import torch.optim as optim
import torch.utils.data as Data
import torch.nn.functional as F
from model.word_2_vector import WordEmbedding
import os
import pandas as pd
from pre_process.dataset_iter import DatasetIter
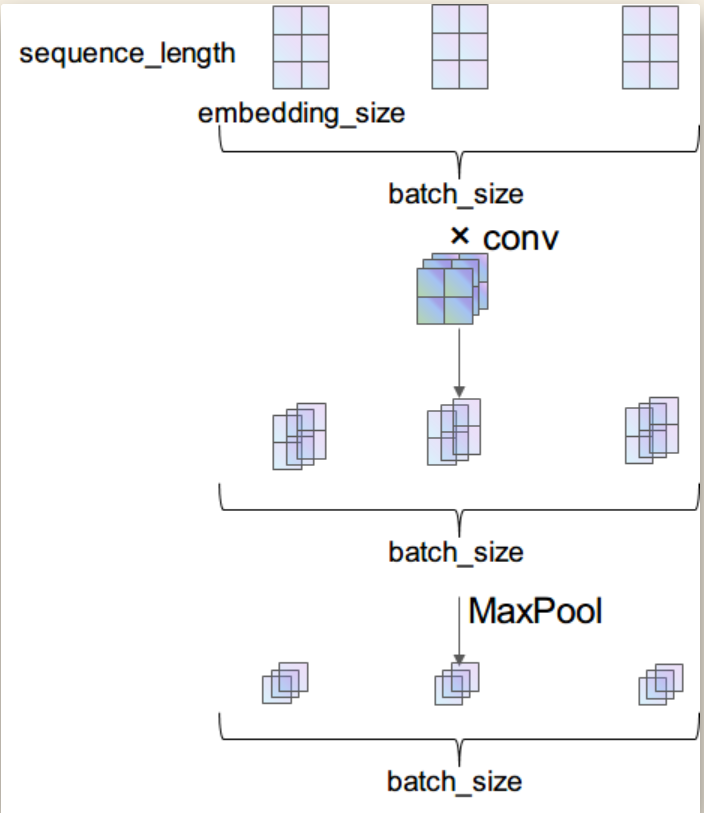
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN, self).__init__()
output_channel = 3
self.conv1 = nn.Sequential(
# conv : [input_channel(=1), output_channel, (filter_height, filter_width), stride=1]
nn.Conv2d(1, output_channel, (10, 128)),
nn.ReLU(),
nn.MaxPool2d((5, 1))
)
self.conv2 = nn.Sequential(
nn.Conv2d(3, 6, (5, 1)),
nn.ReLU(),
nn.MaxPool2d((4,1))
)
self.conv3 = nn.Sequential(
nn.Conv2d(6, 3, (10, 1)),
nn.ReLU(),
nn.MaxPool2d((4,1))
)
# pool : ((filter_height, filter_width))
self.fc = nn.Sequential(
nn.Linear(66, 4),
)
def forward(self, X):
'''
X: [batch_size, sequence_length]
'''
batch_size = X.shape[0]
embedding_X = X # [batch_size, sequence_length, embedding_size]
embedding_X = embedding_X.unsqueeze(1) # add channel(=1) [batch, channel(=1), sequence_length, embedding_size]
conved = self.conv1(embedding_X) # [batch_size, output_channel*1*1]
conve2 = self.conv2(conved)
conve3 = self.conv3(conve2)
flatten = conve3.view(batch_size, -1)
output = self.fc(flatten)
return output
def binary_acc(preds, y):
pred = torch.argmax(preds, dim=1)
correct = torch.eq(pred, y).float()
acc = correct.sum() / len(correct)
return acc
def run_text_cnn():
parent_path = os.path.split(os.path.realpath(__file__))[0]
root = parent_path[:parent_path.find("model")]
BATCH_SIZE = 16
_path = os.path.join(root, "datas", "annotate", "labeled.csv")
data_frame = pd.read_csv(_path, sep="\t")
label = data_frame["labels"]
sentences = data_frame["datas"]
word = WordEmbedding()
dataset = DatasetIter(sentences, label)
loader = Data.DataLoader(dataset, BATCH_SIZE, True)
model = TextCNN()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
for epoch in range(1000):
avg_acc = []
avg_loss = []
model.train()
for batch_x, batch_y in loader:
x = word.sentenceTupleToEmbedding(batch_x)
pred = model(x)
loss = criterion(pred, batch_y)
acc = binary_acc(pred, batch_y)
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_loss.append(loss.item())
avg_acc = np.array(avg_acc).mean()
avg_loss = np.array(avg_loss).mean()
print('train acc:', avg_acc)
print("train loss", avg_loss)