前面的章节已经讲解了数据分析的基本操作,
接下来就通过具体的简单分析例子来说明前面基本知识的应用
本章原作者示例数据采用的都是美国相关数据(因为作者是外国人),
我会从国内的角度,选取中国可以看到的或者找到的公开数据进行分析
数据分析的主要步骤:
1、从网上获取公开数据(此处是PDF)
2、读取PDF中表格数据
3、多页数据连接
4、数据清洗和整理
5、数据聚合和分组
6、数据绘图与可视化
7、保存绘图
接下来进行详细的说明
1、从网上获取公开数据(此处是PDF)
此处选择的数据是“上海交通大学研究生院2018年考试及录取”统计数据,
数据地址:https://yzb.sjtu.edu.cn/xxgs1/lssj/wnbklqtj.htm
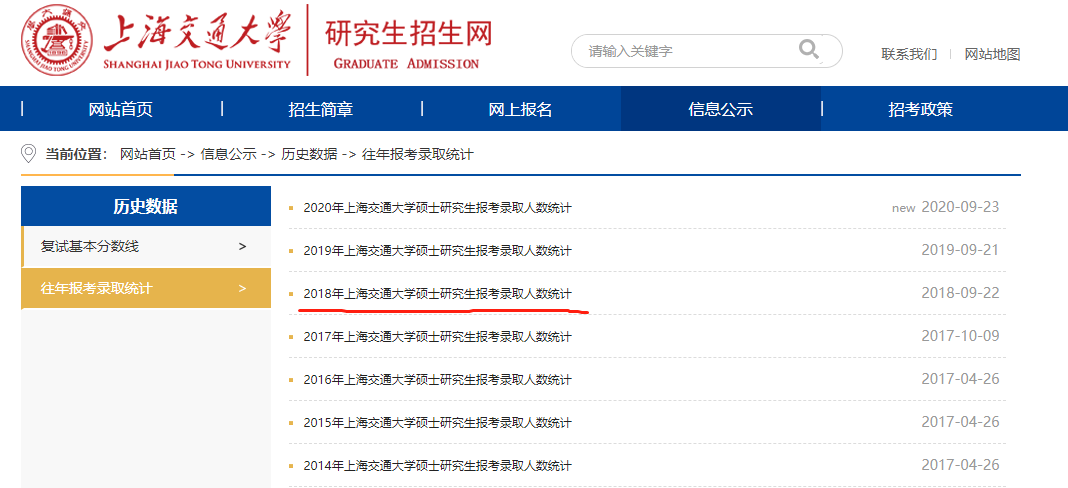
数据下载后命名为“2018.pdf”,方便后续数据读取,pdf部分内容截图如下:

2、读取PDF格式表格数据
之前章节,我们有学习读取CSV、excel等格式的数据,但是没有学习pdf,遇到问题,不放弃,寻找方法
从百度查询,可以了解到,通过pdfplumber这个包可以处理pdf数据,我们来安装这个包:
点击如下程序:
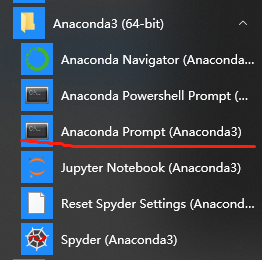
会出现命令符式的黑框,通过pip命令来安装pdfplumber包,如下:

等待,直到安装完成,如果出现红字,提示没有安装成功,有“time out”英文字眼的话,大概率是国外软件包地址下载不稳定,那就通过国内镜像源下载
国内镜像源有很多:

此处我们采用第一个,清华的镜像源为例:

一般这样就好安装成功,安装后,进入jupyter软件,可以导入测试一下,是否安装成功

如果没有提示,那就代表安装成功,可以读取pdf数据了
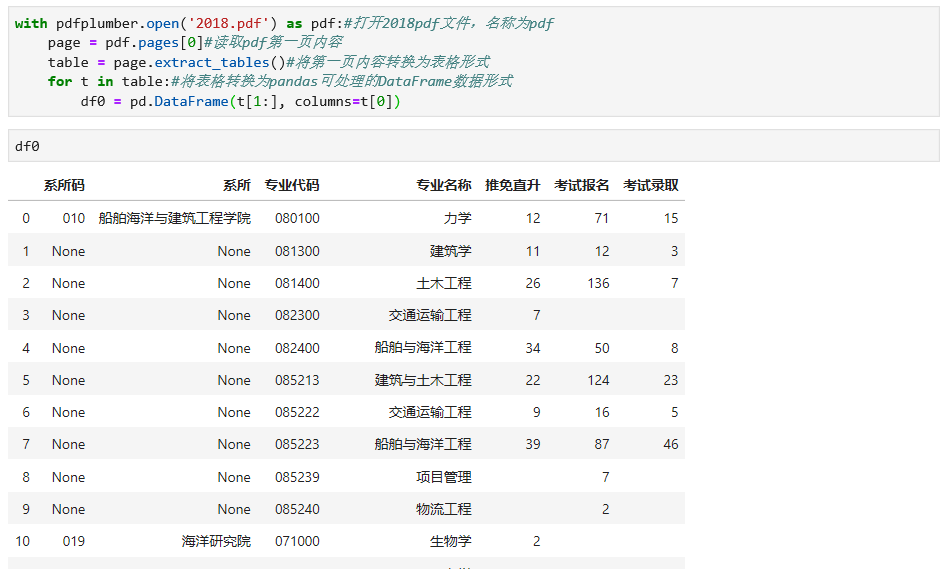
我们首先读取pdf第一页的表格数据,具体代码及读取结果如下:
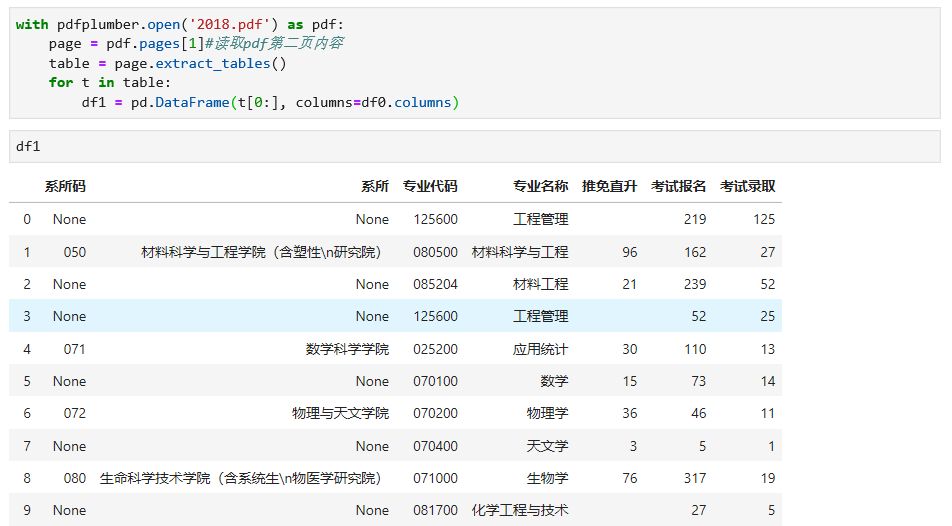
我们读取第二页pdf数据表格内容,具体代码及结果如下:
其他页码的数据同样的读取逻辑,在此不再赘述,接下来采用已读取的这两页内容进行分析
3、多页数据连接
至此,我们已经有两页的数据,现在将两页的数据合并在一起,进行拼接,具体代码及运行结果如下:
4、数据清洗和整理
数据的清洗和整理,要看我们数据分析的目的
此处我们的目的:分析“电子信息与电气工程学院”各专业推免、报名、录取的情况
电子信息与电器工程学院的系所码是“030”,我们查看发现,该系所码没有,仔细核对发现,是读取数据的时候没有识别出来,如下:
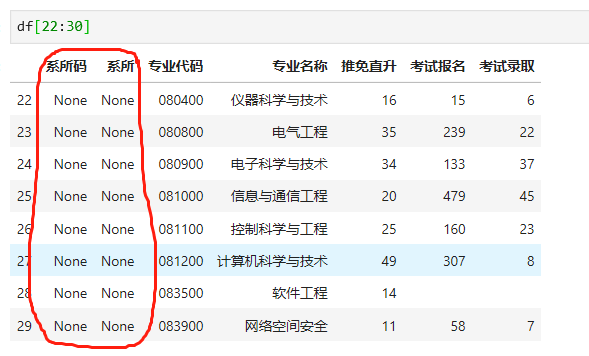
我们修正系所码和系所名称,具体代码及结果如下:

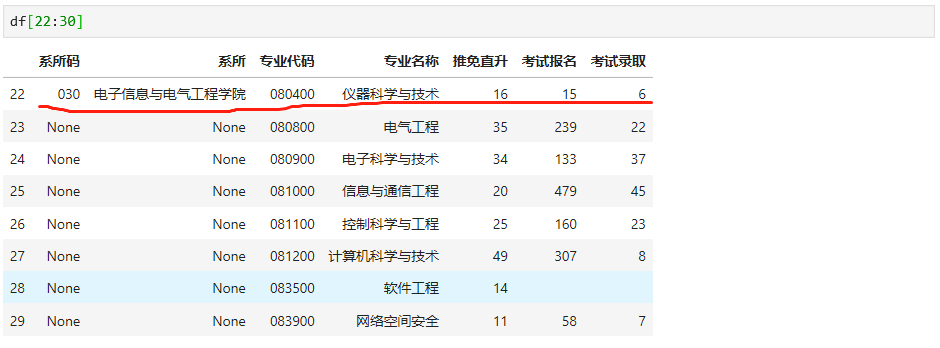
我们为什么只修正一处,因为后面我们想对没有数据的地方,从上到下自动填充
现在对整个数据集中空白的地方,就近从上到下自动填充,代码及运行结果如下:
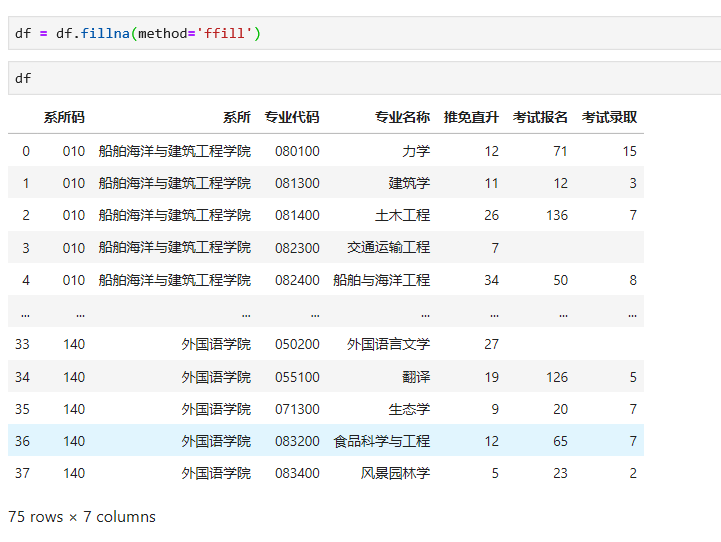
至此,从格式上看,我们发现比最初导入的数据更规整,更符合数据处理的要求了
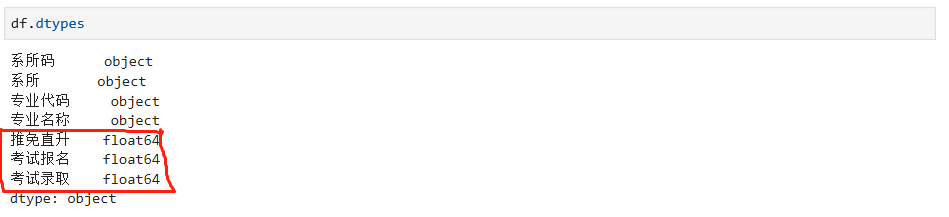
因为数据处理涉及到不同的数据类型,所以,我们需要查看每列数据的类型,如下:
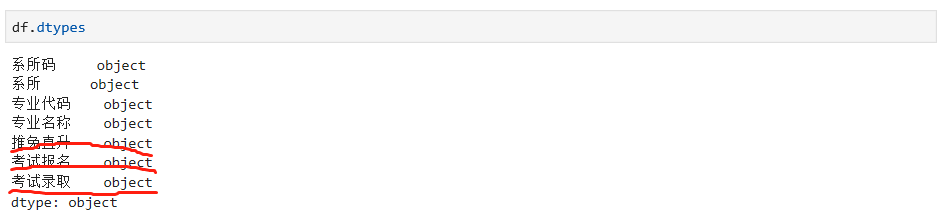
我们发现每列都是对象的类型,但是在处理数据的过程中,我们用到的都是整数或者浮点数,所以需要对不同的列进行数据转换
数据转换主要用到astype方法,具体代码如下:

再来看下各列数据类型:
选择我们需要的数据,与“电子信息与电气工程学院”相关,通过系所码进行筛选,如下:

和pdf数据比对,符合我们需要的数据
5、数据聚合和分组
接下来,我们想通过不同的专业,来看各自的数据,具体代码及运行结果如下:
此处提醒一点,就是如果存的专业名称一样数据不同的,会聚合在一起,保留唯一的专业名称

6、数据绘图与可视化
针对分组整理后的数据,我们进行绘图,这个数据适合柱状图,具体代码及运行结果如下:
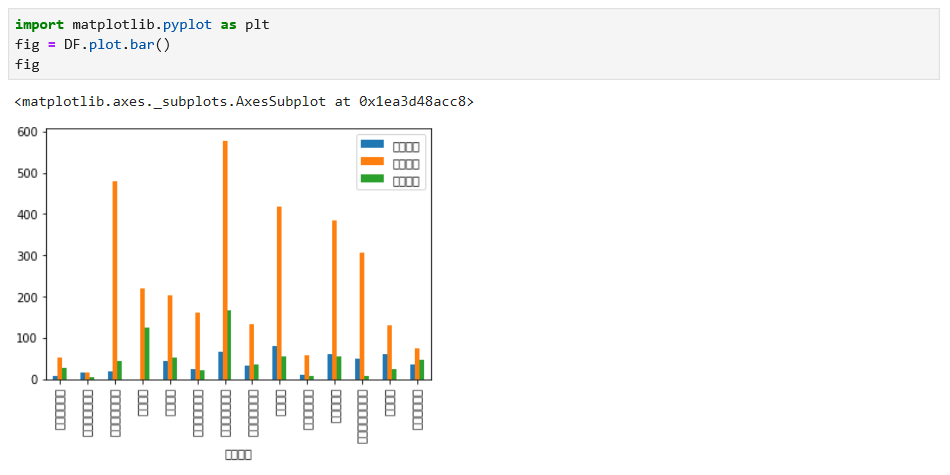
针对上面的结果,我们发现几个问题:乱码、图表太小
针对这两个问题,我们修改代码进行调整,调整后代码及运行结果如下:
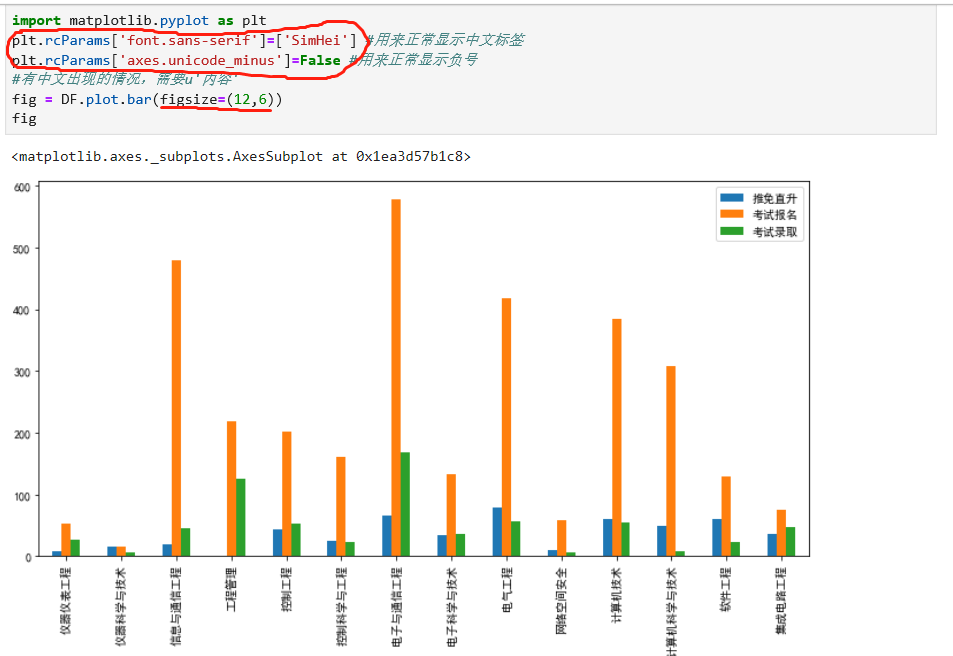
从图标看起来,基本符合我们的要求
7、保存绘图
针对上面绘制的图标进行保存,具体代码如下:

运行该代码后,会在同样的文件下看到多出来一个这样的文件:

找到文件夹的位置,打开该图片查看,如下:
看起来还是相对清晰的,得到了图片,就可以用在其他地方了,例如PPT资料等
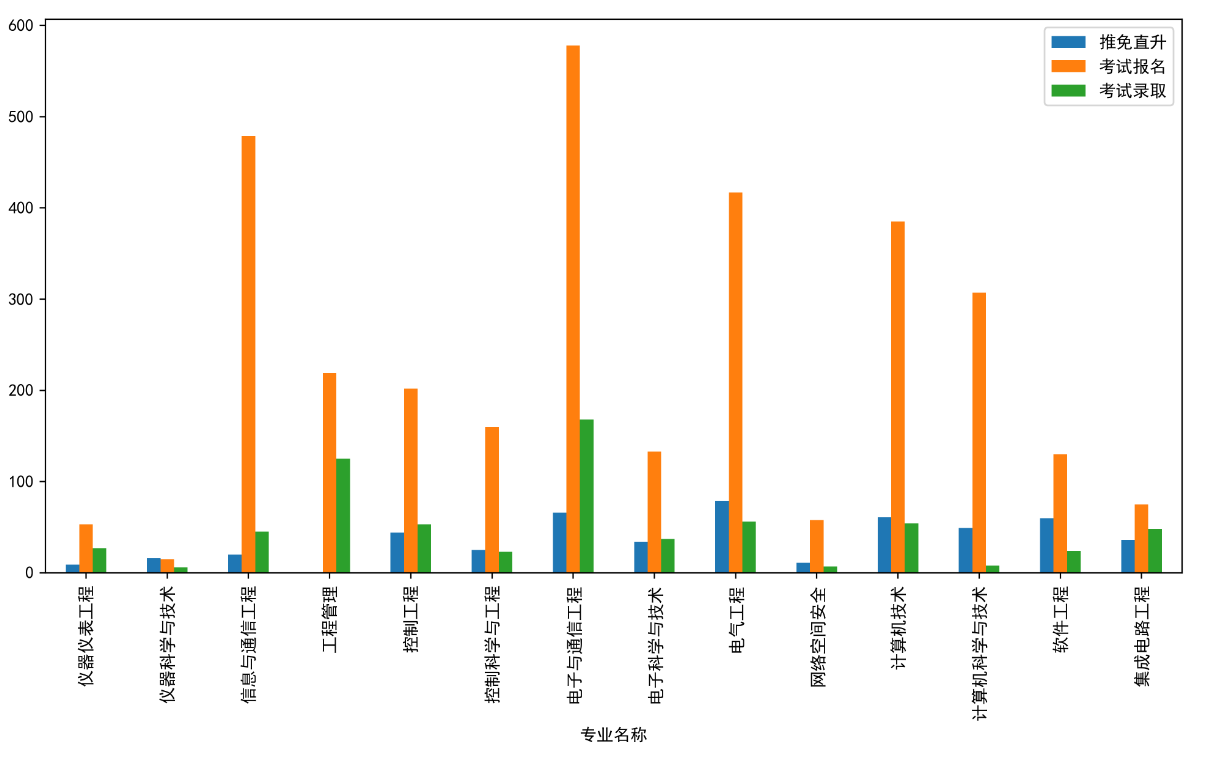
以上,就是针对一个数据从获取-读取-整理-分析-绘图-保存的整个主要流程,其他还有很多细节,但是都离不开这个主要的流程进行
掌握了主要流程,其他的细节就是锦上添花,可以再不断地精进了
以上就是本章重点内容示例的说明,祝学习愉快
以下链接,可以供你了解这个系列学习笔记的所有章节最新进度