装flask-sqlalchemy扩展。pip install flask-sqlalchemy
我们用关系数据库的例子来进行举例,在关系数据库中最常用的就是mysql和sqlite3,在系统中必须要先安装mysql和sqlite3
在Flask-sqlalchemy中,数据库使用URL指定。数据库URL如下:
MySQL: mysql://username:password@hostname/database
SQLite(linux):sqlite:////absolute/path/to/database
SQLite(windows):sqlite:///c:/absolute/path/to/database
sqlite3的配置:
第一步 新建一个文件model_sqlite.py
第二步 在model_sqlite.py中配置数据库
from flask_sqlalchemy import SQLAlchemy
import os
from flask import Flask
basedir=os.path.abspath(os.path.dirname(__file__))
app=Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URL']='sqlite:///'+os.path.join(basedir,'data.sqlite')
db=SQLAlchemy(app)
db对象是SQLAlchemy类的实例。表示程序正在使用的数据库,同时还获得了Flask-SQLAlchemy提供的所有功能
第三步:定义模型
在SQLAlchemy中,模型就是一个python类,其中的属性对应数据库中的列。定义如下。这和在django中的定义是完全一样的。
class User(db.Model):
__tablename__='Users'
id=db.Column(db.Integer,primary_key=True)
name=db.Column(db.String(64),unique=True,index=True)
def __repr__(self):
return '<User %r>' % self.name
class Role(db.Model):
__tablename__='Role'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64), unique=True)
def __repr__(self):
return '<User %r>' % self.name
在User和Role中分别定义了整数的id和String的name. 在SQLAlchemy中的类型如下:
类型名称 python类型 描述
Integer int 常规整形,通常为32位
SmallInteger int 短整形,通常为16位
BigInteger int或long 精度不受限整形
Float float 浮点数
Numeric decimal.Decimal 定点数
String str 可变长度字符串
Text str 可变长度字符串,适合大量文本
Unicode unicode 可变长度Unicode字符串
Boolean bool 布尔型
Date datetime.date 日期类型
Time datetime.time 时间类型
Interval datetime.timedelta 时间间隔
Enum str 字符列表
PickleType 任意Python对象 自动Pickle序列化
LargeBinary str 二进制
同时还定义了属性的配置选项,常见的选项如下
|
选项名 |
说 明 |
|
primary_key |
如果设为 True ,这列就是表的主键 |
|
unique |
如果设为 True ,这列不允许出现重复的值 |
|
index |
如果设为 True ,为这列创建索引,提升查询效率 |
|
nullable |
如果设为 True ,这列允许使用空值;如果设为 False ,这列不允许使用空值 |
|
default |
为这列定义默认值 |
第四步:创建数据库
if __name__=="__main__":
db.create_all()
运行之后可以看到工程中增加了一个data.sqlite的数据库文件
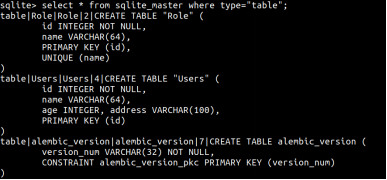
同时我们用命令行进入这个文件进行查看。可以看到在这个数据库文件中存在了Role和Users2个数据库。
root@zhf-maple:/home/zhf/py_prj/flask_prj# sqlite3 data.sqlite
SQLite version 3.19.3 2017-06-08 14:26:16
Enter ".help" for usage hints.
sqlite> .database
main: /home/zhf/py_prj/flask_prj/data.sqlite
sqlite> .tables
Role Users
说明数据库创建成功。
sqlite的命令如下:
sqlite中命令:
以.开头,大小写敏感(数据库对象名称是大小写不敏感的)
.exit
.help 查看帮助 针对命令
.database 显示数据库信息;包含当前数据库的位置
.tables 或者 .table 显示表名称 没有表则不显示
.schema 命令可以查看创建数据对象时的SQL命令;
.schema databaseobjectname查看创建该数据库对象时的SQL的命令;如果没有这个数据库对象就不显示内容,不会有错误提示
.read FILENAME 执行指定文件中的SQL语句
.headers on/off 显示表头 默认off
.mode list|column|insert|line|tabs|tcl|csv 改变输出格式
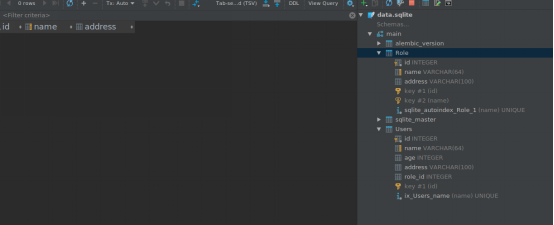
为了方便在pycharm中查看数据表结构。我们可以在pycharm中导入数据库
1 在Database中选择sqlite(Xerial)
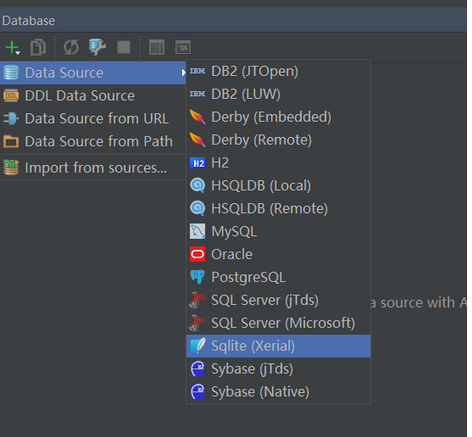
在File中导入数据库所在文件的路径。注意下面的Download提示,这个意思是提示没有驱动文件。点击Download就可以下载驱动文件。
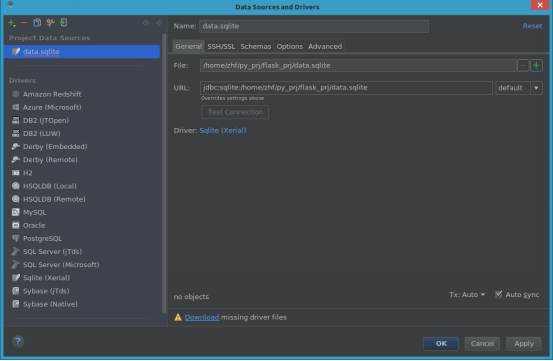
可以看到导入成功了。
现在数据库已经建好了,那么下面就需要进行数据库插入操作了。
def add_data_in_Role():
admin_Role=Role(name='zhf')
user_Role=Role(name='dxx')
db.session.add(admin_Role)
db.session.add(user_Role)
normal_user=User(name='norma_user')
super_user=User(name='super_user')
db.session.add(normal_user)
db.session.add(super_user)
db.session.commit()
在初始化对象的时候,我们并没有给id赋值,因为id是主键是由Flask-SQLAlchemy管理的。当初始化完了之后还需要写入到数据库中去。在Flask-SQLAlchemy中。会话由db.session表示,在把对象写入到数据库之前,先要加入到会话中去。最后将会话commit就可以了。
登录到数据库中也可以通过sql语句查询到对应的数据。id自动生成了。

查询语句:
def query_data():
print Role.query.all()
print User.query.all()
print Role.query.filter().first()
print Role.query.filter_by(name='zhf').all()
print Role.query.filter_by(name='zhf').first()
print Role.query.filter_by(name='zhf').order_by('name').first()
print Role.query.filter_by(name='zhf').group_by('name').first()
print Role.query
print Role.query.filter_by(name='zhf')
print Role.query.filter_by(name='zhf').order_by('name')数据库内容写好之后,查询的话通过query的方法进行查询。查询有如下的过滤器
filter(): 过滤器加到原查询上,返回一个新的查询
filter_by():把等值过滤器添加到原查询上
limit():使用指定的值限制查询返回的结果数量
offset():偏移原查询返回的结果
order_by():根据指定条件对原查询结果进行排序
group_by():根据指定条件对原查询结果进行分组。
查询执行函数:
all():以列表形式返回查询的所有值
first():返回查询的第一个结果
first_or_404():返回查询的第一个结果,如果没有结果,则终止请求,返回404响应
get():返回指定主键对应的行,参数是主键的值
get_or_404():返回指定主键对应的行,如果没有结果,则终止请求,返回404响应
count():返回查询到的个数
paginate():返回一个paginate对象,包含指定范围内的结果
前面执行的查询结果如下。可以看到如果后面不带查询执行函数的时候,返回的其实是SQL语句
[<User u'zhf'>, <User u'dxx'>]
[<User u'norma_user'>, <User u'super_user'>]
<User u'zhf'>
[<User u'zhf'>]
<User u'zhf'>
<User u'zhf'>
<User u'zhf'>
SELECT "Role".id AS "Role_id", "Role".name AS "Role_name"
FROM "Role"
SELECT "Role".id AS "Role_id", "Role".name AS "Role_name"
FROM "Role"
WHERE "Role".name = ?
SELECT "Role".id AS "Role_id", "Role".name AS "Role_name"
FROM "Role"
WHERE "Role".name = ? ORDER BY "Role".name
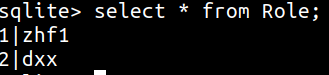
修改行:
def modify_data():
role=Role.query.filter().first()
role.name='zhf1'
db.session.add(role)
db.session.commit()
修改成功
删除行:
def delete_data():
role = Role.query.filter().first()
role.name = 'zhf1'
db.session.delete(role)
db.session.commit()

数据迁移:
在实际应用中,数据库的结果是经常变动的。那么变动之后我们如何适配新的数据表结构呢。比如在User中添加age和address属性
class User(db.Model):
__tablename__='Users'
id=db.Column(db.Integer,primary_key=True)
name=db.Column(db.String(64),unique=True,index=True)
age=db.Column(db.Integer)
address=db.Column(db.String(100))
def __repr__(self):
return '<User %r>' % self.name
第一步 创建迁移仓库
root@zhf-maple:/home/zhf/py_prj/flask_prj# python model_sqlite.py db init
/usr/local/lib/python2.7/dist-packages/flask_sqlalchemy/__init__.py:794: FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.
'SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and '
Creating directory /home/zhf/py_prj/flask_prj/migrations ... done
Creating directory /home/zhf/py_prj/flask_prj/migrations/versions ... done
Generating /home/zhf/py_prj/flask_prj/migrations/env.pyc ... done
Generating /home/zhf/py_prj/flask_prj/migrations/alembic.ini ... done
Generating /home/zhf/py_prj/flask_prj/migrations/script.py.mako ... done
Generating /home/zhf/py_prj/flask_prj/migrations/env.py ... done
Generating /home/zhf/py_prj/flask_prj/migrations/README ... done
Please edit configuration/connection/logging settings in
'/home/zhf/py_prj/flask_prj/migrations/alembic.ini' before proceeding.
成功创建数据库仓库文件
root@zhf-maple:/home/zhf/py_prj/flask_prj/migrations# ls -al
总用量 32
drwxr-xr-x 3 root root 4096 2月 9 22:16 .
drwxrwxr-x 6 zhf zhf 4096 2月 9 22:16 ..
-rw-r--r-- 1 root root 770 2月 9 22:16 alembic.ini
-rwxr-xr-x 1 root root 2884 2月 9 22:16 env.py
-rw-r--r-- 1 root root 2734 2月 9 22:16 env.pyc
-rwxr-xr-x 1 root root 38 2月 9 22:16 README
-rwxr-xr-x 1 root root 494 2月 9 22:16 script.py.mako
drwxr-xr-x 2 root root 4096 2月 9 22:16 versions
第二步:初始化migrate需要的环境,接下来生成一个数据表操作的代码文件
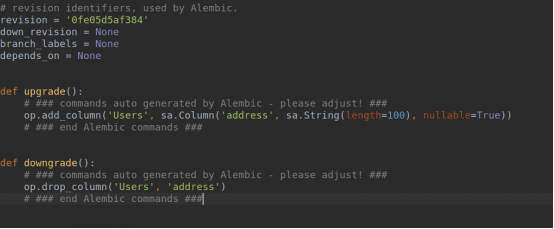
在Alembic,数据库迁移工作由迁移脚本完成。这个脚本有两个函数,分别叫做upgrade()和downgrade()。upgrade()函数实施数据库更改,是迁移的一部分,downgrade()函数则删除它们。通过添加和删除数据库变化的能力,Alembic可以重新配置数据库从历史记录中的任何时间点。
Alembic迁移可以分别使用revision和migrate命令手动或自动创建。手动迁移通过由开发人员使用Alembic的Operations对象指令实现的空upgrade()和downgrade()函数创建迁移框架脚本。另一方面,自动迁移通过寻找模型定义和数据库当前状态间的不同为upgrade()和downgrade()生成代码。
root@zhf-maple:/home/zhf/py_prj/flask_prj# python model_sqlite.py db migrate
/usr/local/lib/python2.7/dist-packages/flask_sqlalchemy/__init__.py:794: FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.
'SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and '
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.autogenerate.compare] Detected added column 'Users.address'
Generating /home/zhf/py_prj/flask_prj/migrations/versions/0fe05d5af384_.py ... done
可以看到在migrations的versions下面生成了迁移文件

里面是两个函数,一个是upgrade一个是downgrade
第三步:更新表结构。
root@zhf-maple:/home/zhf/py_prj/flask_prj# python model_sqlite.py db upgrade
/usr/local/lib/python2.7/dist-packages/flask_sqlalchemy/__init__.py:794: FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disabled by default in the future. Set it to True or False to suppress this warning.
'SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and '
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
INFO [alembic.runtime.migration] Will assume non-transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> 0fe05d5af384, empty message
查看表结构可以看到对应的属性列已经添加进表中