一、前言
参考:https://zhuanlan.zhihu.com/p/73176084
代码:https://link.zhihu.com/?target=https%3A//github.com/649453932/Chinese-Text-Classification-Pytorch
代码:https://link.zhihu.com/?target=https%3A//github.com/649453932/Bert-Chinese-Text-Classification-Pytorch
使用pytorch实现了TextCNN,TextRNN,FastText,TextRCNN,BiLSTM_Attention,DPCNN,Transformer。github:Chinese-Text-Classification-Pytorch,开箱即用。
二、中文数据集:
我从THUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。
以字为单位输入模型,使用了预训练词向量:搜狗新闻 Word+Character 300d。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集、词表及对应的预训练词向量已上传至github,开箱即用。
模型效果:

bert,ERNIE代码:Bert-Chinese-Text-Classification-Pytorch
1.TextCNN
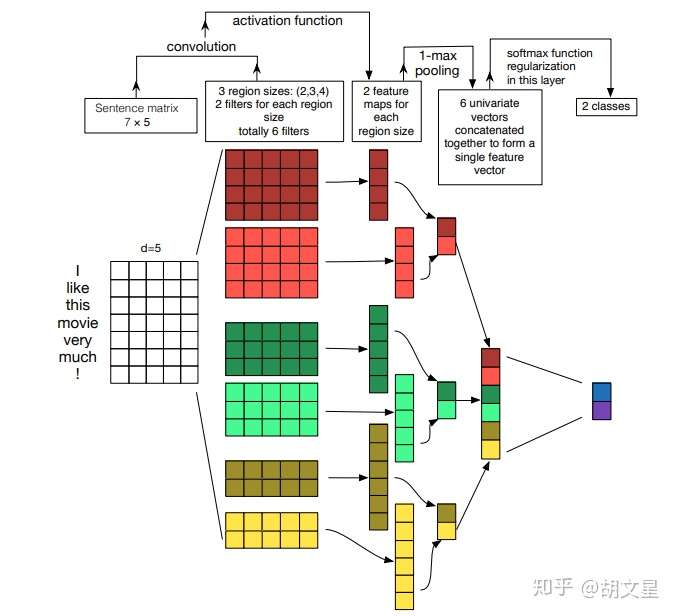 TextCNN整体结构
TextCNN整体结构
数据处理:所有句子padding成一个长度:seq_len
1.模型输入:
[batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size:
[batch_size, seq_len, embed_size]
3.卷积层:NLP中卷积核宽度与embed-size相同,相当于一维卷积。
3个尺寸的卷积核:(2, 3, 4),每个尺寸的卷积核有100个。卷积后得到三个特征图:[batch_size, 100, seq_len-1]
[batch_size, 100, seq_len-2]
[batch_size, 100, seq_len-3]
4.池化层:对三个特征图做最大池化
[batch_size, 100]
[batch_size, 100]
[batch_size, 100]
5.拼接:
[batch_size, 300]
6.全连接:num_class是预测的类别数
[batch_size, num_class]
7.预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测
[batch_size, 1]
分析:
卷积操作相当于提取了句中的2-gram,3-gram,4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留。
2.TextRNN
 图片是单向RNN,看个意思就行
图片是单向RNN,看个意思就行
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接)
[batch_size, seq_len, hidden_size * 2]
4.拿出最后时刻的隐层值:
[batch_size, hidden_size * 2]
5.全连接:num_class是预测的类别数
[batch_size, num_class]
6.预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测
[batch_size, 1]
分析:
LSTM能更好的捕捉长距离语义关系,但是由于其递归结构,不能并行计算,速度慢。
3.TextRNN+Attention
 BiLSTM+Attention
BiLSTM+Attention
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接) [batch_size, seq_len, hidden_size * 2]
4.初始化一个可学习的权重矩阵w
w=[hidden_size * 2, 1]
5.对LSTM的输出进行非线性激活后与w进行矩阵相乘,并经行softmax归一化,得到每时刻的分值:
[batch_size, seq_len, 1]
6.将LSTM的每一时刻的隐层状态乘对应的分值后求和,得到加权平均后的终极隐层值
[batch_size, hidden_size * 2]
7.对终极隐层值进行非线性激活后送入两个连续的全连接层
[batch_size, num_class]
8.预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测
[batch_size, 1]
分析:
其中4~6步是attention机制计算过程,其实就是对lstm每刻的隐层进行加权平均。比如句长为4,首先算出4个时刻的归一化分值:[0.1, 0.3, 0.4, 0.2],然后
4.TextRCNN
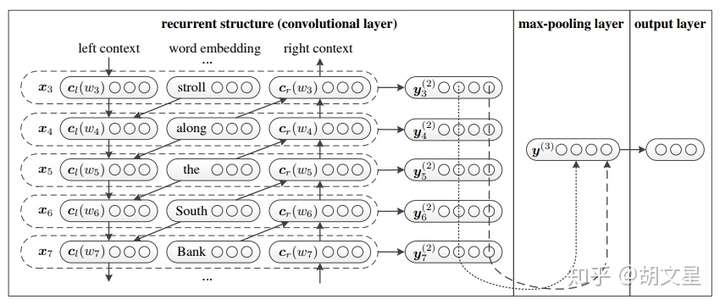 left context是前向RNN的隐层值,right context是后向RNN的隐层值。
left context是前向RNN的隐层值,right context是后向RNN的隐层值。
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接) [batch_size, seq_len, hidden_size * 2]
4.将embedding层与LSTM输出拼接,并进行非线性激活:
[batch_size, seq_len, hidden_size * 2 + embed_size]
5.池化层:seq_len个特征中取最大的
[batch_size, hidden_size * 2 + embed_size]
6.全连接后softmax
[batch_size, num_class] ==> [batch_size, 1]
分析:
双向LSTM每一时刻的隐层值(前向+后向)都可以表示当前词的前向和后向语义信息,将隐藏值与embedding值拼接来表示一个词;然后用最大池化层来筛选出有用的特征信息。emm...就做了一个池化,就能称之为RCNN...
需要注意的是,我的实现和论文中略有不同,论文中其实用的不是我们平时见的RNN,其实从图中能看出来,看公式的区别:
传统RNN:
论文中:
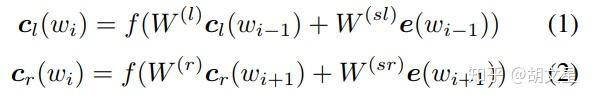
符号看不懂不要紧,我给转换一下:
5.FastText
 简单粗暴的FastText
简单粗暴的FastText
0.用哈希算法将2-gram、3-gram信息分别映射到两张表内。
1.模型输入: [batch_size, seq_len]
2.embedding层:随机初始化, 词向量维度为embed_size,2-gram和3-gram同理:
word: [batch_size, seq_len, embed_size]
2-gram:[batch_size, seq_len, embed_size]
3-gram:[batch_size, seq_len, embed_size]
3.拼接embedding层:
[batch_size, seq_len, embed_size * 3]
4.求所有seq_len个词的均值
[batch_size, embed_size * 3]
5.全连接+非线性激活:隐层大小hidden_size
[batch_size, hidden_size]
6.全连接+softmax归一化:
[batch_size, num_class]==>[batch_size, 1]
分析:
不加N-Gram信息,就是词袋模型,准确率89.59%,加上2-gram和3-gram后准确率92.23%。N-Gram的哈希映射算法见utils_fasttext.py中注释------gram-------处。
N-Gram的词表我设的25W,相对于前面几个模型,这个模型稍慢一点,FastText被我搞成SlowText了。。?但是效果不错呀。。哈哈
有人私信问我这个N-Gram,我大体讲一下。对于N-Gram,我们设定一个词表,词表大小自己定,当然越大效果越好,但是你得结合实际情况,对于2-Gram,5000个字(字表大小)的两两组合有多少种你算算,3-Gram的组合有多少种,组合太多了,词表设大效果是好了,但是机器它受不了啊。
所以N-Gram词表大小的设定是要适中的,那么适中的词表就放不下所有N-Gram了,不同的N-Gram用哈希算法可能会映射到词表同一位置,这确实是个弊端,但是问题不大:5000个字不可能每两个字都两两组合出现,很多两个字是永远不会组成2-Gram的,所以真正出现的N-Gram不会特别多,映射到同一词表位置的N-Gram也就不多了。
N-Gram词表大小我定的25w,比较大了,比小词表训练慢了很多,效果也提升了。这么形容N-Gram词表大小对效果的影响吧:一分价钱1分货,十分价钱1.1分货。
6.DPCNN
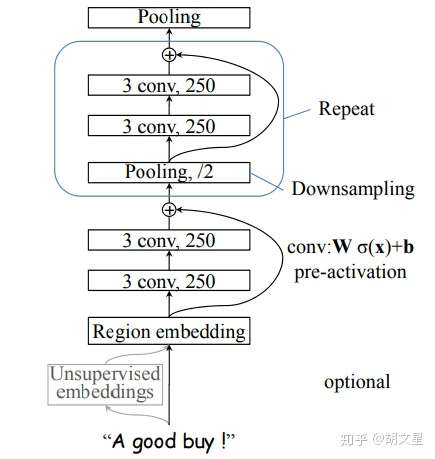
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.进行卷积,250个尺寸为3的卷积核,论文中称这层为region embedding。
[batch_size, 250, seq_len - 3 + 1]
4.接两层卷积(+relu),每层都是250个尺寸为3的卷积核,(等长卷积,先padding再卷积,保证卷积前后的序列长度不变)
[batch_size, 250, seq_len - 3 + 1]
5.接下来进行上图中小框中的操作。
I. 进行 大小为3,步长为2的最大池化,将序列长度压缩为原来的二分之一。(进行采样)
II. 接两层等长卷积(+relu),每层都是250个尺寸为3的卷积核。
III. I的结果加上II的结果。(残差连接)
重复以上操作,直至序列长度等于1。
[batch_size, 250, 1]
6.全连接+softmax归一化:
[batch_size, num_class]==>[batch_size, 1]
分析:
TextCNN的过程类似于提取N-Gram信息,而且只有一层,难以捕捉长距离特征。
反观DPCNN,可以看出来它的region embedding就是一个去掉池化层的TextCNN,再将卷积层叠加。
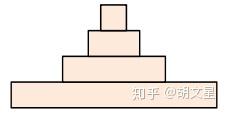
每层序列长度都减半(如上图所示),可以这么理解:相当于在N-Gram上再做N-Gram。越往后的层,每个位置融合的信息越多,最后一层提取的就是整个序列的语义信息。
7.Transformer
代码已上传
# TODO:图文
总结
再贴一遍github地址:Chinese-Text-Classification-Pytorch,觉得有用别忘了回来点赞。如果代码中有问题或者有什么建议,欢迎提出。之后会更新中文的长文本数据集和英文数据集,敬请期待,这个仓库我会一直更新维护,欢迎关注!
Reference:
[1] Convolutional Neural Networks for Sentence Classification
[2] A Sensitivity Analysis of Convolutional Neural Networks for Sentence Classification
[3] Recurrent Neural Network for Text Classification with Multi-Task Learning
[4] Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification
[5] Recurrent Convolutional Neural Networks for Text Classification
[6] Bag of Tricks for Efficient Text Classification
[7] Deep Pyramid Convolutional Neural Networks for Text Categorization
[8] Attention Is All You Need