并发上传
基于py自带模块
concurrent.futures import ThreadPoolExecutor
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # @Time: 2020/11/22 10:13 # @Author:zhangmingda # @File: ks3_multi_thread_for_concurrent.futures.ThreadPoolExecutor.py # @Software: PyCharm # Description: 本地文件/目录 上传到KS3 import math import os import sys from ks3.connection import Connection from filechunkio import FileChunkIO from concurrent.futures import ThreadPoolExecutor, as_completed class Ks3Pusher(object): def __init__(self, ak, sk, bucket_name, host, block_threshold=100, partsize=100, files_thread_count=10, part_thread_num=10): self.ak = ak self.sk = sk self.bucket_name = bucket_name self.host = host self.block_threshold_bytes = block_threshold * 1024 * 1024 self.partsize = partsize * 1024 * 1024 self.retry_times = 3 self.files_thread_count = files_thread_count self.part_thread_num = part_thread_num # self.conn = Connection(self.ak, self.sk, host=self.host) def __initialize(self): conn = Connection(self.ak, self.sk, host=self.host) self.b = conn.get_bucket(self.bucket_name) def list_dir(self, abs_dir, prefix=''): file_list = [] for file_or_dir in os.listdir(abs_dir): sub_relative_path = os.path.join(abs_dir, file_or_dir) # 子目录查找文件 if os.path.isdir(sub_relative_path): ks3_prefix = os.path.join(prefix, file_or_dir) # print('发现子目录:%s ' % ks3_prefix) # 递归查找最子目录,获取文件列表,最后合并子目录文件 file_list += self.list_dir(sub_relative_path, prefix=ks3_prefix) # 文件获取绝对路径和ks3要存的名字 elif os.path.isfile(sub_relative_path): file_abspath = os.path.abspath(sub_relative_path) ks3_key = os.path.join(prefix, file_or_dir) ks3_key = '/'.join(ks3_key.split('\')) # print('%s is file' % file_abspath) # 列表添加元素 file_list.append((file_abspath, ks3_key)) # print('目录:%s' % abs_dir,file_list) return file_list def push(self,local_path,prefix='',file_acl='private'): """ :param local_path:本地路径 :param prefix: 前缀,或者ks3 key :param file_acl: 文件权限 :return: """ self.__initialize() abspath = os.path.abspath(local_path) if os.path.isfile(abspath): ks3_key = os.path.join(prefix, os.path.basename(abspath)) ks3_key = '/'.join(ks3_key.split('\')) if os.stat(abspath).st_size < self.block_threshold_bytes: self.put(abspath, ks3_key=ks3_key, file_acl=file_acl) else: self.multi_put(abspath, ks3_key=ks3_key, file_acl=file_acl) elif os.path.isdir(abspath): thread_task_list = [] all_file_list = self.list_dir(abspath, prefix=prefix) # print(all_file_list) # 构建线程池实例 tp = ThreadPoolExecutor(max_workers=self.files_thread_count) small_file_list = [] # 全部添加到任务队列开始处理 for args in all_file_list: # 判断是否使用分块上传 if os.stat(args[0]).st_size < self.block_threshold_bytes: small_file_list.append(args) else: # self.multi_put(*args, file_acl) # 遇到大文件就开始传 thread_task_list.append(tp.submit(self.multi_put, *args, file_acl)) # 大文件加入并发任务列表 # 小文件并发上传 for small_file in small_file_list: thread_task_list.append(tp.submit(self.put, *small_file, file_acl)) # 小文件加入并发任务列表 # 等待所有线程结束,获取全部线程的执行结果 [part_thread.result() for part_thread in as_completed(thread_task_list)] def put(self,file_path,ks3_key,file_acl='private'): for i in range(self.retry_times): try: k = self.b.new_key(ks3_key) ret = k.set_contents_from_filename(file_path, policy=file_acl) if ret and ret.status == 200: if i: print("%s 重试第%s次上传成功" % (ks3_key,i)) break print("%s 上传成功" % ks3_key) break else: if i + 1 >= self.retry_times: # print("%s RECV code:%s" % (ks3_key, ret.status)) raise ret.status except Exception as e: print("%s 上传失败, Error: %s " % (ks3_key,e)) def upload_part_task(self, mp, file_path, ks3_key, offset, chunk_size, part_num): """ :param mp: KS3 会话实例 :param file_path: 本地文件名 :param ks3_key: ks3存储的文件名 :param offset: 起始字节点 :param chunk_size: 块大小 :param part_num: 块儿ID :param retry_times: 单块失败重试次数 :return: """ cur_task_ret = False try: for i in range(self.retry_times): try: with FileChunkIO(file_path, 'rb', offset=offset, bytes=chunk_size) as fp: mp.upload_part_from_file(fp, part_num=part_num) cur_task_ret = True if i: print("%s part -----> %d retry %s times upload success" % (ks3_key, part_num, i)) else: print("%s part -----> %d upload success" % (ks3_key, part_num)) break except BaseException as e: print("%s part %d upload_id=%s,error=%s" % ( ks3_key, part_num, mp.id, e)) if i + 1 >= self.retry_times: print("%s part %d upload fail" % (ks3_key, part_num)) raise e except BaseException as e: cur_task_ret = False finally: return {part_num: cur_task_ret} def multi_put(self, file_path, ks3_key=None, file_acl="private"): """ :param file_path:本地文件路径 :param ks3_key:ks3名称 :param file_acl: 文件权限 :return: """ # 分块任务列表 thread_list = [] # 每个块儿的上传结果 multi_chunk_result = {} # 如果没有给KS3上面的文件命名,就获取原名字 if not ks3_key: ks3_key = os.path.basename(file_path) f_size = os.stat(file_path).st_size mp = self.b.initiate_multipart_upload(ks3_key, policy=file_acl) if not mp: raise RuntimeError("%s init multiupload error" % ks3_key) print("%s begin multipart upload,uploadid=%s" % (ks3_key, mp.id)) chunk_size = self.partsize chunk_count = int(math.ceil(f_size / float(chunk_size))) pool_args_list = [] try: for i in range(chunk_count): offset = chunk_size * i bs = min(chunk_size, f_size - offset) part_num = i + 1 # 将一个文件划分的所有块儿任务,添加到任务列表 pool_args_list.append((mp, file_path, ks3_key, offset, bs, part_num)) # 构建线程池实例 tp = ThreadPoolExecutor(max_workers=self.part_thread_num) # 全部添加到任务队列开始处理 [thread_list.append(tp.submit(self.upload_part_task, *args)) for args in pool_args_list] # 等待所有线程结束,获取全部线程的执行结果 [multi_chunk_result.update(part_thread.result()) for part_thread in as_completed(thread_list)] # 上传总结 # 如果任务数和块儿数对不上,报一下出入 if len(multi_chunk_result) != chunk_count: raise RuntimeError( "%s part miss,expect=%d,actual=%d" % (ks3_key, chunk_count, len(multi_chunk_result))) # 如果任务都完毕,检查是否有失败的块儿 for item in multi_chunk_result.keys(): if not multi_chunk_result[item]: raise RuntimeError("%s part upload has fail" % ks3_key) # 总结都OK,完成上传做合并动作 mp.complete_upload() print("%s multipart upload success" % ks3_key) return "%s multipart upload success" % ks3_key except BaseException as e: print("%s multipart upload fail err:%s" % (ks3_key,e)) if mp: mp.cancel_upload() raise e if __name__ == '__main__': # Connect to KS3 ak = 'XXXXXXXXXXXXXXXXXXX' sk = 'XXXXXXXXXXXXXXXXXXXXXX' backet_name = 'XXXXXXXXXX' host = 'ks3-cn-beijing.ksyun.com' # host = 'ks3-cn-beijing-internal.ksyun.com' # 用法提示 if len(sys.argv) < 2: exit('Usage: python %s <file or directory>' % sys.argv[0]) # 本地文件/目录路径 path_name = sys.argv[1] if not os.path.exists(path_name): exit("%s not exists" % path_name) # input_path = os.path.abspath(path_name) # ks3 上传的前缀(虚拟目录名) prefix = 'opt' # object policy : 'private' or 'public-read' object_policy = 'public-read' # 多文件并发上传数 files_thread_count = 10 # 单文件并发分块线程数 part_thread_num = 10 # 分块上传阈值,单位MB block_threshold = 10 # 分块大小设置,单位MB https://docs.ksyun.com/documents/943 partsize = 10 # (当所有块总大小大于5M时,除了最后一个块没有大小限制外,其余的块的大小均要求在5MB以上。) # (当所有块总大小小于5M时,除了最后一个块没有大小限制外,其余的块的大小均要求在100K以上。如果不符合上述要求,会返回413状态码。) # (总的分块个数不能超过10000块儿) kpusher = Ks3Pusher(ak=ak, sk=sk, bucket_name=backet_name,host=host, block_threshold=block_threshold, partsize=partsize, files_thread_count=files_thread_count, part_thread_num=part_thread_num ) kpusher.push(path_name, prefix=prefix, file_acl=object_policy)
基于 threadpool
#!/usr/bin/env python3 # -*- coding:utf-8 -*- # @Time: 2020/11/22 10:13 # @Author:zhangmingda # @File: ks3_multi_thread_for_threadpool.py # @Software: PyCharm # Description: 本地文件/目录 上传到KS3 import math import os import sys from ks3.connection import Connection from filechunkio import FileChunkIO import threadpool class Ks3Pusher(object): def __init__(self, ak, sk, bucket_name, host, block_threshold=100, partsize=100, files_thread_count=10, part_thread_num=10): self.ak = ak self.sk = sk self.bucket_name = bucket_name self.host = host self.block_threshold_bytes = block_threshold * 1024 * 1024 self.partsize = partsize * 1024 * 1024 self.retry_times = 3 self.files_thread_count = files_thread_count self.part_thread_num = part_thread_num self.file_acl = 'private' # self.conn = Connection(self.ak, self.sk, host=self.host) def __initialize(self): conn = Connection(self.ak, self.sk, host=self.host) self.b = conn.get_bucket(self.bucket_name) def list_dir(self, abs_dir, prefix=''): file_list = [] for file_or_dir in os.listdir(abs_dir): sub_relative_path = os.path.join(abs_dir, file_or_dir) # 子目录查找文件 if os.path.isdir(sub_relative_path): ks3_prefix = os.path.join(prefix, file_or_dir) # print('发现子目录:%s ' % ks3_prefix) # 递归查找最子目录,获取文件列表,最后合并子目录文件 file_list += self.list_dir(sub_relative_path, prefix=ks3_prefix) # 文件获取绝对路径和ks3要存的名字 elif os.path.isfile(sub_relative_path): file_abspath = os.path.abspath(sub_relative_path) ks3_key = os.path.join(prefix, file_or_dir) ks3_key = '/'.join(ks3_key.split('\')) # print('%s is file' % file_abspath) # 列表添加元素 file_list.append(([file_abspath, ks3_key, self.file_acl], None)) # print('目录:%s' % abs_dir,file_list) return file_list def push(self,local_path,prefix='',file_acl='private'): """ :param local_path:本地路径 :param prefix: 前缀,或者ks3 key :param file_acl: 文件权限 :return: """ self.file_acl = file_acl self.__initialize() abspath = os.path.abspath(local_path) if os.path.isfile(abspath): ks3_key = os.path.join(prefix, os.path.basename(abspath)) ks3_key = '/'.join(ks3_key.split('\')) if os.stat(abspath).st_size < self.block_threshold_bytes: self.put(abspath, ks3_key=ks3_key, file_acl=file_acl) else: self.multi_put(abspath, ks3_key=ks3_key, file_acl=file_acl) elif os.path.isdir(abspath): thread_task_list = [] all_file_list = self.list_dir(abspath, prefix=prefix) # print(all_file_list) small_file_list = [] big_file_list = [] # 构建线程池实例 files_pool = threadpool.ThreadPool(self.files_thread_count) # 全部添加到任务队列开始处理 for args in all_file_list: # 判断是否使用分块上传 if os.stat(args[0][0]).st_size < self.block_threshold_bytes: small_file_list.append(args) else: # print(*args[0]) self.multi_put(*args[0]) # big_file_list.append(args) # 初始化任务列表 small_requests = threadpool.makeRequests(self.put, small_file_list) # big_requests = threadpool.makeRequests(self.multi_put, big_file_list) # ***大文件并发,再并发分块。并发分块中全局变量不适合多个文件同时并发*** # 全部添加到任务队列开始处理 [files_pool.putRequest(small_req) for small_req in small_requests] # [files_pool.putRequest(big_req) for big_req in big_requests] # ***大文件并发,再并发分块。并发分块中全局变量不适合多个文件同时并发*** # 等待所有子线程任务结束 files_pool.wait() def put(self,file_path,ks3_key,file_acl='private'): for i in range(self.retry_times): try: k = self.b.new_key(ks3_key) ret = k.set_contents_from_filename(file_path, policy=file_acl) if ret and ret.status == 200: if i: print("%s 重试第%s次上传成功" % (ks3_key,i)) break print("%s 上传成功" % ks3_key) break else: print("%s RECV code:%s" % (ks3_key,ret.status)) except Exception as e: if i+1 >= self.retry_times: print("%s 上传失败, Error: %s " % (ks3_key,e)) def upload_part_task(self, mp, file_path, ks3_key, offset, chunk_size, part_num): """ :param mp: KS3 会话实例 :param file_path: 本地文件名 :param ks3_key: ks3存储的文件名 :param offset: 起始字节点 :param chunk_size: 块大小 :param part_num: 块儿ID :param retry_times: 单块失败重试次数 :return: """ cur_task_ret = False try: for i in range(self.retry_times): try: with FileChunkIO(file_path, 'rb', offset=offset, bytes=chunk_size) as fp: mp.upload_part_from_file(fp, part_num=part_num) cur_task_ret = True if i: print("%s part -----> %d retry %s times upload success" % (ks3_key, part_num, i)) else: print("%s part -----> %d upload success" % (ks3_key, part_num)) break except BaseException as e: print("%s part %d upload_id=%s,error=%s" % ( ks3_key, part_num, mp.id, e)) if i + 1 >= self.retry_times: print("%s part %d upload fail" % (ks3_key, part_num)) raise e except BaseException as e: cur_task_ret = False finally: return {part_num: cur_task_ret} def get_upload_part_result(self,req,result): """ :param req:子线程实例 :param result: 每个线程的返回值 :return: 没必要....没人接收了 """ global multi_chunk_result multi_chunk_result.update(result) def multi_put(self, file_path, ks3_key=None, file_acl="private"): """ :param file_path:本地文件路径 :param ks3_key:ks3名称 :param file_acl: 文件权限 :return: """ # 分块任务列表 thread_list = [] # 每个块儿的上传结果 global multi_chunk_result multi_chunk_result = {} # 如果没有给KS3上面的文件命名,就获取原名字 if not ks3_key: ks3_key = os.path.basename(file_path) f_size = os.stat(file_path).st_size mp = self.b.initiate_multipart_upload(ks3_key, policy=file_acl) if not mp: raise RuntimeError("%s init multiupload error" % ks3_key) print("%s begin multipart upload,uploadid=%s" % (ks3_key, mp.id)) chunk_size = self.partsize chunk_count = int(math.ceil(f_size / float(chunk_size))) pool_args_list = [] try: for i in range(chunk_count): offset = chunk_size * i bs = min(chunk_size, f_size - offset) part_num = i + 1 # 将一个文件划分的所有块儿任务,添加到任务列表 pool_args_list.append(([mp, file_path, ks3_key, offset, bs, part_num], None)) # 构建线程池实例 pool = threadpool.ThreadPool(self.part_thread_num) # 初始化任务列表 requests = threadpool.makeRequests(self.upload_part_task, pool_args_list, self.get_upload_part_result) print('pool.putRequest(req)') # 全部添加到任务队列开始处理 [pool.putRequest(req) for req in requests] # 等待所有子线程任务结束 pool.wait() # [multi_chunk_result.update(part_thread.result()) for part_thread in as_completed(thread_list)] # 上传总结 # 如果任务数和块儿数对不上,报一下出入 if len(multi_chunk_result) != chunk_count: raise RuntimeError( "%s part miss,expect=%d,actual=%d" % (ks3_key, chunk_count, len(multi_chunk_result))) # 如果任务都完毕,检查是否有失败的块儿 for item in multi_chunk_result.keys(): if not multi_chunk_result[item]: raise RuntimeError("%s part upload has fail" % ks3_key) # 总结都OK,完成上传做合并动作 mp.complete_upload() print("%s multipart upload success" % ks3_key) return "%s multipart upload success" % ks3_key except BaseException as e: print("%s multipart upload fail err:%s" % (ks3_key,e)) if mp: mp.cancel_upload() raise e if __name__ == '__main__': # Connect to S3 ak = 'XXXXXXXXXXXXX' sk = 'XXXXXXXXXXXXXXXXXXXXX' backet_name = 'XXXXXXXX' host = 'ks3-cn-beijing.ksyun.com' # host = 'ks3-cn-beijing-internal.ksyun.com' # 本地文件/目录路径 path_name = sys.argv[1] if not os.path.exists(path_name): exit("%s not exists" % path_name) # input_path = os.path.abspath(path_name) # ks3 上传的前缀 prefix = '' # object policy : 'private' or 'public-read' object_policy = 'public-read' # 多文件并发上传数 files_thread_count = 10 # 单文件并发分块线程数 part_thread_num = 10 # 分块上传阈值,单位MB block_threshold = 10 # 分块大小设置,单位MB https://docs.ksyun.com/documents/943 # (当所有块总大小大于5M时,除了最后一个块没有大小限制外,其余的块的大小均要求在5MB以上。) # (当所有块总大小小于5M时,除了最后一个块没有大小限制外,其余的块的大小均要求在100K以上。如果不符合上述要求,会返回413状态码。) partsize = 10 kpusher = Ks3Pusher(ak=ak, sk=sk, bucket_name=backet_name,host=host, block_threshold=block_threshold, partsize=partsize, files_thread_count=files_thread_count, part_thread_num=part_thread_num ) kpusher.push(path_name, prefix=prefix, file_acl=object_policy)
下载断点续传
def download(self, ks3_key): """ :param ks3_key: :return: """ self.__initialize() k = self.b.get_key(ks3_key) filename = os.path.basename(ks3_key) # print(dir(k)) if not os.path.isfile(filename): # 本地不存在这个文件,直接下载 k.get_contents_to_filename(filename) else: # 存在判断本地文件最后修改时间,文件大则 local_file_size = os.stat(filename).st_size # 文件大小 local_file_date = os.stat(filename).st_mtime # 文件最后修改时间 print('本地文件最后修改时间:',time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(local_file_date))) ks3_file_size = int(k.content_length) # KS3文件大小 ks3_file_mdate = k.last_modified # KS3文件最后修改时间GMT ks3_file_mtimestamp = time.mktime(time.strptime(ks3_file_mdate, '%a, %d %b %Y %H:%M:%S GMT')) + 3600 * 8 # KS3文件最后修改时间 print('KS3文件最后更新时间:', time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(ks3_file_mtimestamp) )) if ks3_file_mtimestamp > local_file_date: # 云上文件比本地的新,直接下载 print('云端有更新,更新本地文件!!!') k.get_contents_to_filename(filename) else: # 云上比本地的文件时间老 if local_file_size == ks3_file_size: print('本地和云端文件大小一样,无需重新下载') elif local_file_size > ks3_file_size: print('本地的新文件比云上的还大,避免勿删|覆盖,请确认手动删除。') else: # 本地文件比云上的小,认为是没下载完,进行断点续传 print('已下载%s字节,继续下载.....' % local_file_size) header_plus = { 'Range': 'bytes=%s-' % local_file_size } k.get_contents_to_filename(filename, open_mode='ab', headers=header_plus)
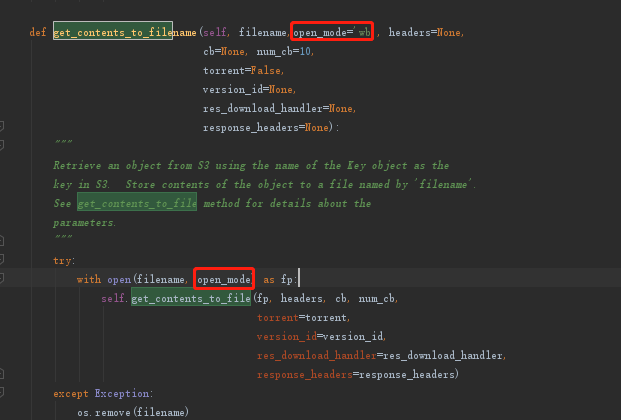
下载断点续传源码需修改处

改为