本文已独家授权给脚本之家(jb51net)、新华前后端开发公众号发布
做技术我们最重要的是【做】。但是今天我们来讲片【玩】。这句话可能不太好理解。直接开门见山吧。对于外行朋友一谈到IT他们对我们的定位就是黑客。其实我们和黑客一点关系都没有。今天的技术是【爬虫】 。 为什么说爬虫和黑客有点关联呢。因为爬虫可以将人为行为进行机器化。就是实现编写好代码让机器代替我们人类重复的操作意见事情。
对于爬虫了我们这里不做基础的讲解了。在平时的开发中我们偶尔会用到爬虫。比如说我们系统需要添加天气情况。但是我们有没有气象站给我提供数据。这时候我们最显示的做法就是调用网络上免费的天气接口API 。 这个时候我们Java就会通过爬虫模拟除一个浏览器请求去访问这个天气接口的API。 然后在通过爬虫获取这个API返回的数据。从而进行解析。
对于这些免费的API我们通过爬虫(HttpClient)就可以轻松的访问了。但是想优酷、爱奇艺、掘金这些等级网站他们会有发爬虫策略。最常见的就是利用爬虫进行刷票的行为。他们针对这些刷票做了一些措施。具体措施就不说了(不知道)。更有甚者他们对他们的页面进行加密。让你无法分析他们的html.或者加大你分析的成本。以上就是之前我们用爬虫爬取数据遇到的一些问题。下面简单梳理下我们遇到爬虫的问题
- 网络反爬虫
- 网络人为审核
- 登录验证码
- 需要了解网站(需要有代码经验进行html分析)
selenium
今天我们带了一个好东西。它转变了我们传统爬虫的思路。传统的爬虫我们会去按照开发者的思路去处理逻辑。但是selenium他不需要关注开发者逻辑。只需要我们关注自己的需求。什么意思呢?就是说selenium他就是在模拟用户的行为,你告诉selenium我需要点击页面的某个按钮了,他就去点击了。你告诉他我需要在某个输入框中输入内容了。他就去给你输入内容。有了它,你再也不用管输入内容之后提交登录真正请求了。这样的好处是降低了爬虫的学习成本。对于不懂技术的人也可以很快上手了。
环境准备
这个是干嘛的呢?这里先透露下selenium使用的是浏览器的内核操作页面的。所以这里需要现在内核。下载内核前提是电脑上有浏览器。笔者这里电脑上浏览器是Google 1.73版本 。 所以下载内核就得是对应的版本,否则会报错的。在notes.txt文件中会列出每个对应的浏览器的版本的。
代码环境
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
开始爬虫
想想我们平时浏览网页的时候是需要先打开浏览器,这里也是一样。
【我们需要打开浏览器】(我的内核放在/root/Downloads/chromedriver)
ChromeOptions chromeOptions = new ChromeOptions();
File chromeDriverPath = new File("/root/Downloads/chromedriver");
System.setProperty("webdriver.chrome.driver", chromeDriverPath.getAbsolutePath());
chromeOptions.addArguments("--headless");
chromeOptions.addArguments("--disable-gpu");
//ubuntu浏览器中需要添加
chromeOptions.addArguments("--no-sandbox");
webDriver = new ChromeDriver(chromeOptions);
headless : 表示隐式打开浏览器,因为做爬虫就不需要显示界面了。
no-sandbox : 这个是因为我的Ubuntu安装的google需要这个参数,所以这里也需要加上
disable-gpu : 同上
【输入链接地址】(https://juejin.im/)
webDriver.get("https://juejin.im/");,这样内核就获取到了我们在浏览器中看到的效果。那么我们这么获取我们需要的页面数据呢。
findElement通过这个方法我们可以获取到我们想要的任何数据。换句话说通过这个方法这个页面在你面前一览无余。包括他的衍生页面
有的读者有疑问了。我该怎么让他获取我想要的东西呢。
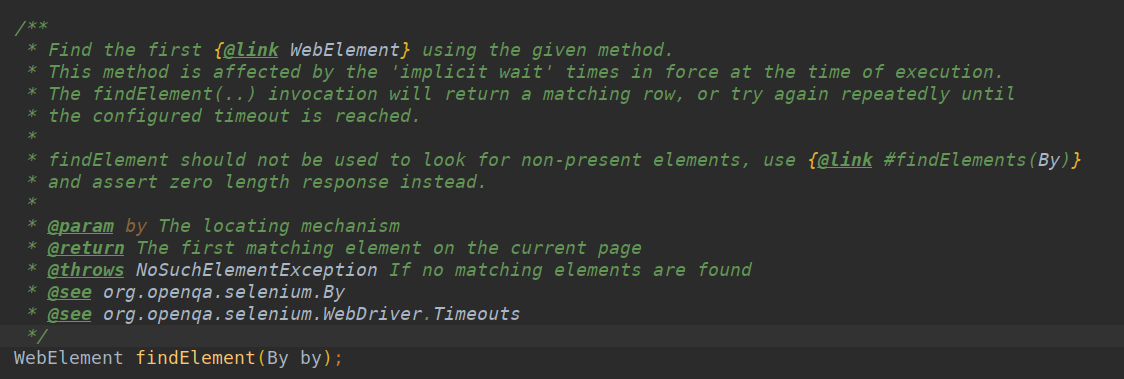
我们可以看出来这个方法里只有一个参数,By对象。这个By对象里提供了如下方法
- id
- linkText
- partialLinkText
- name
- tagName
- xpath
- className
- cssSelector
上面这些方法就是我们定位元素的方法。什么意思呢,我们前段朋友们经常通过jquery操作html的dom对象,在By对象里cssSelector就是和jquery同样的操作方法。好多都是和jquery类似的。这里不懂技术的人会说这里技术点很难。其实不难。 我们不懂代码的怎么办呢。我们在浏览器浏览页面 。 比如下图中我想获取我的博客名称(框架原理那点事--不就反射嘛。)

我们鼠标放在【框架原理那点事--不就反射嘛】上右键选择【检查】。会自动跳转到对应的代码的


后面三种对应By里面的制定方法。这里就不说了。
操作js
WebElement webElement = webDriver.findElement(By.cssSelector("xxxxxx"));
JavascriptExecutor js = (JavascriptExecutor) webDriver;
js.executeScript("arguments[0].click();",digg);
上面的webElement是页面中一个按钮。我们可以直接webElement.click()让按钮点击或者webElement.submit()提交Form表单。但是有的时候会不起作用。这个时候用上面的代码可以进行点击。
截图
File source = ((TakesScreenshot) webDriver).getScreenshotAs(OutputType.FILE);
try {
Files.copy(source.toPath(), new FileOutputStream(new File("/root/Downloads/test/1.png")));
} catch (IOException e) {
e.printStackTrace();
}
try {
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
我们内核操作因为正常不开浏览器界面,但是我们调试的时候又想知道结果,可以打印除当前窗口的图片。就是上述的代码
切换窗口
Set<String> windowHandles = webDriver.getWindowHandles();
for (String windowHandle : windowHandles) {
if (!windowHandle.equals(webDriver.getWindowHandle())) {
//webDriver.switchTo().window(windowHandle);
}
}
在当前窗口切换访问地址
webDriver.navigate().to("https://juejin.im/post/5d76f6585188254cc27b2af4");
webDriver.get("https://juejin.im/post/5d76f6585188254cc27b2af4");
管理cookie
webDriver.get("https://juejin.im/timeline");
webDriver.manage().addCookie(cookie);
webDriver.get("https://juejin.im/post/5d76f6585188254cc27b2af4");
这里值得注意的是,在添加cookie之前我们需要先访问主页,告诉内核我们后面添加的cookie是给那个Host下添加的。这样我们添加的cookie才会有效。如上我们在juejin.im这个Host下都添加了Cookie。
个人网站(https://zxhtom.oschina.io)
个人微信(zxh870775401)
微信公众号 : 新华前后端开发
# 加入战队
微信公众号
# 加入战队
微信公众号
