一、mock
什么是mock:模拟数据进行测试,假数据,不是接口真正返回的数据
为什么要使用mock:1.接口还没完成,2.第三方的不方便直接调用的
客户端mock:pip insatall mock
# 要测试add函数 def add(a,b): pass class TestAdd(unittest.TestCase): def test_add(self): # 变量命名成被测试的函数名称,mock中填写被测试函数返回值 # 等接口完成后,注释掉mock语句 add = Mock(return_value=7) self.assertEqual(7,add(3,4))
# 用requests封装的函数时,这个函数没完成,直接用mock模拟 import requests from unittest import mock def request_lemonfix(): res = requests.get('http://www.lemonfix.com') return res.status_code.encode('utf-8') if __name__ == '__main__': request_lemonfix = mock.Mock(return_value="这里会显示论坛主页") print(request_lemonfix())
二、正则表达式
--为了匹配字符串,替换字符串
--是一门通用的技术,与语言无关
re:python自带的标准库,不需要安装
# 正则表达式通常在匹配方式前加r,如下不加r默认 是换行
# 正则表达式中不要随便加空格
match 从最开始的地方进行匹配
earch 可以在任意地方匹配,只匹配到第一个
记录匹配位置 start(),end()
""" regular expression ==>re==》regx==>正则表达式 """ import re my_string = "xiaolingwangleling" # 正则表达式通常在匹配方式前加r,如下不加r默认 是换行 # 正则表达式中不要随便加空格 print("a b") print(r"a b") # a b # match 从最开始的地方进行匹配 print(re.match(r"ling",my_string)) # None # search 可以在任意地方匹配,只匹配到第一个 res = re.search(r"ling",my_string) print(res) # <re.Match object; span=(4, 8), match='ling'> print(res.group()) # ling print(res.start()) # 4 匹配开始索引 print(res.end()) # 8 匹配结束索引 # find_all 可以在任意地方匹配,匹配到所有 print(re.findall(r"ling",my_string)) # ['ling', 'ling']
1)正则表达式语法
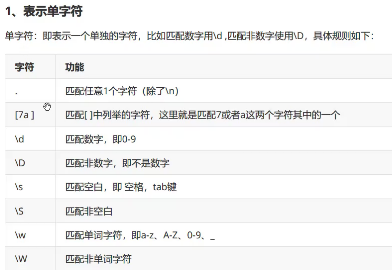

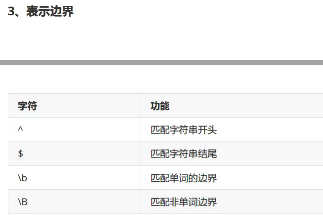
my_string = "_@_xiaoling256wangkkkkle88ling" # .匹配一个字符,除了 print(re.search(r".",my_string)) # x # a. print(re.search(r"a.",my_string)) # ao # []代表匹配里面的某一个,[abc],要么匹配a,要么匹配b,要么匹配c print(re.search(r"[oge]",my_string)) # d表示匹配一个数字 、D表示非数字 print(re.search(r"d",my_string)) print(re.search(r"D",my_string)) # [0-9]和d等价 print(re.search(r"[0-9]",my_string)) # w匹配大小写字母,0-9 下划线_ W 匹配非单词字符 print(re.search(r"w",my_string)) print(re.search(r"www",my_string)) print(re.search(r"W",my_string)) # * 表示前面字符0次或者任意次 print(re.search(r"d*",my_string)) # 匹配0次和任意次就随机的 print(re.search(r".*",my_string)) # + 表示前面字符1次或者任意次,尽可能多的匹配(贪婪模式) print(re.search(r"d+",my_string)) # ?匹配1次或者0次(随机) 通常的用法表示非贪婪模式 print(re.search(r"d+?",my_string)) # {m}匹配多少次 print(re.search(r"k{2}",my_string)) print(re.search(r"k{2,}",my_string)) print(re.search(r"k{2,}?",my_string))
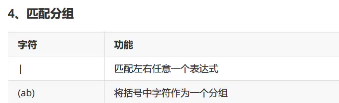
group重点
login_data = '{"member_id": #member_id#,"amount":#money#}' # 不加括号只有一个组,#member_id# pattern = r"#.+?#" print(re.search(pattern,login_data).group(0)) # 加括号有两个分组,group(0)d代表#member_id#,group(1)代表括号里的部分member_id,有多少括号就有多少分组 pattern = r"#(.+?)#" print(re.search(pattern,login_data).group(0)) print(re.search(pattern,login_data).group(1))
替换用例中的#
login_data = '{"member_id": #member_id#,"amount":#money#}' pattern = r"#.+?#" print(re.search(pattern,login_data)) # 替换 result = re.sub(pattern,"19876",login_data,count=1) print(result) result = re.sub(pattern,"10000",result,count=1) print(result)
封装
def replace_data(self,data): pattern = r"#(.+?)#" while re.search(pattern,data): key = re.search(pattern,data).group(1) value = getattr(self,key,"") data = re.sub(pattern,str(value),data,count=1) return data