本篇博客
1 认识web自动化测试
1.1 什么是自动化测试
1.2 为什么进行自动化测试
1.3 自动化测试的分类
1.4 web自动化条件和使用范围
1.5 web自动化常用的工具
2 元素定位(重点)
2.1 工具的安装与使用
2.2 为什么学习元素定位
2.3 css选择器
2.4 xpath选择器
2.4.1 节点之间的关系
2.4.2 xpath路径表达式

1 认识web自动化测试
1.1 什么是自动化测试
软件自动化测试:
就是通过测试工具或者其他手段,按照测试人员的预定计划对软件产品进行自动化测试,他是软件测试的一个重要组成部分,能够完成许多手工测试无法完成或者难以实现的测试工作,正确合理的实施自动化测试,能够快速,全面的对软件进行测试,从而提高软件质量,节省经费,缩短软件的发布周期
1.2 为什么进行自动化测试
1)缩短测试周期
计算机行业更新迭代快速,大量频繁的回归测试消耗时间,自动化测试能够将重复的实行交给计算机去做,加快测试速度。
2)避免人为出错
测试人员不可能持续高度集中,并且人类易受外界影响(头疼脑热,精神不振),可能会造成人为错误
3)测试信息存储
自动化测试将测试信息和数据储存在文件中,思路清晰明确,交接方便
4)轻易获取覆盖率
自动化测试能够解放测试人员,使测试人员能够有更多的精力做那些非重复性的工作。
5)其他
自动化测试可以是实现自动或者定时执行
总结:1 是否是长期项目 2 自动化测试实现难度是否轻松 3 要完成一遍手测后。
1.3 自动化测试的分类
1.整体分类:
1)自动化功能测试
2)自动化性能测试
2.自动化功能测试的分类:
1)单元测试(程序员搞定)
2)功能测试(主要由测试人员进行功能测试,目前大部分应用以web为主)
3)接口测试(主要由测试人员进行接口测试,利用相关工具进行)
大中型项目或长期项目可以采用自动化测试
自动化功能测试的主要工作:主要是编写代码、脚本,让软件自动运行,发现缺陷,代替部分的手工测试。但一般只有大的项目才需要进行自动化,中小型项目不推荐使用自动化测试。
性能测试主要是使用测试工具,Loadrunner、Jmeter等,对软件进行压力测试、负载测试、强度测试等等
为什么要用自动化实现性能测试?
因为人不可能实现高并发,比如上万请求。
1.4 web自动化条件和使用范围
1.使用自动化的前提条件
1)手动测试已经完成,后期再不影响进度的前提下逐渐实现自动化
2)项目周期长,重复性的工作都交给机器去实现
3)需求稳定,项目变动不大
4)自动化测试脚本复杂度比较低
5)可重复利用
2.使用自动化测试的场景
1)频繁的回归测试(回归测试是回归bug)
2)冒烟测试(项目上线,走一遍。)
3)互联网迭代频繁
4)传统行业需求变化不大,应用频繁
5)性能测试
1.5 web自动化常用的工具
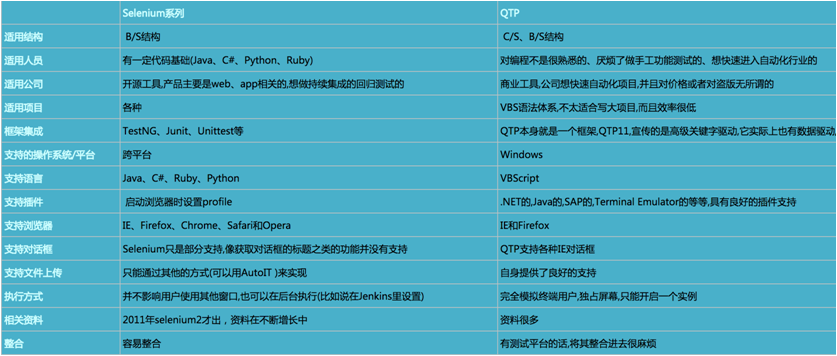
1)QTP(收费)
QTP是Mercury公司的Quick Test Professional的简称,是一种自动测试工具。
2)Selenium(开源):B/S结构,浏览器和服务器
ThroughtWorks一个强大的基于浏览器的开源自动化测试工具,通常用来编写web应用的自动化测试
3)RFT(收费)
IBM Rational Test Professional的简称,是一款先进的自动化的功能和回归测试工具,使用与测试人员和GUI开发人员,基础是针对Java,.NET的对象计数和基于web应用程序的录制,回放功能。
4)Watir(开源)
使用Ruby实现的开源web自动化测试框架,小巧灵活
5)Sahi(开源)
印度一家公司开发的web自动化测试工具,简单易用,支持Ajax和web2.0
QTP Vs Selenium
2 元素定位(重点)
2.1 工具的安装与使用
要想让计算机定位到元素,就要使用计算机能够读懂的css选择器或者xpath路径表达式,那么我们就需要用到接下来的几个插件
(以下的这些插件都是Firefox浏览器插件,我们需要安装Firefox浏览器,Firefox浏览器的安装可以百度)
材料:
1)firefox35
2)firebug插件
3)firepath插件
下面是按照正常的步骤在火狐流浪器上安装插件。但是官方已经将firebug在火狐流浪器上下架。所以按下面是搜不到的。可以在网上搜索博客,找到将这两个插件包下载下来,拖进去使用就行了。有在百度网盘上存下来这两个插件的包,下载下来就行。
1.安装firebug插件
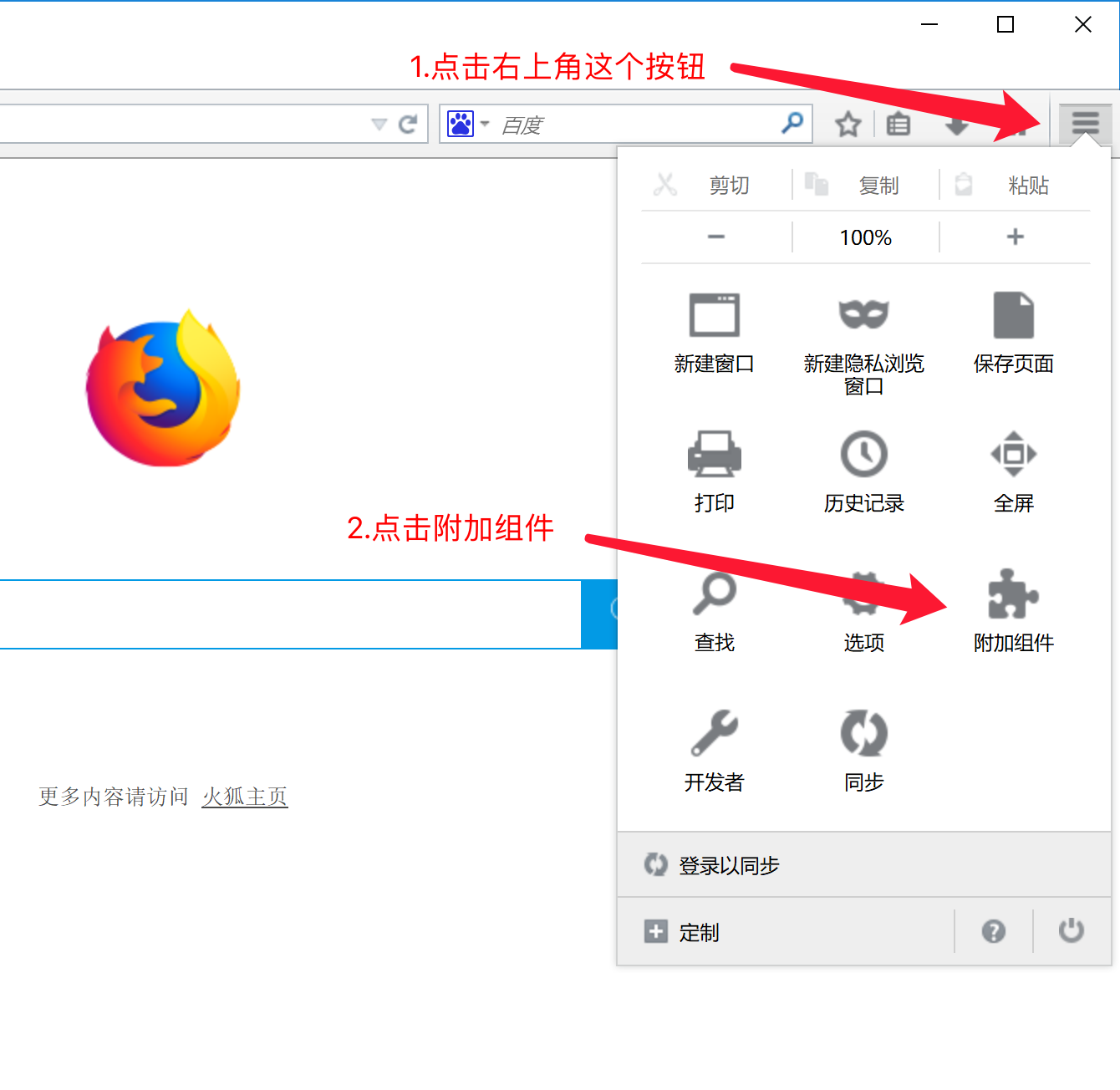
1.打开firefox浏览器,点击右上角菜单1.打开firefox浏览器,点击右上角菜单
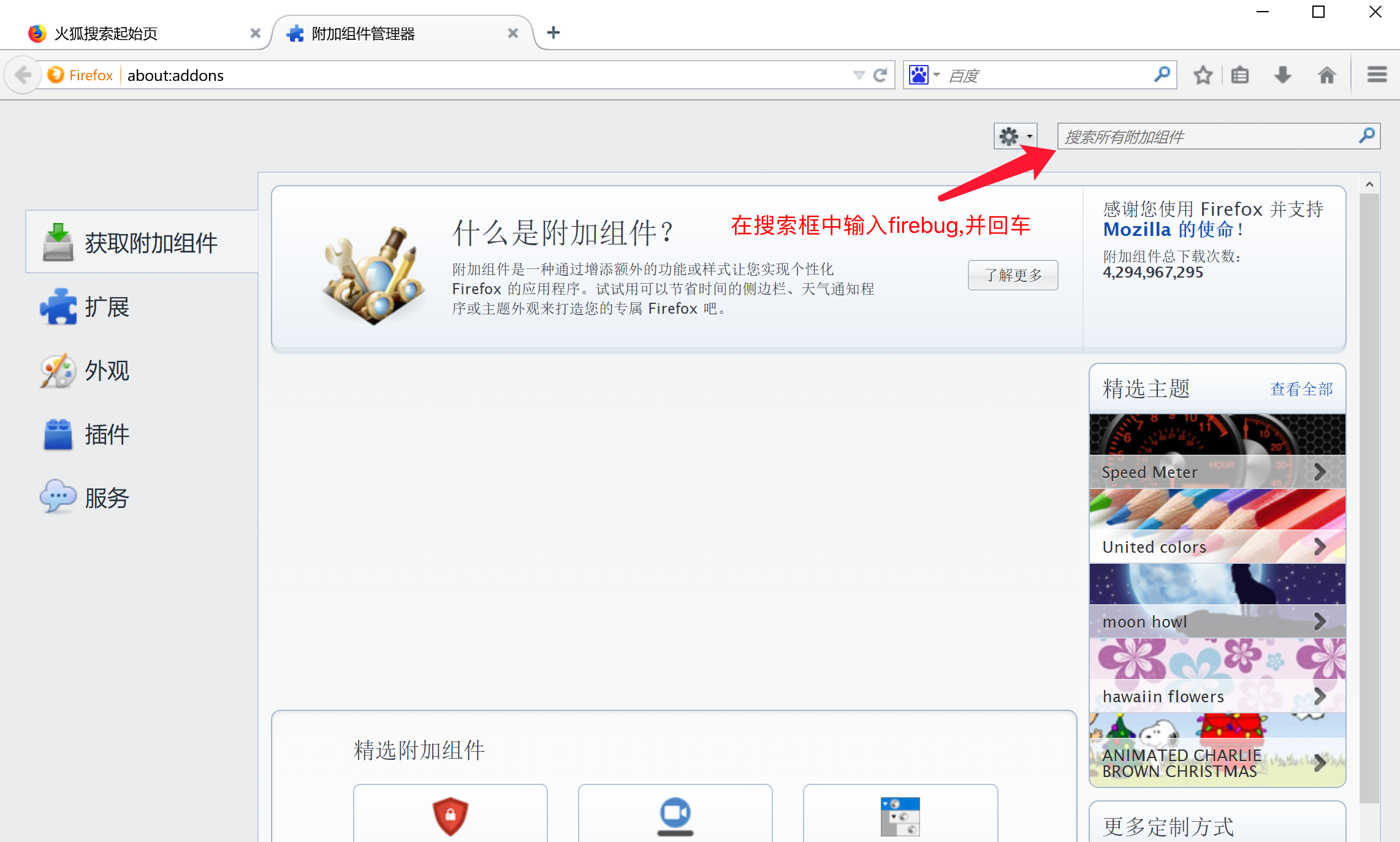
2.在右上角的搜索栏中输入firebug,并回车
3.在搜索结构中找到firebug,并点击搜索结果之后的安装
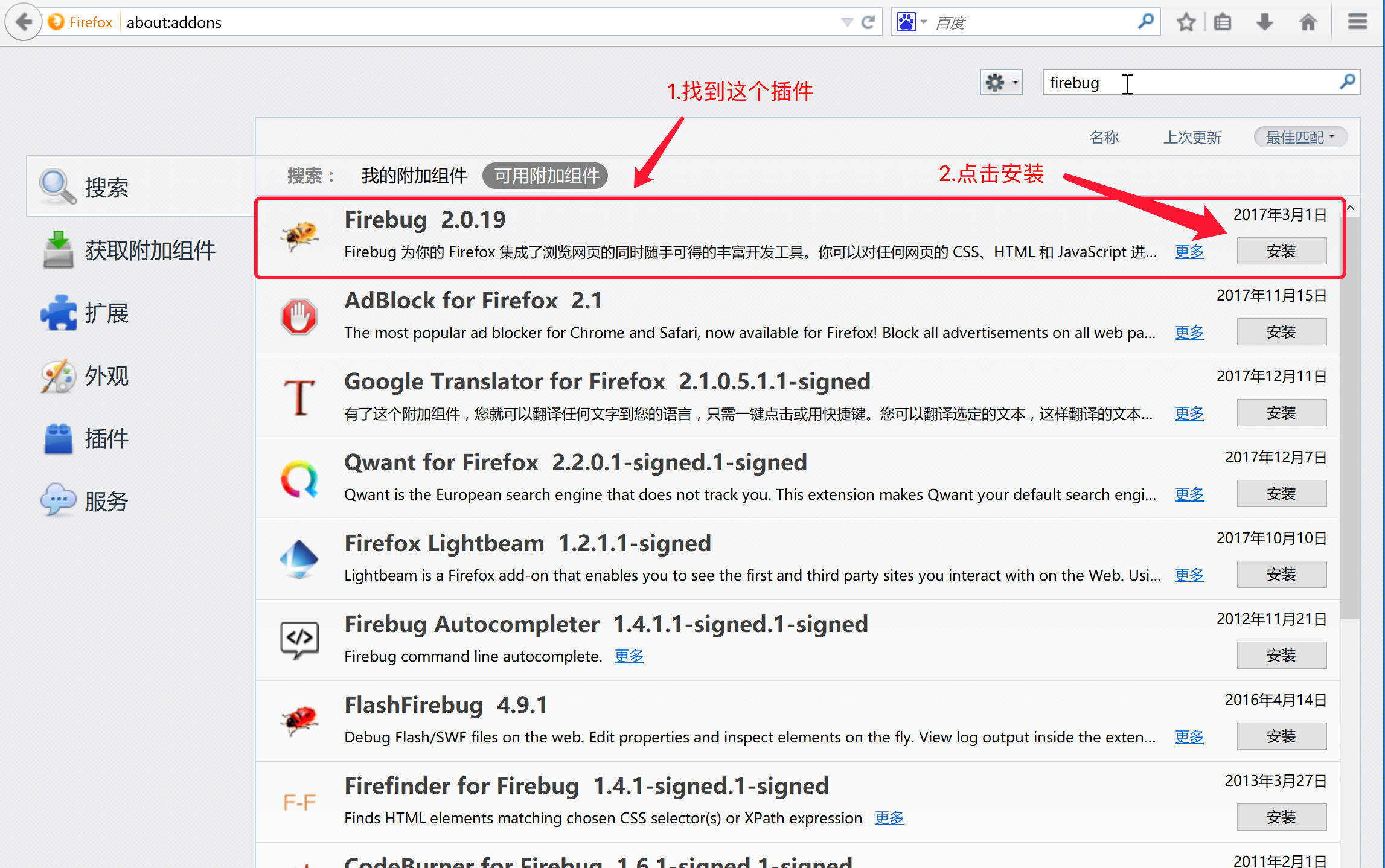
4.安装完成后,点击扩展查看右侧列表中是否存在firebug
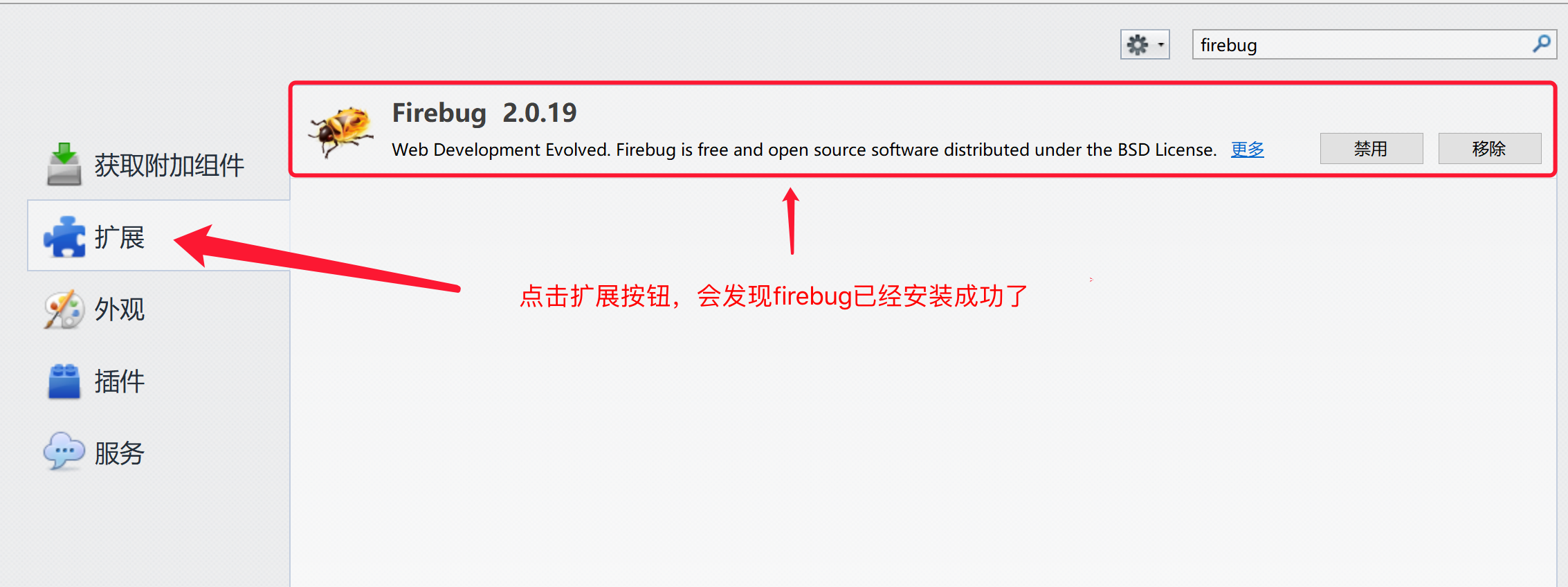
5.打开firebug插件

6.检查未安装firepath插件

2.安装firepath插件
1.搜索firepath插件按照上述步骤进行操作,进行安装
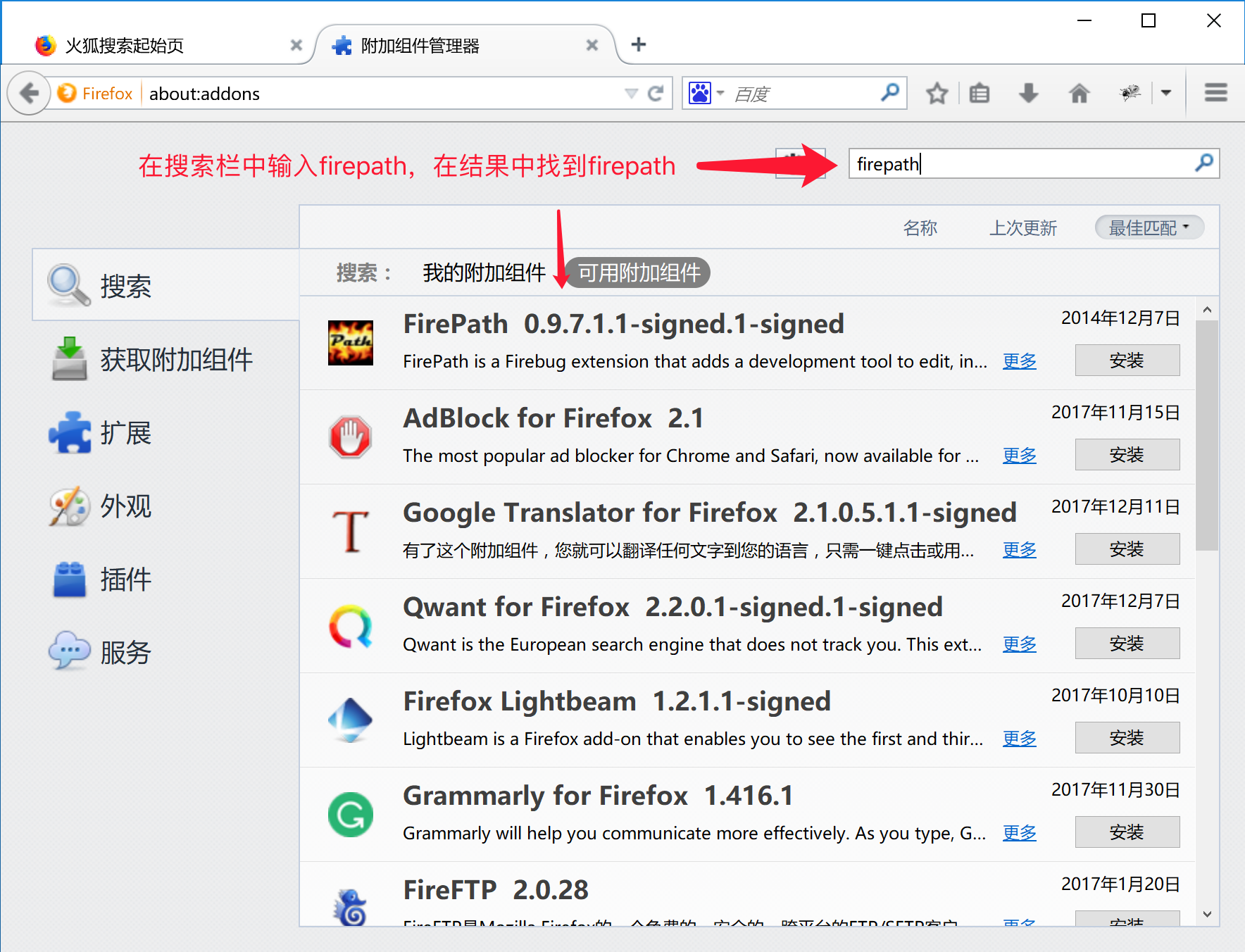
2.安装完成之后提示重新启动浏览器,点击重启

3.重启浏览器之后打开firebug,在如图所示位置出现firepath,则表示插件安装完成

2.2 为什么学习元素定位
1)计算机没有智能到人的程度。
2)计算机不能像手动测试人员一样通过眼看,手操作鼠标点击,操作键盘输入。
3)计算机通过一系列计数手段找到元素(按钮、输入框、模拟键盘等)
元素定位的工具或手段有哪些?
1)css选择器
2)xpath
css比xpath更简单,主要记住一个。但另一个也要看的懂。
2.3 css选择器
1.什么是css选择器?
CSS 中,选择器是一种模式,用于选择需要添加样式的元素。计算机能够通过css选择器定位到相应元素,我们在编写自动化测试脚本的时候很多时候是在不断地找到css选择器。
2.css选择器语法
1)通过伪类名、id、标签名定位

上面面的例子是在这个页面找的元素,右键-firebug检查元素(如果第一用,可以把右上角的小虫子点开下。),出现下面的画面。

注意:第2步要选择css模式,默认是xpath,找css是自然找不到的。
.tools :通过class的值进行定位
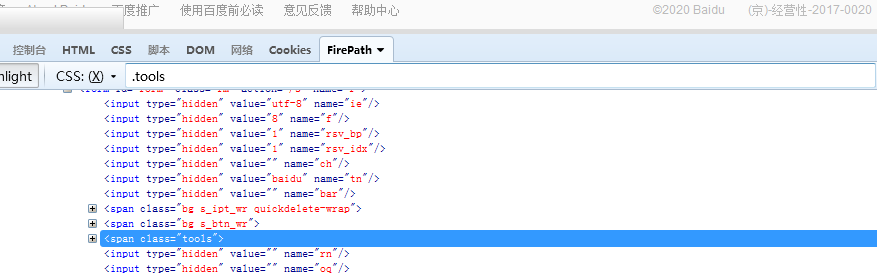
#kw 通过id的值进行定位
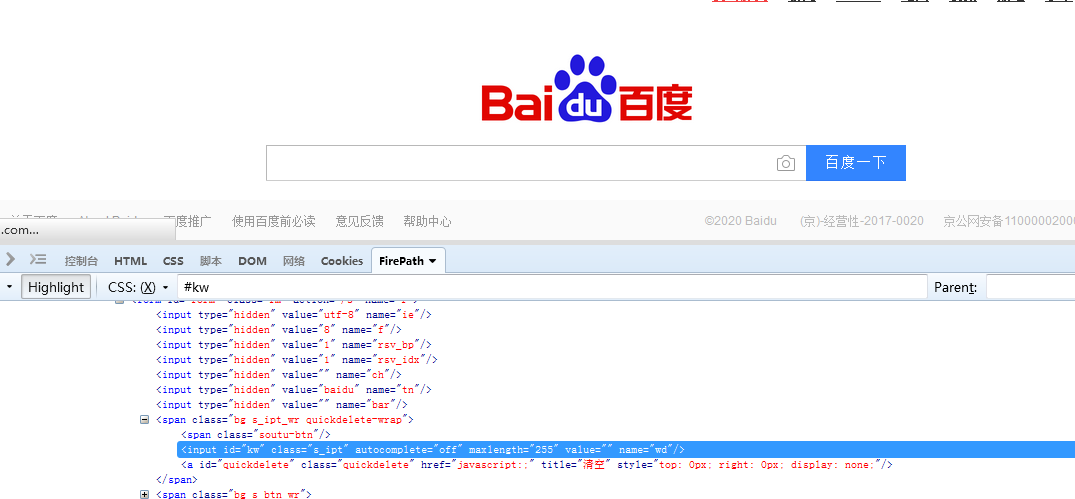
div 通过标签进行定位
2)通过元素之前嵌套关系

上面的例子在这个页面上找的
div,a :选择所有div标签和a标签
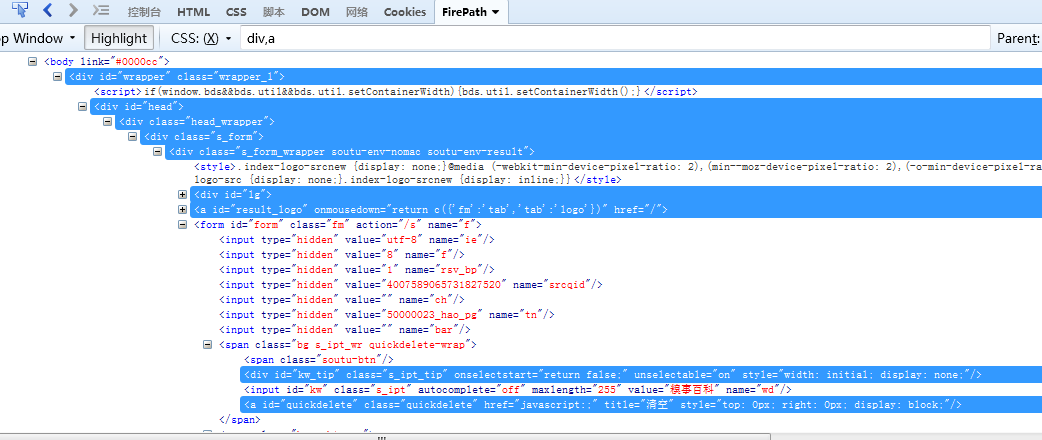
div a :选择div所有后代a标签(找的是a标签,是div的后代关系)
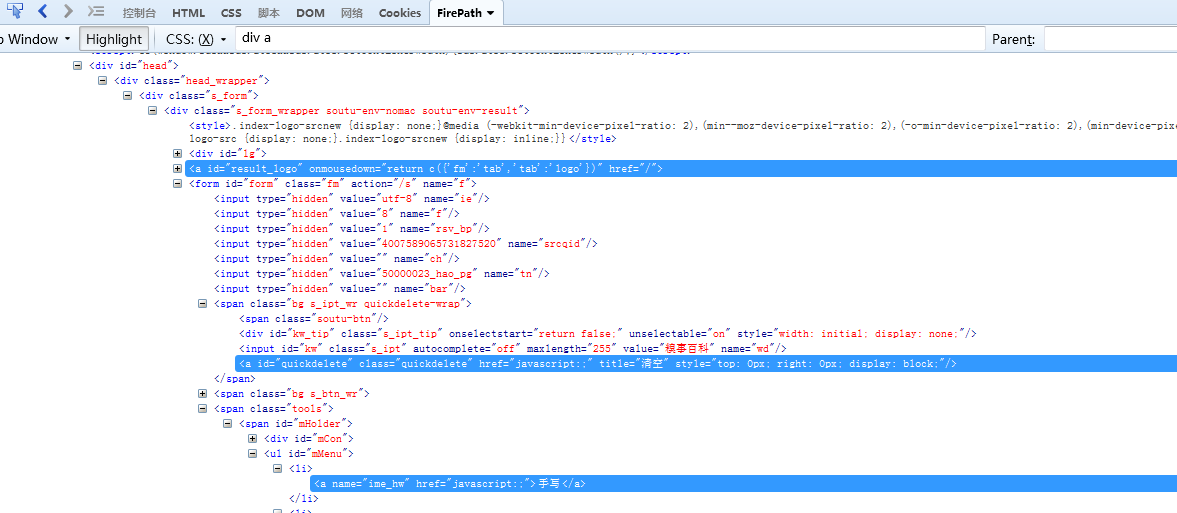
div>a :找的是div子代a标签(找的是a标签,和div是父子关系)

div+div :前面紧挨的是div标签,找的是后面的div标签(前面div和后面的div是同胞关系)

3)通过属性1
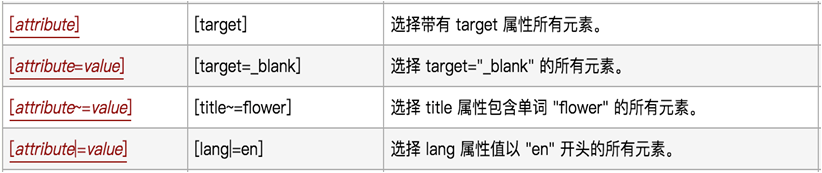
使用www.baidu.com网站实现下面的例子。
[id] 匹配所有含有id属性的标签

[id='lg'] 匹配所有含有id并且值为lg的标签
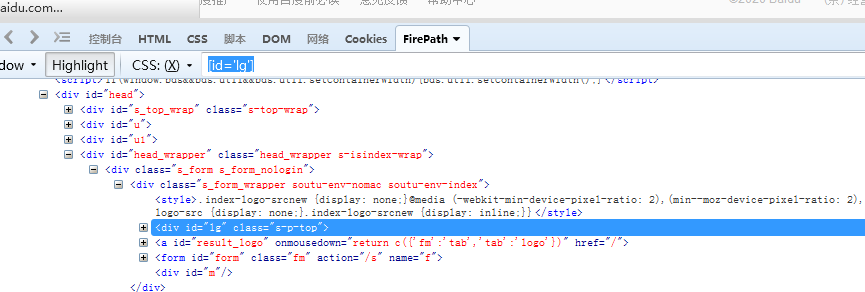
注意:[id='lg']属性值 lg要用单引号或者双引号括起来。不能不括。
[type="submit"]

[class~="main"] 定位标签属性class值中有独立main的节点,mian是一个单独的单词,和后面clearfix没有特殊符号。
<div id="s_main" class="main clearfix"/>
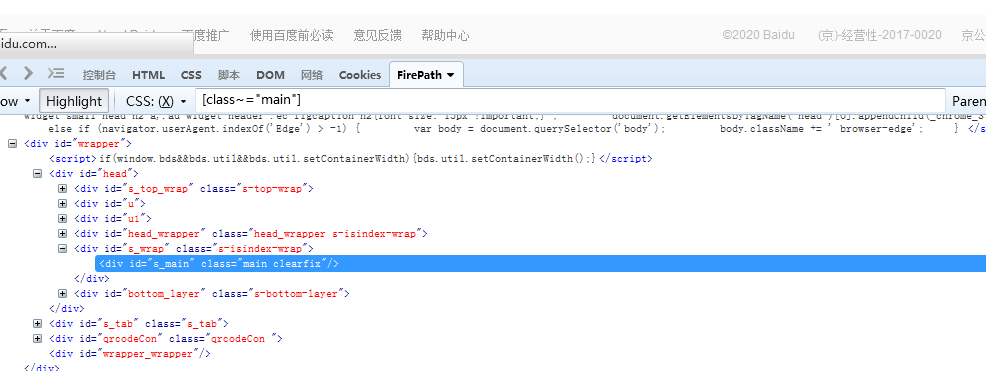
[id|=s] 定位标签属性id的值以s开头的节点(s-bottom-layer-right 该节点需为一个完整的单词,以s开头,和后面有特俗符号,是一个完整的单词。)

注意:红色箭头指的下面是1,指的是匹配了1个。
3)通过属性2

[src^="https://"] 匹配scr属性以https://开头的节点
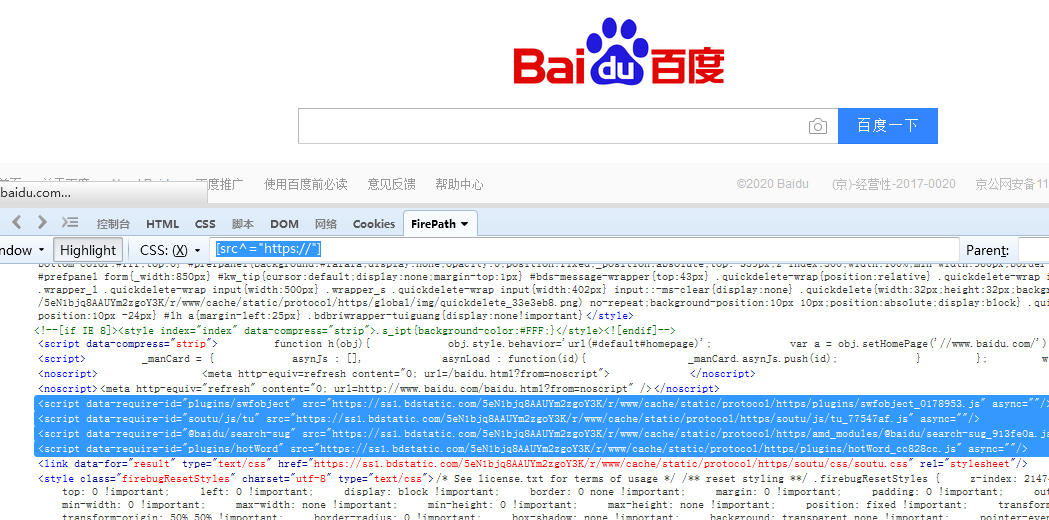
[src$="js"] 匹配src属性以js结尾的节点
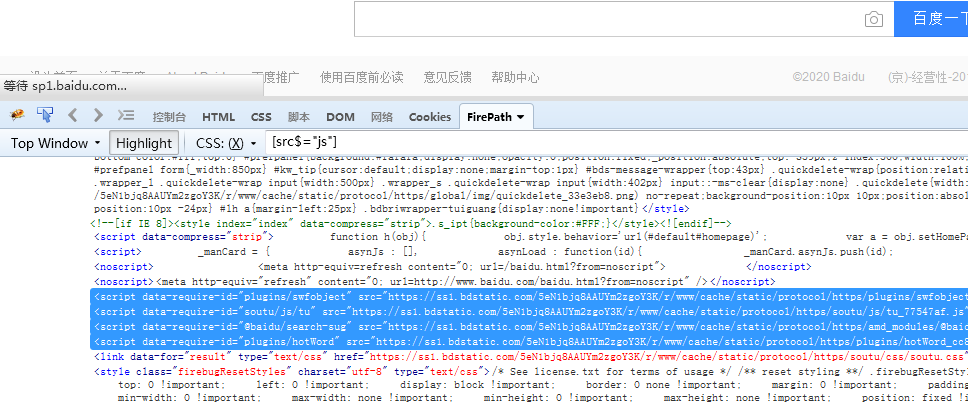
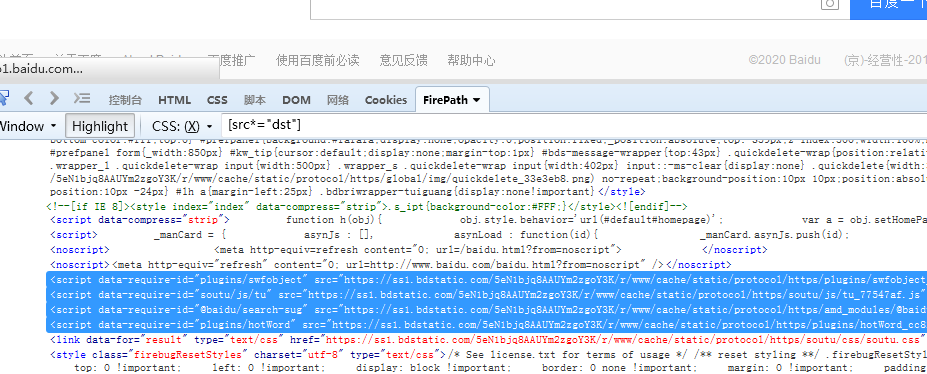
[src*="dst"] 匹配src属性中含有dst的节点,dst是单词bdstatic的一部分也能找到。
4)通过父子关系

img:only-child 匹配所有独生子女的img节点
理解:img是父标签的唯一个子标签,只有唯一,一个img标签。

下面这个用的比较多!
body>div:nth-child(1) 匹配body的第1个div子节点
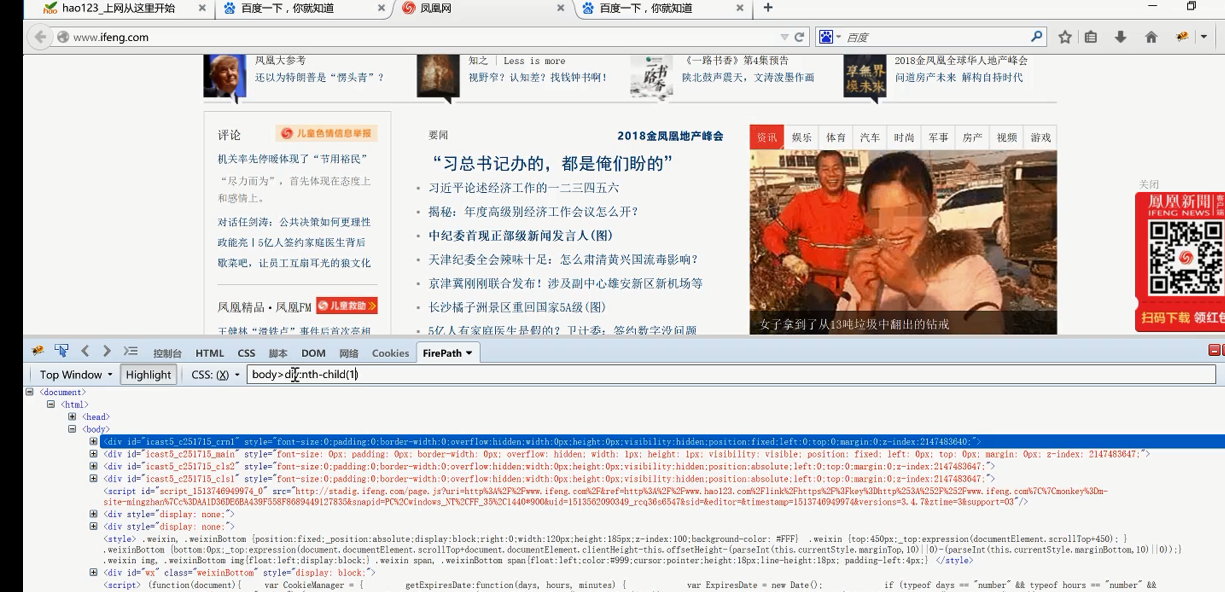
body>div:nth-child(2) 匹配body的第2个div子节点

body>*:nth-last-child(1) 匹配body的最后一个子节点

5)元素状态
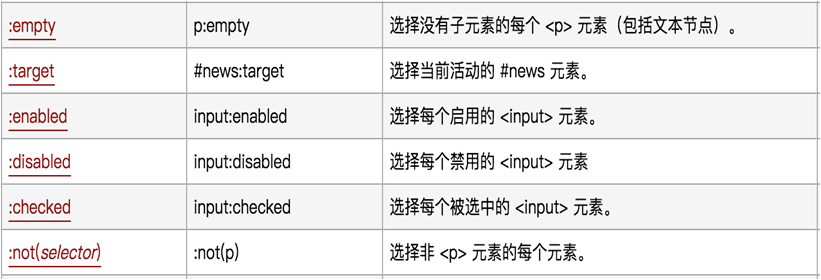
其他的用的不是很多。
:not(link) 查找不是link标签的节点

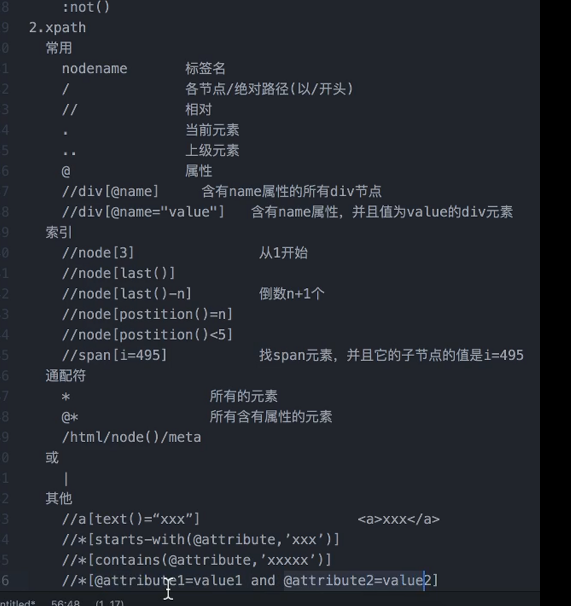
2.4 xpath选择器
1.XPath即为XML路径语言,它是一种用来(标准通用标记语言的子集)在 HTMLXML 文档中查找信息的语言
2.什么是XML?
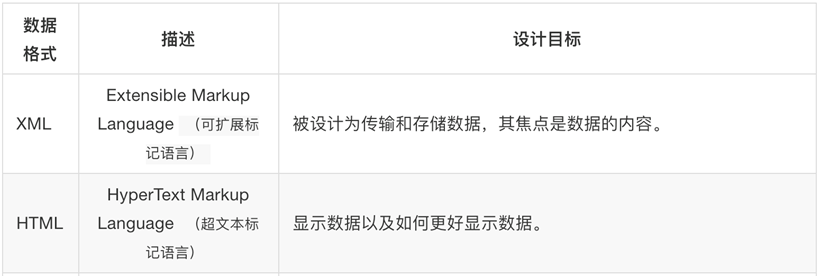
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
3.XML与HTML
2.4.1 节点之间的关系
节点的概念:每个XML/HTML的标签我们都称之为节点

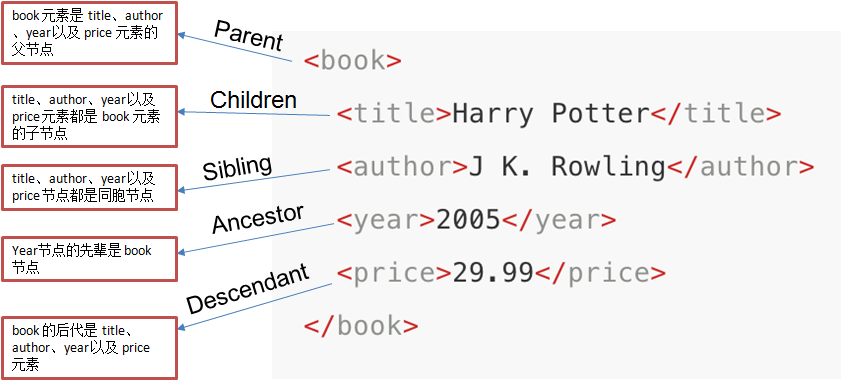
2.4.2 xpath路径表达式
XPath 使用路径表达式来选取 XML 文档中的节点或者节点集。这些路径表达式和我们在常规的电脑文件系统中看到的表达式非常相似。

1.通过节点名定位(http://www.ifeng.com/)
html 定位到html节点
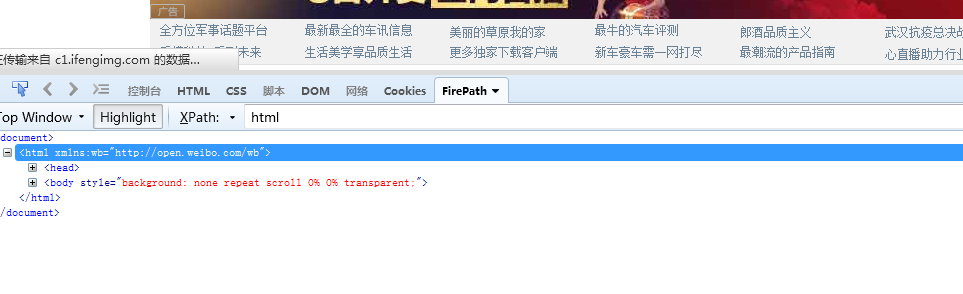
html/head 定位到head节点
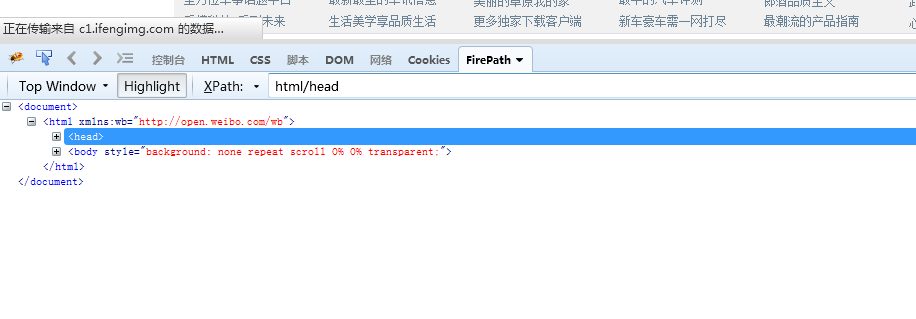
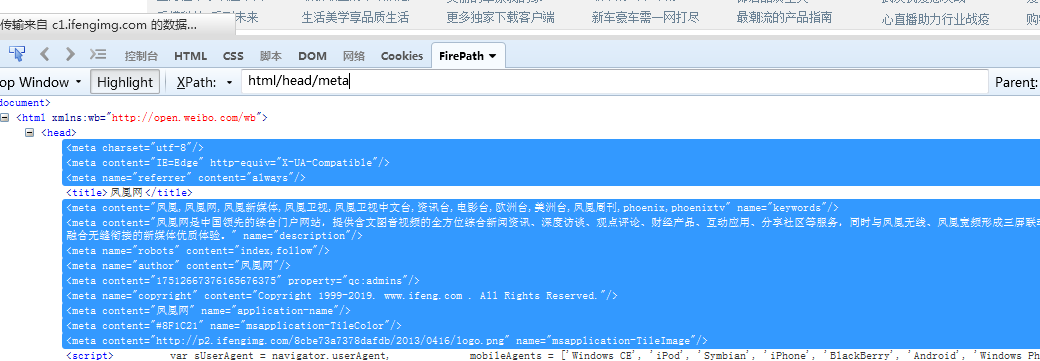
html/head/meta 定位好head中的所有meta节点
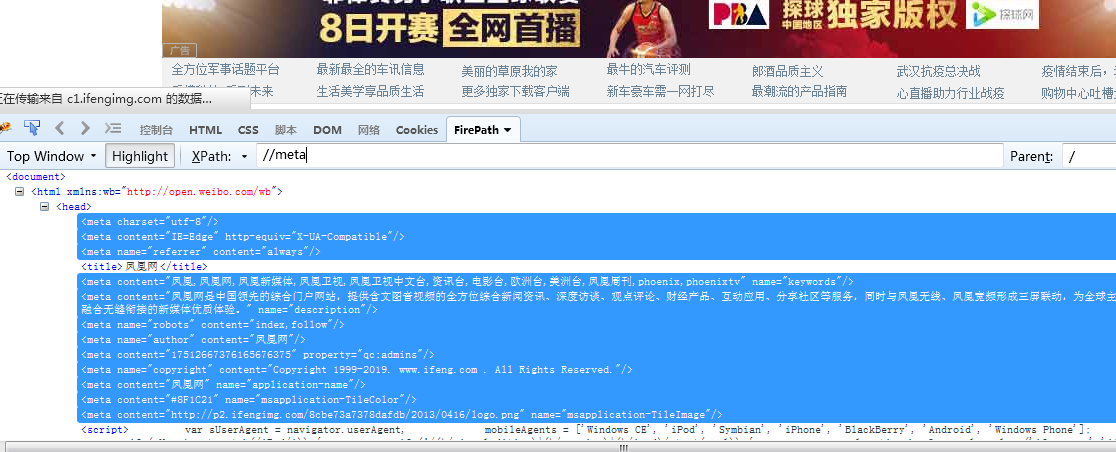
2.相对路径定位节点(http://www.ifeng.com/)
//title 使用相对路径定位到title节点

//meta 使用相对路径定位到所有meta节点
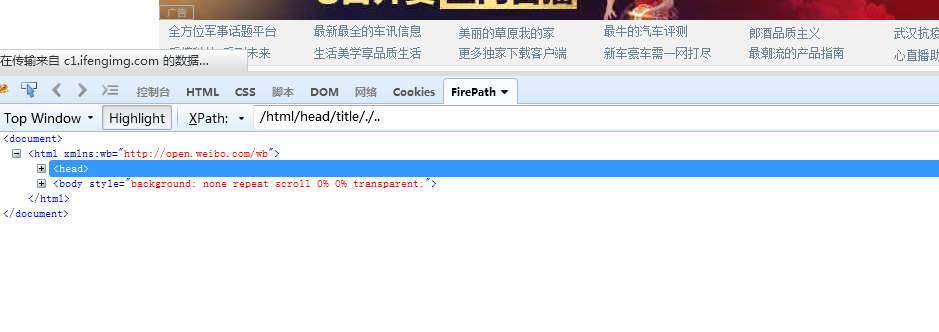
3.使用.和..定位本身和父节点(http://www.ifeng.com/)
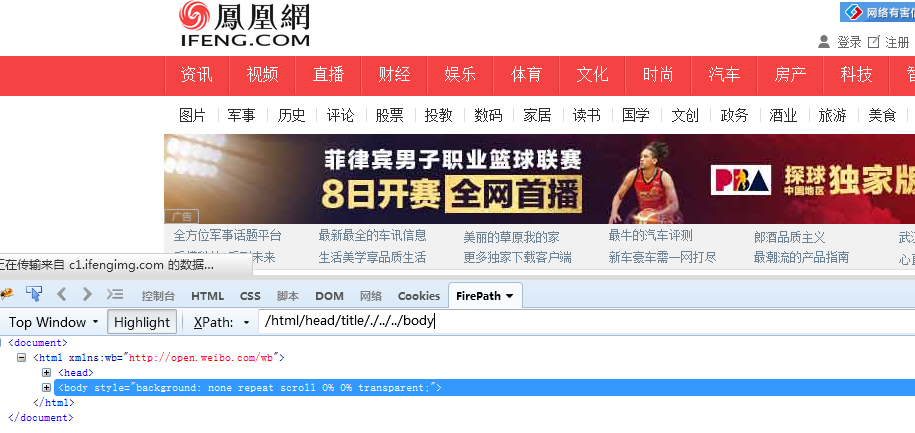
/html/head/title/./.. 使用.定位到title本身再使用..定位到title的父节点
/html/head/title/./../../body 使用.定位到title本身再使用..定位到head节点..定位到html节点,然后在定位到body子节点
查找某个特定的节点或者包含某个指定的值的节点
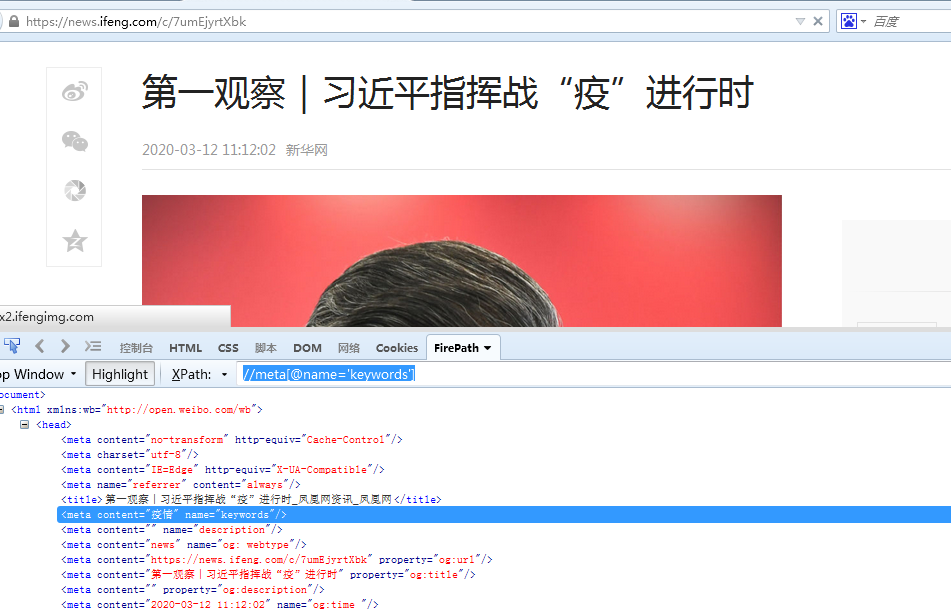
通过@定位 格式 标签名[@属性名='属性值']
//meta[@name='keywords'] 定位到所有的meta,再从中找到name=keywords的那一个
//div[@id] 定位到所有div标签,再过滤出有id属性的节点

选择未知节点
通配符定位节点
//* 匹配所有节点
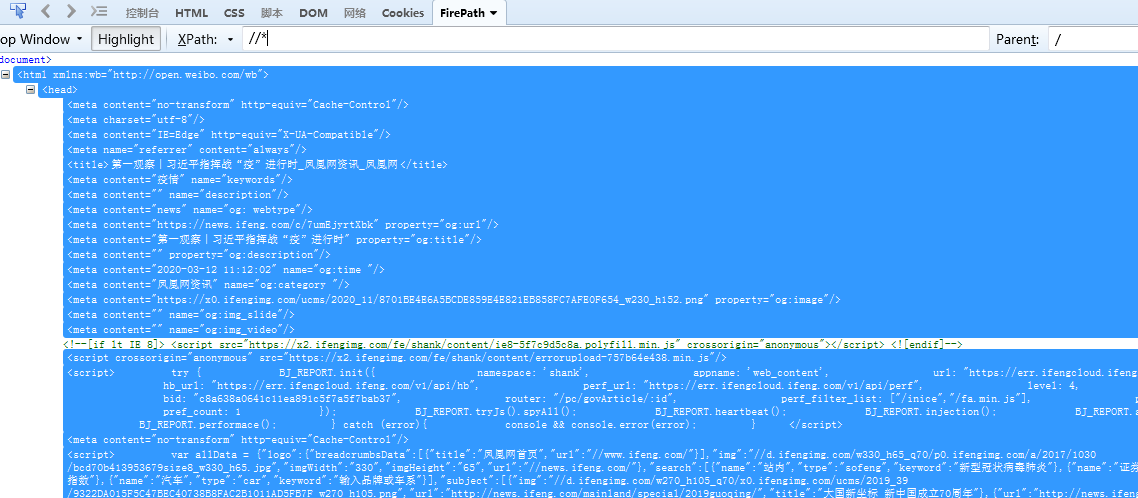
/* 匹配绝对路径最外层,里面的没有匹配到。
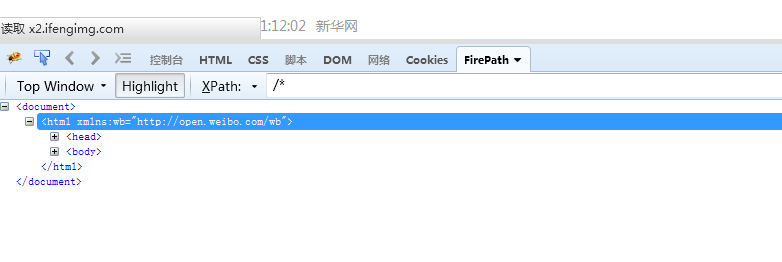
//*[@*] 匹配所有有属性的节点

/html/node()/meta 匹配所有含有meta的节点,node()匹配任何类型的节点。

选取若干路径


糗事百科练习 xpath
//div[@id='content']/div 定位到div父节点含有属性id='content'值的子节点div上。
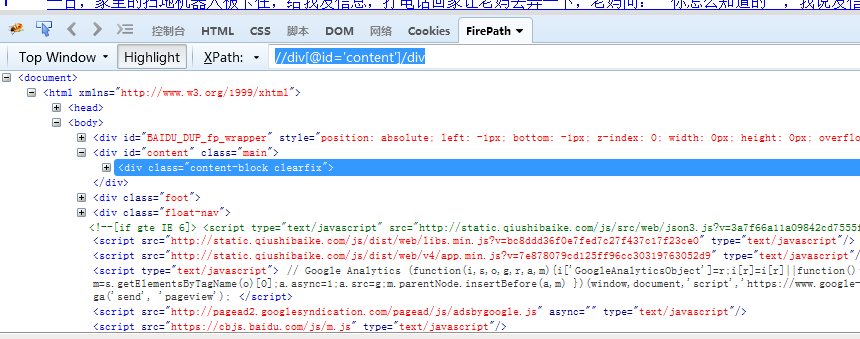
//div[@id="content"]/div[1] 通过索引定位到第一个节点
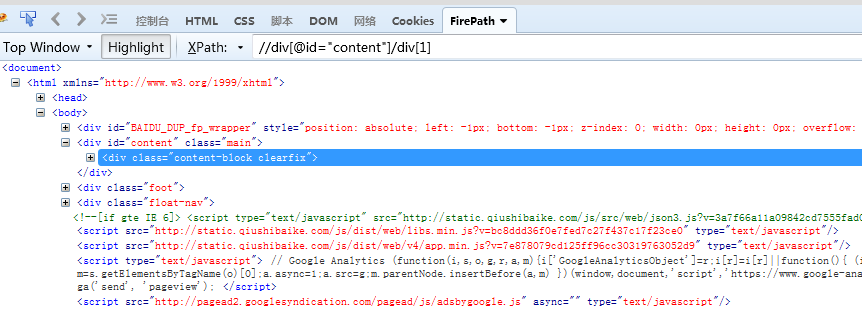
//div[@class="content-block clearfix"]/div[last()] 通过last()索引定位到结果中的最后一个
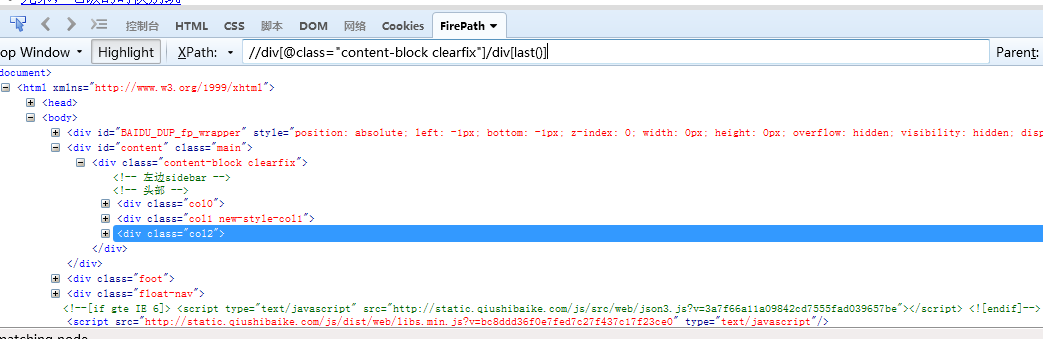
//div[@class="content-block clearfix"]/div[last()-2] 通过last()-n索引定位到结果集中的倒数第n+1个
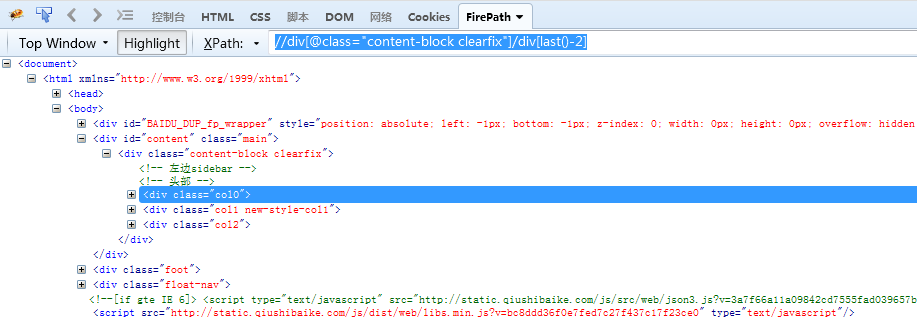
//div[@class="content-block clearfix"]/div[position()=2] 定位到结果集中第n个节点
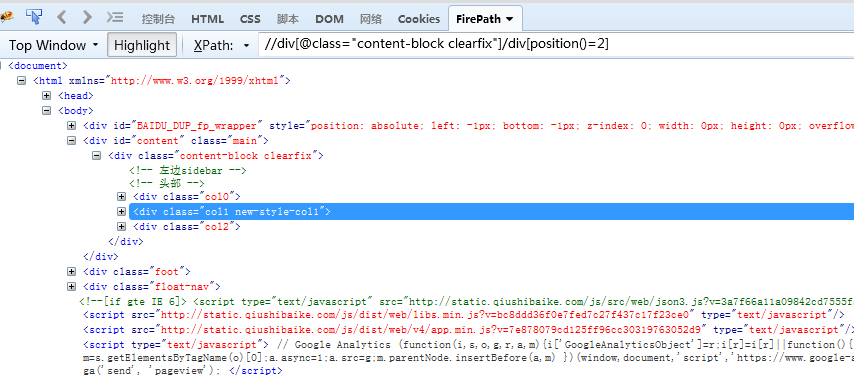
//div[@class="content-block clearfix"]/div[position()<2] 定位到结果集中索引小于n的节点
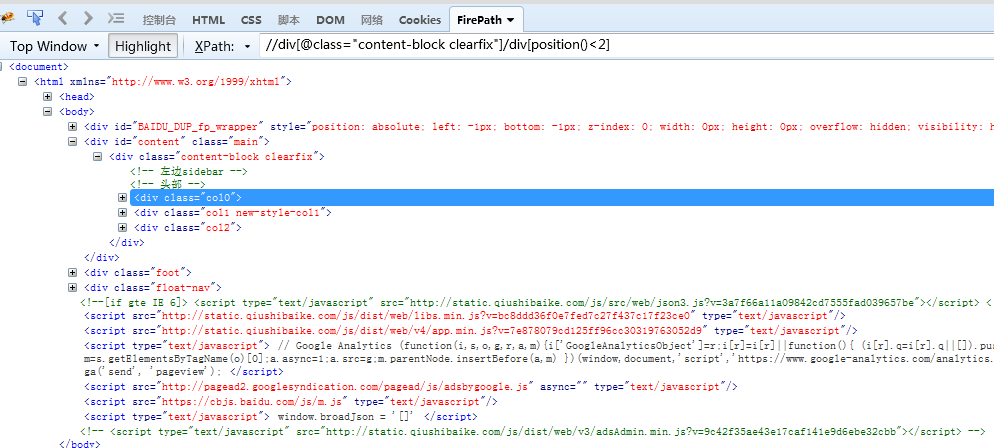
//div[@class="content-block clearfix"]/div[position()>2] 定位到结果集中索引大于n的节点

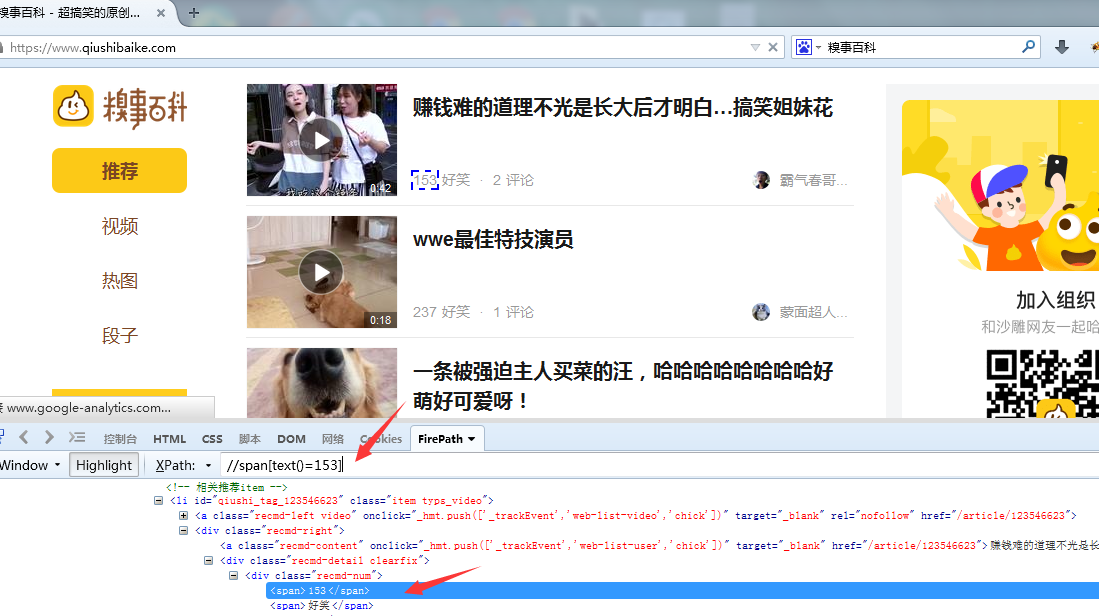
//span[i=n] 定位到好笑计数等于n的节点
//span[i>n] 定位到好笑计数大于n的节点(这是旧的图,新的数值改到span上了,在下面。)

新的数值改到span上了://span[text()=153]
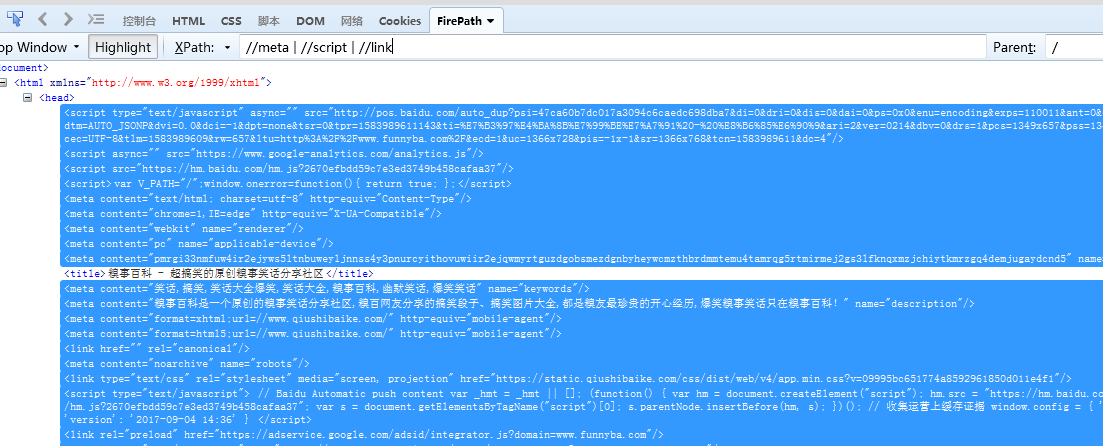
//meta | //script | //link 使用多个xpath,所有xpath的结果都放到一个结果集中
//*[starts-with(@name,'rend')] 匹配以标签属性值以给定值开头的节点

//*[contains(@name,'end')] 匹配给定值在标签属性中的节点

//*[@content="noarchive" and @name="robots"] 匹配同时符合两个属性值的节点

补充:以火狐为例查看元素的3种方法。
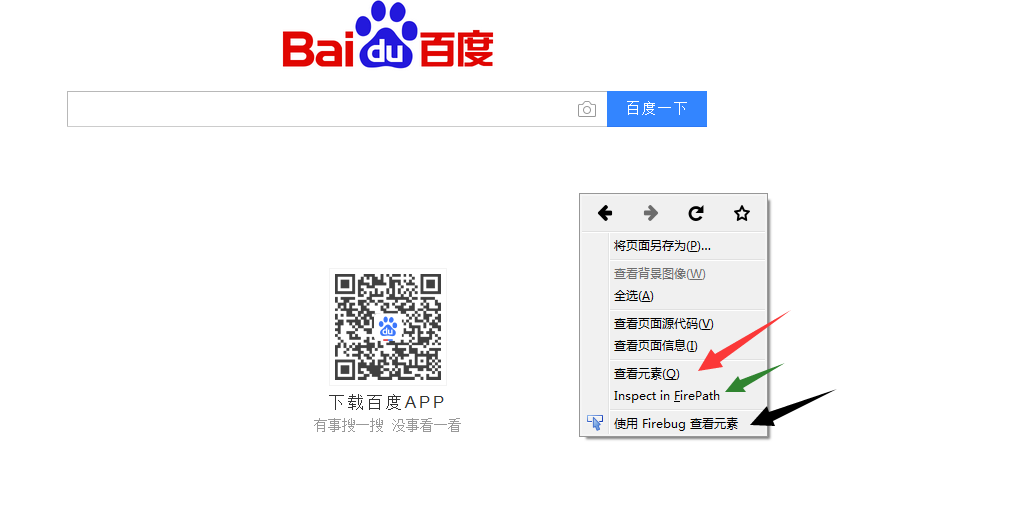
查看元素:官方,推荐使用
Inspect in FirePath:不精准,用的比较多。
使用Firebug查看元素:比较复杂。
不管用什么查看有两条准则:
1. 要在程序验证正确
2. 要精简