http://poj.org/problem?id=2528
Description
- Every candidate can place exactly one poster on the wall.
- All posters are of the same height equal to the height of the wall; the
width of a poster can be any integer number of bytes (byte is the unit of length
in Bytetown).
- The wall is divided into segments and the width of each segment is one byte.
- Each poster must completely cover a contiguous number of wall segments.
They have built a wall 10000000 bytes long (such that there is enough place for all candidates). When the electoral campaign was restarted, the candidates were placing their posters on the wall and their posters differed widely in width. Moreover, the candidates started placing their posters on wall segments already occupied by other posters. Everyone in Bytetown was curious whose posters will be visible (entirely or in part) on the last day before elections.
Your task is to find the number of visible posters when all the posters are placed given the information about posters' size, their place and order of placement on the electoral wall.
Input
Output
The picture below illustrates the case of the sample input.
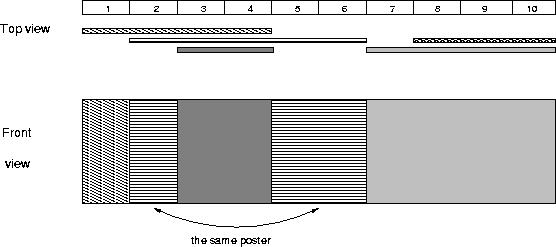
Sample Input
1 5 1 4 2 6 8 10 3 4 7 10
Sample Output
4
大致题意:
有一面墙,被等分为1QW份,一份的宽度为一个单位宽度。现在往墙上贴N张海报,每张海报的宽度是任意的,但是必定是单位宽度的整数倍,且<=1QW。后贴的海报若与先贴的海报有交集,后贴的海报必定会全部或局部覆盖先贴的海报。现在给出每张海报所贴的位置(左端位置和右端位置),问张贴完N张海报后,还能看见多少张海报?(PS:看见一部分也算看到。)
解题思路:
区间压缩映射(离散化)+ 线段树+简单哈希
首先建立模型:
给定一条数轴,长度为1QW,然后在数轴上的某些区间染色,第i次对区间染色为i,共染色N次。给出每次染色的区间,问最后能看见多少种颜色。
常规思路:
若第i次在区间[ai , bi]染色,则把[ai , bi]的每一格都染色为i。后染的颜色覆盖先染的颜色。由于染色N次,定义一个标记数组hh,从数轴第一格开始检查,一直检查到最后,出现过得颜色则记录到hh,最后统计hh中不同颜色的个数,就是所求。
数据规模太大,必定TLE。
应该用线段树去求解,这题只是线段树的入门水题,不懂线段树的同学去找一些相关资料大概学习一下,然后看一下我代码中注释,这题就有思路做了。我推荐你们去看看“浙江大学acm校队”的关于线段树的PPT,里面有线段树从入门到精通的案例,也有涉及离散化的介绍,百度搜就有了。
然后我这里补充几点线段树的知识,网上关于线段树的资料很多有误导。
1、 线段树是二叉树,且必定是平衡二叉树,但不一定是完全二叉树。
2、 对于区间[a,b],令mid=(a+b)/2,则其左子树为[a,mid],右子树为[mid+1,b],当a==b时,该区间为线段树的叶子,无需继续往下划分。
3、 线段树虽然不是完全二叉树,但是可以用完全二叉树的方式去构造并存储它,只是最后一层可能存在某些叶子与叶子之间出现“空叶子”,这个无需理会,同样给空叶子按顺序编号,在遍历线段树时当判断到a==b时就认为到了叶子,“空叶子”永远也不会遍历到。
4、 之所以要用完全二叉树的方式去存储线段树,是为了提高在插入线段和搜索时的效率。用p*2,p*2+1的索引方式检索p的左右子树要比指针快得多。
5、线段树的精髓是,能不往下搜索,就不要往下搜索,尽可能利用子树的根的信息去获取整棵子树的信息。如果在插入线段或检索特征值时,每次都非要搜索到叶子,还不如直接建一棵普通树更来得方便。
但是这题单纯用线段树去求解一样不会AC,原因是建立一棵[1,1QW]的线段树,其根系是非常庞大的,TLE和MLE是铁定的了。所以必须离散化。
通俗点说,离散化就是压缩区间,使原有的长区间映射到新的短区间,但是区间压缩前后的覆盖关系不变。举个例子:
有一条1到10的数轴(长度为9),给定4个区间[2,4] [3,6] [8,10] [6,9],覆盖关系就是后者覆盖前者,每个区间染色依次为 1 2 3 4。
现在我们抽取这4个区间的8个端点,2 4 3 6 8 10 6 9
然后删除相同的端点,这里相同的端点为6,则剩下2 4 3 6 8 10 9
对其升序排序,得2 3 4 6 8 9 10
然后建立映射
2 3 4 6 8 9 10
↓ ↓ ↓ ↓ ↓ ↓ ↓
1 2 3 4 5 6 7
那么新的4个区间为 [1,3] [2,4] [5,7] [4,6],覆盖关系没有被改变。新数轴为1到7,即原数轴的长度从9压缩到6,显然构造[1,7]的线段树比构造[1,10]的线段树更省空间,搜索也更快,但是求解的结果却是一致的。
离散化时有一点必须要注意的,就是必须先剔除相同端点后再排序,这样可以减少参与排序元素的个数,节省时间。
附:海报张数上限为10000,即其端点映射的新数轴长度最多为20000。因此建立长度为1QW的离散数组dis时,可以使用unsigned short类型,其映射值最多为20000,这样可以节约空间开销。
解题:这个题坑死我了,气死了,WA了20+,原因是自己首先是思路有问题,之后是脑残了,你妹10000个点,我开他丫的100001的数组还是WA,我一直找不到
我哪里错了,一直RE,最后发现是我的hash[i]函数出了问题(手残啊),因为1 <= line[i].l<= line[i].r<= 10000000.所以hash[i]函数开小了。
#include <iostream> #include <string.h> #include <stdio.h> #include <stdlib.h> #include <algorithm> #define N 10001 using namespace std; struct node { int l,r; int lz; } q[8*N];//为什么4*N不行?,因为最多有2*N个点 struct Line { int x,y; } line[N];//用来存储画幅的左边界与右边界 int X[2*N],hh[2*N],hash[10000001]; int tt,ll; void build(int l,int r,int rt) { q[rt].l=l; q[rt].r=r; q[rt].lz=0; if(l==r) return ; build(l,(l+r)/2,rt*2); build((l+r)/2+1,r,rt*2+1); return ; } void pushdown(int rt) { if(q[rt].lz) { q[rt*2].lz=q[rt].lz; q[rt*2+1].lz=q[rt].lz; q[rt].lz=0; } } void update(int lf,int rf,int l,int r,int rt,int key) { if(lf<=l&&rf>=r) { q[rt].lz=key; return ; } pushdown(rt); if(lf<=(l+r)/2) update(lf,rf,l,(l+r)/2,rt*2,key); if(rf>(l+r)/2) update(lf,rf,(l+r)/2+1,r,rt*2+1,key); return ; } void query(int l,int r,int rt) { if(q[rt].lz) { if(hh[q[rt].lz]==0) { hh[q[rt].lz]=1; ll++; } return ; } pushdown(rt); query(l,(l+r)/2,rt*2); query((l+r)/2+1,r,rt*2+1); return ; } int main() { int T,n; cin>>T; while(T--) { tt=0; ll=0; cin>>n; for(int i=0; i<n; i++) { cin>>line[i].x>>line[i].y; X[tt++]=line[i].x; X[tt++]=line[i].y; } sort(X,X+tt); int sum=unique(X,X+tt)-X;//去重点 build(0,sum-1,1); for(int i=0; i<sum; i++)//离散化 { hash[X[i]]=i;//就因为数组开小了,整整一天时间啊 } for(int i=0; i<n; i++) { update(hash[line[i].x],hash[line[i].y],0,sum-1,1,i+1); } memset(hh,0,sizeof(hh)); query(0,sum-1,1); printf("%d ",ll); } return 0; }
#include <iostream> #include <stdio.h> #include <string.h> #include <stdlib.h> #include <algorithm> #define N 10010 #define ll long long using namespace std; struct li { int x,y; } line[N]; struct node { int l,r; ll lz; } q[8*N]; int n,tt,L,X[2*N],hh[2*N],hash[10000010]; void pushdown(int rt) { if(q[rt].lz) { q[rt<<1].lz=q[rt].lz; q[rt<<1|1].lz=q[rt].lz; q[rt].lz=0; } } void build(int l,int r,int rt) { q[rt].l=l; q[rt].r=r; q[rt].lz=0; if(l==r) return ; int mid=(l+r)>>1; build(l,mid,rt<<1); build(mid+1,r,rt<<1|1); //这里必须是mid+1,否则不能写成位运算 return ; } void update(int lf,int rf,int l,int r,int rt,int key) { if(lf<=l&&rf>=r) { q[rt].lz=key; return ; } pushdown(rt); int mid=(l+r)>>1; if(lf<=mid) update(lf,rf,l,mid,rt<<1,key); if(rf>mid) update(lf,rf,mid+1,r,rt<<1|1,key); return ; } void query(int l,int r,int rt) { if(q[rt].lz) { if(hh[q[rt].lz]==0) { hh[q[rt].lz]=1; L++; } return ; } int mid=(l+r)>>1; query(l,mid,rt<<1); query(mid+1,r,rt<<1|1); return ; } int main() { int T; scanf("%d",&T); while(T--) { tt=0; L=0; scanf("%d",&n); for(int i=0; i<n; i++) { scanf("%d%d",&line[i].x,&line[i].y); X[tt++]=line[i].x; X[tt++]=line[i].y; } sort(X,X+tt); int sum=unique(X,X+tt)-X; build(0,sum-1,1); for(int i=0; i<sum; i++) { hash[X[i]]=i; } for(int i=0; i<n; i++) { update(hash[line[i].x],hash[line[i].y],0,sum-1,1,i+1); } memset(hh,0,sizeof(hh)); query(0,sum-1,1); printf("%d ",L); } return 0; }