引言:本文直接翻译自Spark官方网站首页
![]() Lightning-fast cluster computing
Lightning-fast cluster computing
从Spark官方网站给出的标题可以看出:Spark——像闪电一样快的集群计算
Apache Spark™ 是一个应用于大规模数据处理的快速且通用的引擎。
速度
Spark在内存中运行程序的速度比Hadoop MapReduce要快100多倍,在磁盘上则要快10多倍。它使用先进的DAG执行引擎来支持循环数据流和内存计算。
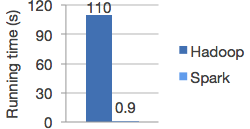
Logistic regression in Hadoop and Spark
易用
用户可以使用Java、Scala或Python语言来快速编写应用程序。Spark提供了80多种高级运算符来帮助用户轻松创建并行应用。而且,用户还可以借助Spark-shell(Scala和Python语言有各自的Spark-shell)来交互地使用Spark。
# Word count in Spark's Python API file = spark.textFile("hdfs://...") file.flatMap(lambda line: line.split()) .map(lambda word: (word, 1)) .reduceByKey(lambda a, b: a+b)
通用性
Spark兼备SQL、流处理以及复杂分析等功能。它为多个高级工具提供驱动,包括数据库框架Spark SQL、机器学习框架MLlib、图运算框架GraphX,以及流处理框架Spark Streaming。用户可以在相同的应用程序中无缝兼备这几种框架。

兼容
Spark可以运行在Hadoop、Mesos、Standalone 或者 Cloud平台之上。它可以访问各种数据源,包括HDFS、HBase、S3,以及Cassandra。用户可以分别使用Standalone集群模式,EC2,Hadoop YARN或者Apache Mesos平台轻松运行Spark。Spark可以从HDFS、HBase、Cassandra,以及其他任何Hadoop数据源中读取数据。

【参考】
1)Spark官方网站 http://spark.apache.org/