Spark中完成图挖掘经常以GraphX作为工具,我们以金融领域中常见的集团派系图谱为例子,学习Spark完成图挖掘工作。
为了更直接表达,我们可以先看一张自己造的派系图谱。
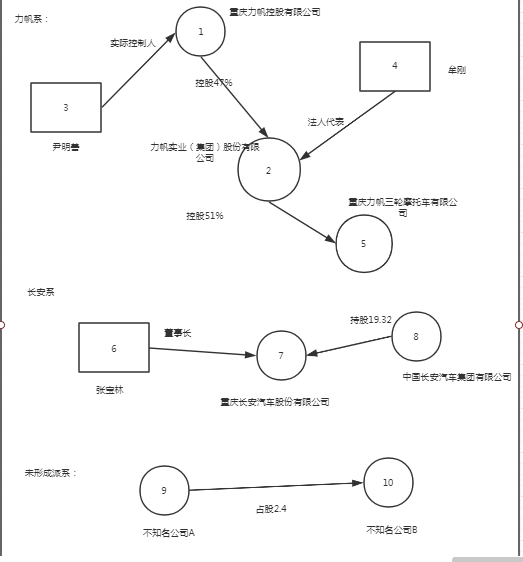
转化成输入数据之后为:
实际控制关系为:
{"_from": 3,"_to": 1,"src_name": "尹明善","dst_name": "重庆力帆控股有限公司","attr": "实际控制"}
投资关系为:
{"_from": 1,"_to": 2,"src_name": "重庆力帆控股有限公司","dst_name": "力帆实业( 集团) 股份有限公司","ratio": 0.47}
{"_from": 2,"_to": 5,"src_name": "力帆实业( 集团) 股份有限公司","dst_name": "重庆力帆三轮摩托车有限公司","ratio": 0.51}
{"_from": 8,"_to": 7,"src_name": "中国长安汽车集团有限公司","dst_name": "重庆长安汽车股份有限公司","ratio": 0.19}
{"_from": 9,"_to": 10,"src_name": "不知名公司A","dst_name": "不知名公司B","ratio": 0.024}
任职关系为:
{"_from": 4,"_to": 2,"src_name": "牟刚","dst_name": "重庆力帆控股有限公司","attr": "法定代表人"}
{"_from": 6,"_to": 7,"src_name": "张宝林","dst_name": "重庆长安汽车股份有限公司","attr": "董事长"}
假设我们规定,投资比例 < 10%,那么该投资关系不被纳入集团派系中,那么代码为:
package com.zhangjunwei
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.json4s.jackson.JsonMethods.{parse}
import com.zhangjunwei.utils.Parser.getJsonValue
import org.apache.spark.graphx._
object GroupFaction {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "D:/winutils/")
val sparkConf = new SparkConf()
sparkConf.setAppName("GroupFaction")
sparkConf.setMaster("local")
val sparkContext = new SparkContext(sparkConf)
// 读取投资数据
val invest: RDD[String] = sparkContext.textFile("input/GroupFaction/invest")
// 读取任职数据
val officer: RDD[String] = sparkContext.textFile("input/GroupFaction/officer")
// 读取实际控制人数据
val actual_controller: RDD[String] = sparkContext.textFile("input/GroupFaction/actual_controller")
// 过滤投资比例 <= 10%的数据
val invest_relation: RDD[String] = invest.filter(line => {
val jv = parse(line)
val ratio = getJsonValue(jv, "ratio").toDouble
if (ratio > 0.1) true else false
})
// 聚合所有符合条件的关系
val relations: RDD[String] = invest_relation.union(officer).union(actual_controller)
// 构造GraphX中Edge对象
val edges = relations.map(relation => {
val jv = parse(relation)
val from = getJsonValue(jv, "_from").toLong
val to = getJsonValue(jv, "_to").toLong
Edge(from, to, relation)
})
// 根据边构造图
val graph: Graph[String, String] = Graph.fromEdges(edges, defaultValue = "")
// 获取联通分量
val connetedGraph: Graph[VertexId, String] = graph.connectedComponents()
// 将同一连通分量中各个边聚合
val tripleGroup: RDD[(VertexId, Set[EdgeTriplet[VertexId, String]])] = connetedGraph.triplets.map(t => (t.srcAttr, Set(t)))
.reduceByKey(_ ++ _).repartition(1)
// 对同一联通分量进行格式处理
val groups: RDD[(String, Set[String])] = tripleGroup.map { case (vertexId, edges) => {
val edges_attr: Set[String] = edges.map(e => e.attr)
("集团派系/" + vertexId.toString, edges_attr)
}
}
//保存结果
groups.saveAsTextFile("output/group")
}
}
这里的关键在于connectedComponents的算法。它会返回一个图中联通分量,其中vertexId为该联通分量中最小的顶点ID。
connectedComponents的算法原理使用pregel机制。关于pregel机制后期再做记录。