一、初始Series
Series 是一个带有 名称 和索引的一维数组,既然是数组,肯定要说到的就是数组中的元素类型,在 Series 中包含的数据类型可以是整数、浮点、字符串、Python对象等。
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
-
创建第一个Series
import pandas as pd user_age = pd.Series(data=[18, 30, 25, 40]) user_age.index = ["Tom", "Bob", "Mary", "James"] #加索引 user_age.index.name = "name" #索引加名字 user_age.name="user_age_info" #series加名字 user_age Out[4]: name Tom 18 Bob 30 Mary 25 James 40 Name: user_age_info, dtype: int64
- 创建Series的方式
- 列表方式创建
pd.Series([],index=[])
- 字典方式创建
pd.Series({}


# 方式一 t = pd.Series([1,2,3,4,43],index=list('asdfg')) print(t) a 1 s 2 d 3 f 4 g 43 dtype: int64 #方式二 temp_dict = {'name':'xiaohong','age':30,'tel':10086} t2 = pd.Series(temp_dict) t2 Out[10]: name xiaohong age 30 tel 10086 dtype: object import string #字典推导式 a = {string.ascii_uppercase[i]:i for i in range(10)} print(a) print(pd.Series(a)) print(pd.Series(a,index=list(string.ascii_uppercase[5:15]))) {'A': 0, 'B': 1, 'C': 2, 'D': 3, 'E': 4, 'F': 5, 'G': 6, 'H': 7, 'I': 8, 'J': 9} A 0 B 1 C 2 D 3 E 4 F 5 G 6 H 7 I 8 J 9 dtype: int64 F 5.0 G 6.0 H 7.0 I 8.0 J 9.0 K NaN L NaN M NaN N NaN O NaN dtype: float64
- 手动指定数据类型
#手动指定类型 name = ["Tom", "Bob", "Mary", "James"] user_age = pd.Series(data=[18, 30, 25, 40], index=name, name="user_age_info", dtype=float) user_age Out[7]: Tom 18.0 Bob 30.0 Mary 25.0 James 40.0 Name: user_age_info, dtype: float64
二、Series的索引
- series索引有五种方式:索引、序号、逻辑值查找、切片,数组
name = pd.Index(["Tom", "Bob", "Mary", "James"], name="name")
user_age = pd.Series(data=[18, 30, 25, 40], index=name, name="user_age_info")
"""按索引、序号,逻辑值查找,切片"""
user_age['Tom'] # 索引
Out[14]: 18
user_age.get('Tom') # get方式
Out[15]: 18
user_age[0] # 序号
Out[16]: 18
user_age[:3] # 切片
Out[17]:
name
Tom 18
Bob 30
Mary 25
Name: user_age_info, dtype: int64
user_age[user_age>25] # 逻辑值查找
Out[18]:
name
Bob 30
James 40
Name: user_age_info, dtype: int64
user_age[[3,1]] # 取多个值
Out[19]:
name
James 40
Bob 30
Name: user_age_info, dtype: int64
user_age[::2] # 切片
Out[20]:
name
Tom 18
Mary 25
Name: user_age_info, dtype: int64
三、基本属性

user_age.shape Out[21]: (4,) user_age.index Out[22]: Index(['Tom', 'Bob', 'Mary', 'James'], dtype='object', name='name') user_age.values Out[23]: array([18, 30, 25, 40], dtype=int64) user_age.unique() Out[24]: array([18, 30, 25, 40], dtype=int64) user_age.nunique() Out[25]: 4 user_age.dropna() Out[26]: name Tom 18 Bob 30 Mary 25 James 40 Name: user_age_info, dtype: int64 user_age.isin(list(range(30))) Out[28]: name Tom True Bob False Mary True James False Name: user_age_info, dtype: bool user_age.sort_index() Out[29]: name Bob 30 James 40 Mary 25 Tom 18 Name: user_age_info, dtype: int64 user_age.sort_values() Out[30]: name Tom 18 Mary 25 Bob 30 James 40 Name: user_age_info, dtype: int64 user_age.sort_values(ascending=False) Out[31]: name James 40 Bob 30 Mary 25 Tom 18 Name: user_age_info, dtype: int64
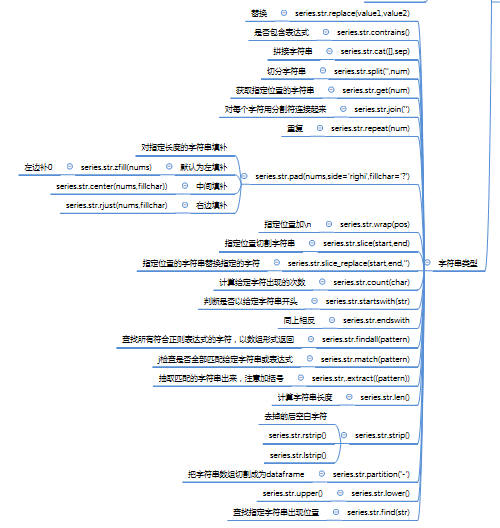
- 数字类型

- 字符串类型
四、画图
Series.plot(kind='line', ax=None, figsize=None, use_index=True, title=None, grid=None, legend=False, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, fontsize=None, colormap=None, table=False, yerr=None, xerr=None, label=None, secondary_y=False, **kwds)[source]

官方文档:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.plot.html
- series转为dataframe
series.to_frame()