最近在研究HDFS,主要是通过看<Hadoop: The Definitive Guide>一书的第四版,现在就书中的要点做下总结。
1、HDFS是什么?
HDFS全称Hadoop Distributed File System,是一种分布式文件系统,
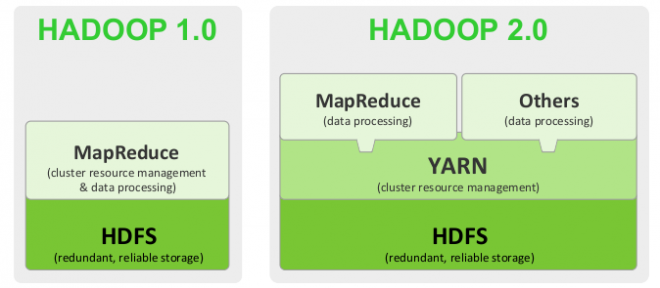
是Hadoop项目的核心子项目,在Hadoop 2.0引入了资源管理框架Yarn后,其上除了可以使用MapReduce计算框架,也可以为Spark、Storm等其他框架使用。

2、HDFS适合那些场景,不适合那些场景?
适合非常大的数据文件,流式数据访问和廉价的集群硬件;
不适合低延迟数据访问,许多小文件和多用户对同一文件的修改。
3、HDFS基本概念
Blocks:HDFS最基本的存储单元,默认大小为128MB,超过128MB的数据被存在多个Block中,可以存储在不同节点中,小于128MB的文件例如1MB存在1个block,占用空间为1MB。
每一个block会在多个datanode上存储多份副本,默认是3份。
Namenode:通常工作的只有1个,它通过本地文件系统中的namespace image和edit log 2个文件管理文件系统的命名空间,维护文件系统树和树里面的文件元数据和目录。因为Namenode宕机后,整个HDFS文件系统会不可用,为了保持高可用性,通常在不同的物理机会有一个secondary namenode,会保留namespace image和edit log 2个文件的备份,一旦Namenode宕机,则secondary namenode会成为新的Namenode。
Datanodes:通常有多个,主要用于存储blocks。
Block Caching:一般Datanode从磁盘中读取blocks,但是对于经常使用的文件,其blocks会缓存到datanode的内存中。
4、Hadoop支持哪些文件系统?
Hadoop有一个抽象概念的文件系统,提供了文件系统实现的各类接口,HDFS只是这个抽象文件系统的一个实例。

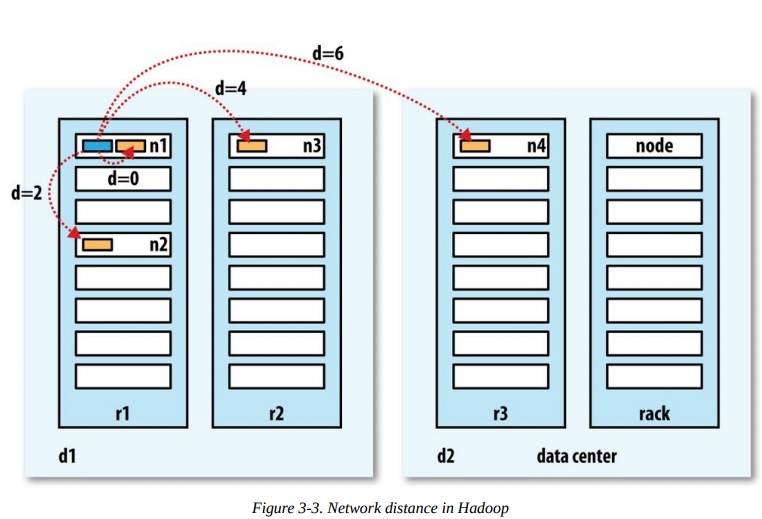
5、HDFS中网络距离计算规则
distance(/d1/r1/n1, /d1/r1/n1) = 0 (processes on the same node)
distance(/d1/r1/n1, /d1/r1/n2) = 2 (different nodes on the same rack)
distance(/d1/r1/n1, /d1/r2/n3) = 4 (nodes on different racks in the same data center)
distance(/d1/r1/n1, /d2/r3/n4) = 6 (nodes in different data centers)
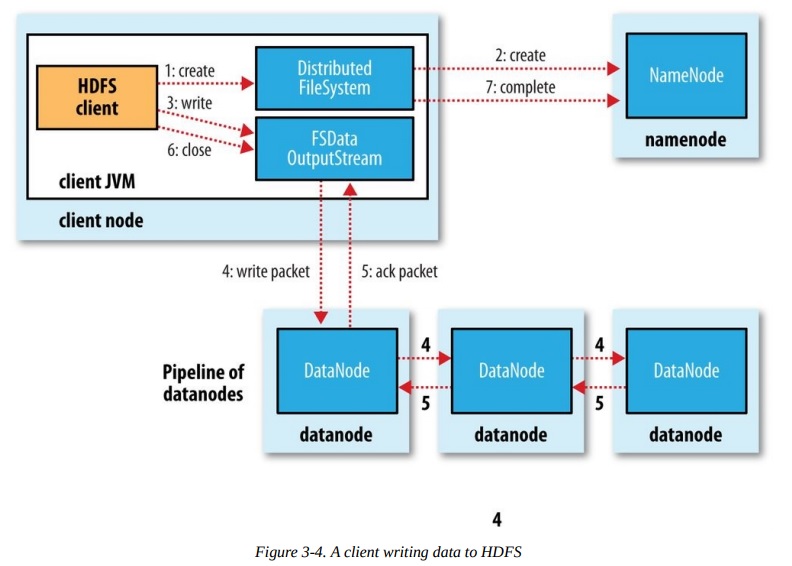
6、解剖HDFS文件读取和文件写入
读取:Client从namenode获取block信息,然后根据网络距离计算最优block位置按照顺序一个个先后读取block数据。

写入:Client从namenode获取创建的outputstream,然后负责写主block,主block负责写第一个备份block,第一个备份block负责写第二个备份block
第二个备份block写完毕后ACK到第一个备份block,第一个备份block然后ACK到主block,主block返回ACK给Client。
HDFS写入数据时针对单个block的三个副本位置选择:
Hadoop的默认策略是将第一个副本放在与客户端相同的节点上,(对于在外部运行的客户端集群,随机选择一个节点,尽管系统尝试不选择太满或太忙的节点)。
该第二副本放置在与第一个副本不同的机架上,第三个副本被放置在与第二个相同的机架,但是在随机选择的不同节点上。
当一个datanode宕机后,该datanode节点会被删除,其他节点存储的block副本会被复制到其他datanode,这样该block副本数还是3个。

7、HDFS文件系统应该如何调用?
HDFS系统仅允许有权限的用户访问,具体见http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsPermissionsGuide.html#Changes_to_the_File_System_API
1)命令行方式:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
2)Java API:http://hadoop.apache.org/docs/current/api/index.html
大牛的调用案例见 http://blog.csdn.net/u010156024/article/details/50113273
3)WebHDFS REST API:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
铸剑团队签名:
【总监】十二春秋之,3483099@qq.com;
【Master】戈稻不苍,han169@126.com;
【Java开发】雨鸶,343691194@qq.com;思齐骏惠,qiangzhang1227@163.com;小王子,545106057@qq.com;巡山小钻风,840260821@qq.com;
【VS开发】豆点,2268800211@qq.com;
【系统测试】土镜问道,847071279@qq.com;尘子与自由,695187655@qq.com;
【大数据】沙漠绿洲,caozhipan@126.com;张三省,570417591@qq.com;
【网络】夜孤星,11297761@qq.com;
【系统运营】三石头,261453882@qq.com;平凡怪咖,591169003@qq.com;
【容灾备份】秋天的雨,18568921@qq.com;
【安全】保密,你懂的。
原创作者:张三省
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。