一、基础模型
1、这种模型,句子长的话,权值参数多、不能记住上下文信息。

2、参数共享,并增加记忆功能。
3、公式化表示RNN

二、RNN维度解析
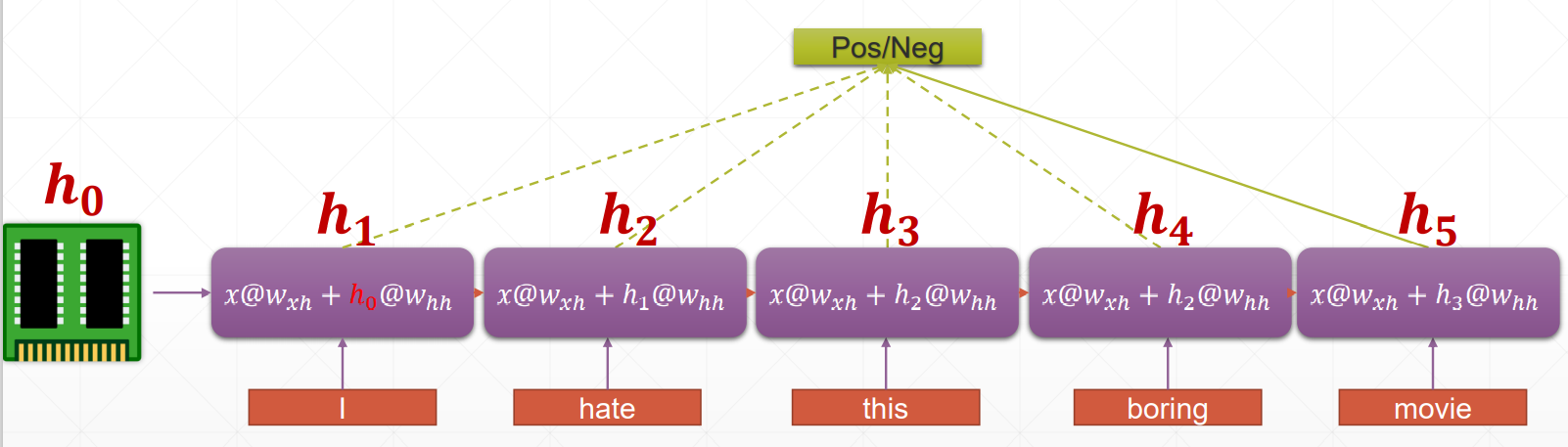
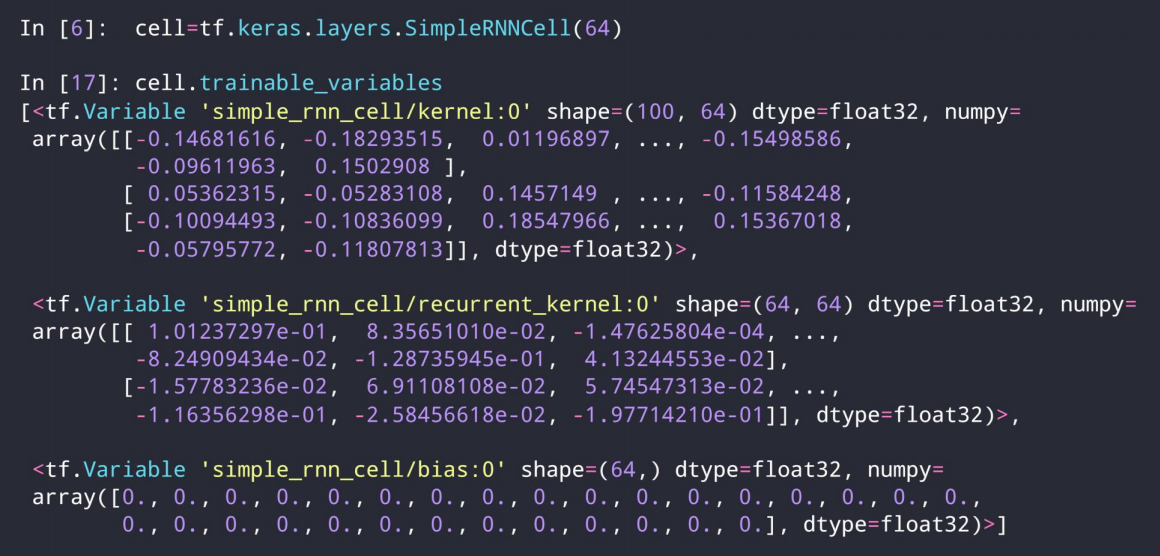
1、如图,假设x的维度[batch, seq_len, embedding_len]是[b, 80, 100],则在t时刻,Xt的形状是[b, 100], 因此,[b, 100] @[100, 64] + [b, 64]@[64, 64]=[b, 64]
就是有个降维过程,100的嵌入维度,降到了我们预设的64维。X @ Wxh + h @ Whh

2、如图。我们预设的隐层3维,输入形状就是[b, embedding_size],其中嵌入维度是4.kernel0是Wxh,第二个是Whh,第三个参数是偏执b
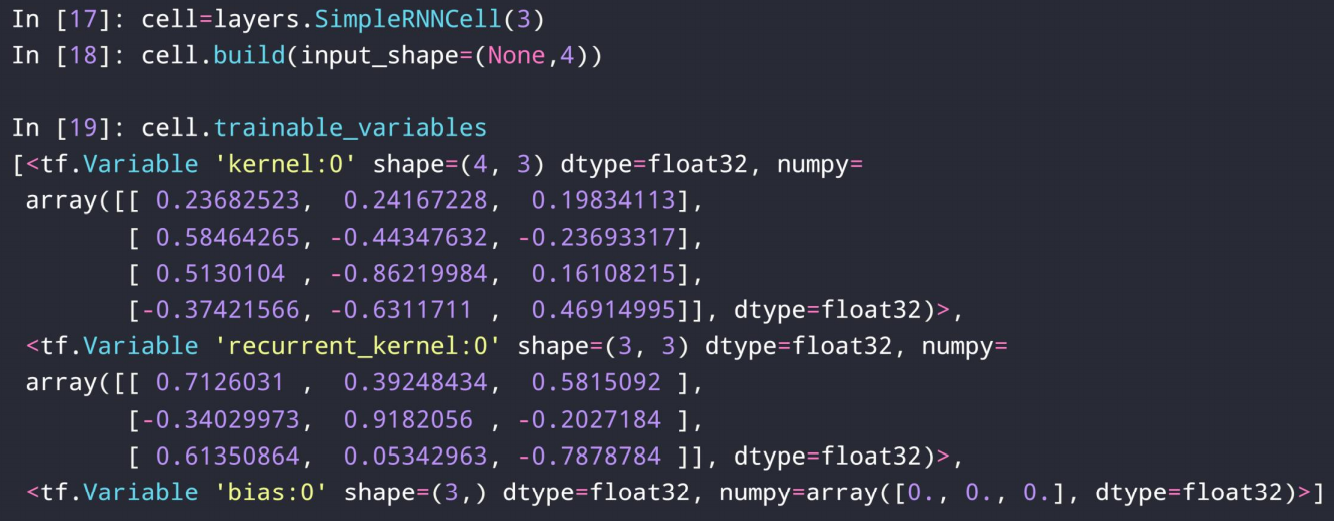
3、out维度和h维度一样。xt1就是h1


三、多层RNN




四、实战
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers tf.random.set_seed(22) np.random.seed(22) assert tf.__version__.startswith('2.') batchsz = 128 # the most frequest words total_words = 10000 max_review_len = 80 embedding_len = 100 (x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words) # x_train:[b, 80] # x_test: [b, 80] x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len) x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len) # 其中,drop_remainder意思是将最后一个不满一个batch的句子组丢弃 db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True) db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) db_test = db_test.batch(batchsz, drop_remainder=True) print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train)) print('x_test shape:', x_test.shape) class MyRNN(keras.Model): def __init__(self, units): super(MyRNN, self).__init__() # [b, 64] self.state0 = [tf.zeros([batchsz, units])] self.state1 = [tf.zeros([batchsz, units])] # transform text to embedding representation # [b, 80] => [b, 80, 100] self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len) # [b, 80, 100] , h_dim: 64 # RNN: cell1 ,cell2, cell3 # SimpleRNN self.rnn_cell0 = layers.SimpleRNNCell(units, dropout=0.5) self.rnn_cell1 = layers.SimpleRNNCell(units, dropout=0.5) # fc, [b, 80, 100] => [b, 64] => [b, 1] self.outlayer = layers.Dense(1) def call(self, inputs, training=None): """ net(x) net(x, training=True) :train mode net(x, training=False): test :param inputs: [b, 80] :param training: :return: """ # [b, 80] x = inputs # embedding: [b, 80] => [b, 80, 100] x = self.embedding(x) # rnn cell compute # [b, 80, 100] => [b, 64] state0 = self.state0 state1 = self.state1 for word in tf.unstack(x, axis=1): # word: [b, 100] # h1 = x*wxh+h0*whh # out0: [b, 64] out0, state0 = self.rnn_cell0(word, state0, training) # out1: [b, 64] out1, state1 = self.rnn_cell1(out0, state1, training) # out: [b, 64] => [b, 1] x = self.outlayer(out1) # p(y is pos|x) prob = tf.sigmoid(x) return prob def main(): units = 64 epochs = 4 model = MyRNN(units) model.compile(optimizer = keras.optimizers.Adam(0.001), loss = tf.losses.BinaryCrossentropy(), metrics=['accuracy'],experimental_run_tf_function=False) model.fit(db_train, epochs=epochs, validation_data=db_test) model.evaluate(db_test) if __name__ == '__main__': main()
五、Layer
import os os.environ['TF_CPP_MIN_LOG_LEVEL']='2' import tensorflow as tf import numpy as np from tensorflow import keras from tensorflow.keras import layers tf.random.set_seed(22) np.random.seed(22) assert tf.__version__.startswith('2.') batchsz = 128 # the most frequest words total_words = 10000 max_review_len = 80 embedding_len = 100 (x_train, y_train), (x_test, y_test) = keras.datasets.imdb.load_data(num_words=total_words) # x_train:[b, 80] # x_test: [b, 80] x_train = keras.preprocessing.sequence.pad_sequences(x_train, maxlen=max_review_len) x_test = keras.preprocessing.sequence.pad_sequences(x_test, maxlen=max_review_len) db_train = tf.data.Dataset.from_tensor_slices((x_train, y_train)) db_train = db_train.shuffle(1000).batch(batchsz, drop_remainder=True) db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test)) db_test = db_test.batch(batchsz, drop_remainder=True) print('x_train shape:', x_train.shape, tf.reduce_max(y_train), tf.reduce_min(y_train)) print('x_test shape:', x_test.shape) class MyRNN(keras.Model): def __init__(self, units): super(MyRNN, self).__init__() # transform text to embedding representation # [b, 80] => [b, 80, 100] self.embedding = layers.Embedding(total_words, embedding_len, input_length=max_review_len) # [b, 80, 100] , h_dim: 64 self.rnn = keras.Sequential([ layers.SimpleRNN(units, dropout=0.5, return_sequences=True, unroll=True), layers.SimpleRNN(units, dropout=0.5, unroll=True) ]) # fc, [b, 80, 100] => [b, 64] => [b, 1] self.outlayer = layers.Dense(1) def call(self, inputs, training=None): """ net(x) net(x, training=True) :train mode net(x, training=False): test :param inputs: [b, 80] :param training: :return: """ # [b, 80] x = inputs # embedding: [b, 80] => [b, 80, 100] x = self.embedding(x) # rnn cell compute # x: [b, 80, 100] => [b, 64] x = self.rnn(x,training=training) # out: [b, 64] => [b, 1] x = self.outlayer(x) # p(y is pos|x) prob = tf.sigmoid(x) return prob def main(): units = 64 epochs = 4 model = MyRNN(units) # model.build(input_shape=(4,80)) # model.summary() model.compile(optimizer = keras.optimizers.Adam(0.001), loss = tf.losses.BinaryCrossentropy(), metrics=['accuracy']) model.fit(db_train, epochs=epochs, validation_data=db_test) model.evaluate(db_test) if __name__ == '__main__': main()