本篇博客:Controller场景设置
1.两类三种
2.场景方案
3.多机联合
4.IP欺骗
5.场景监控图
6.负载测试模拟
7.作业
回顾
1.两类三种
1.1 两类三种的介绍:
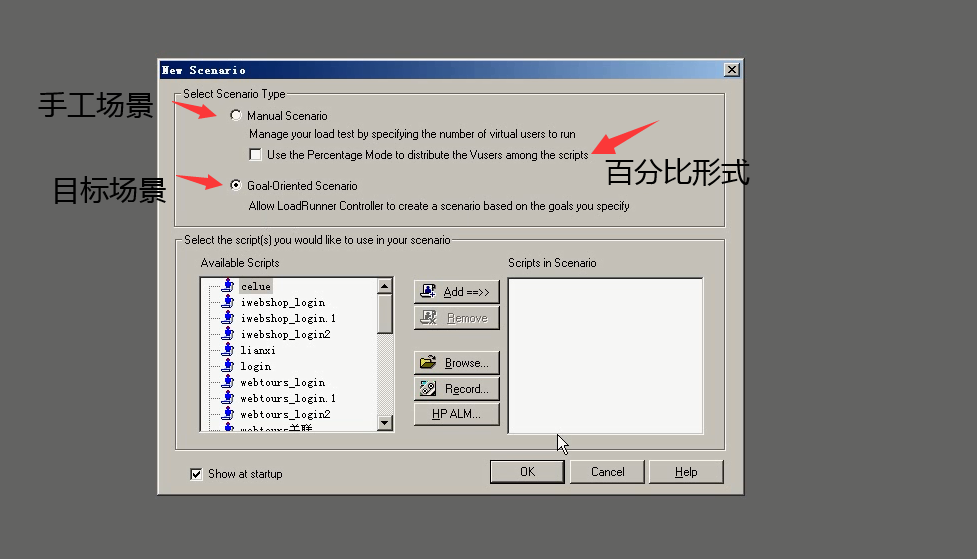
两类:手工场景、目标场景
三种:
- 按照数量的模式打开Controller(手功场景,默认)
- 按照百分比模式打开Controller(手功场景,百分比)
- 按照目标场景模式打开Controller
两类三种表示的是打开Controller的形式有两类三种。
Manual Scenario :手工场景
Goal-OrientedScenario: 目标场景
两种的区别:
目标场景:就是 已经给定你一个目标,你跑性能就是为了达到这个目标
手工场景:就是你对系统不了解,不知道他能经得起几个vuser,要一步一步的测试
1.2 Scenario Groups中的设置
例:介绍一下手工场景,按照数量的模式打开。

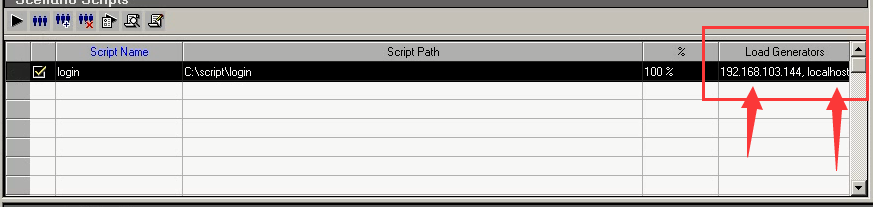
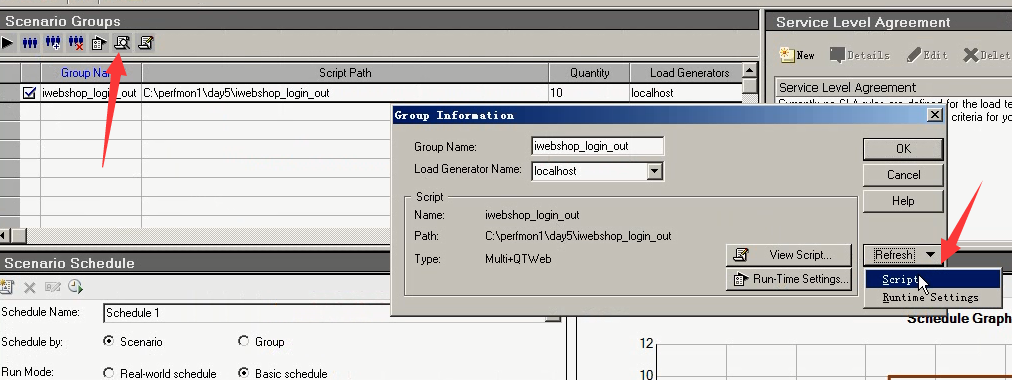
1.通过下面view Script图标,用来打开代码,可进行修改代码。

2.通过Details---Refresh---script:修改完代码之后要进行刷新下代码

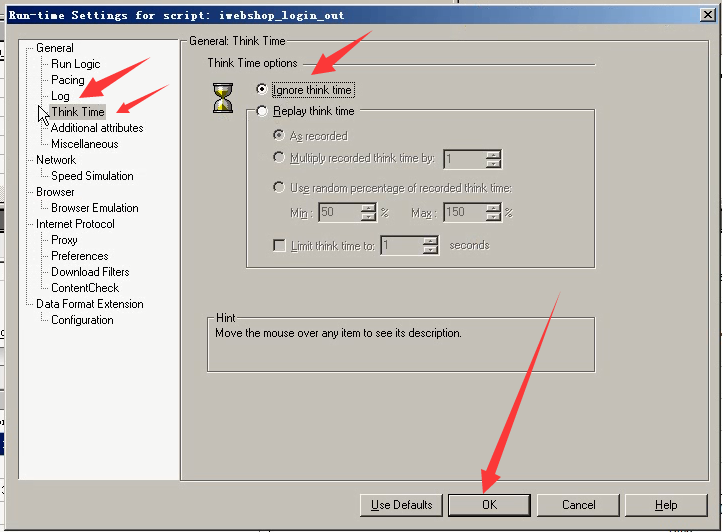
3.Details--Run-time Settings(Controller)
如果不设置靠时间来控制,那就靠Controller中的Run time settings的迭代次数来控制。而不是代码中的run time settings的迭代次数。
- 和代码中的不一样
如果靠时间来控制(设置了持续时间)
- Run Logic 设为1
- Log 选择Enable logging -----忽略log(因为产生日志,也是一种资源消耗,可以关掉。)
- Think Time选择lgnore think time------忽略think time
4.Miscellaneous 选择Run Vuser as a Process------以进程运行,选择Run Vuser as a thread------以线程运行

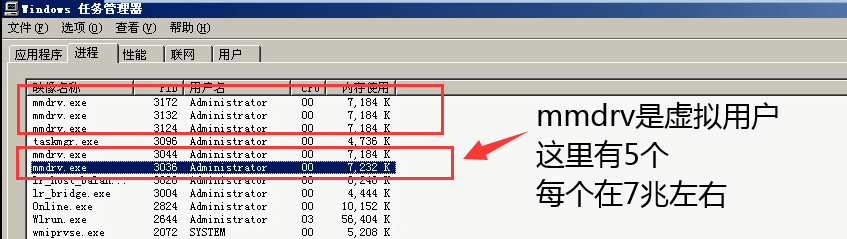
进程和线程运行的区别(5个用户):
按照进程跑:任务管理器中(mmdrv.exe)有5个进程
- 优点:进程独立运行,不发生抢占资源
- 缺点:耗费资源
按照线程跑:任务管理器中(mmdrv.exe)有1个进程,在1个进程中有5个线程
- 优点:节省资源,CPU内存
- 缺点:彼此抢占资源,导致有些线程会失败
例:Miscellaneous 选择Run Vuser as a Process------以进程运行
按如下操作:15秒加载两个用户,开始用户为5个。点击运行。
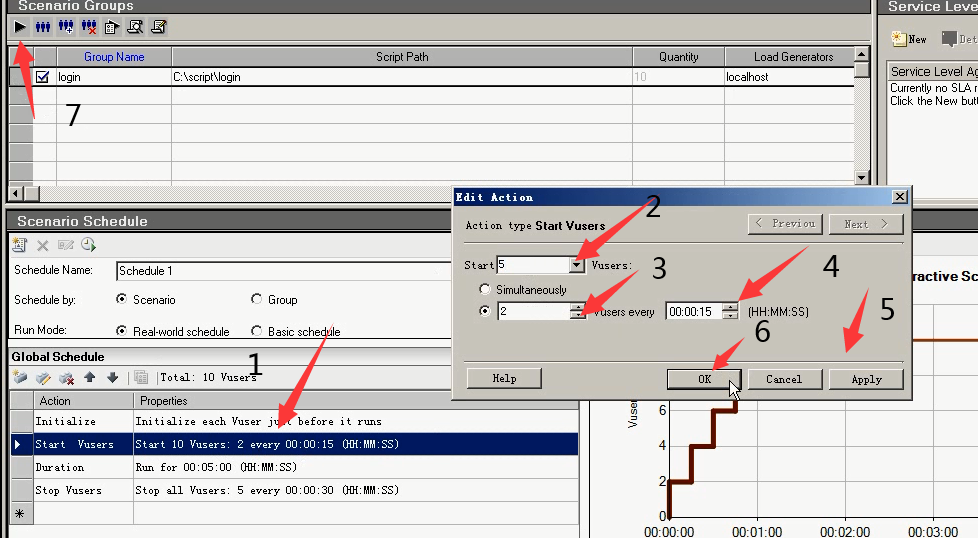
打开进程管理器
再看另一种:先要stop---stop now

以线程开始跑:Miscellaneous 选择Run Vuser as a Process------以进程运行
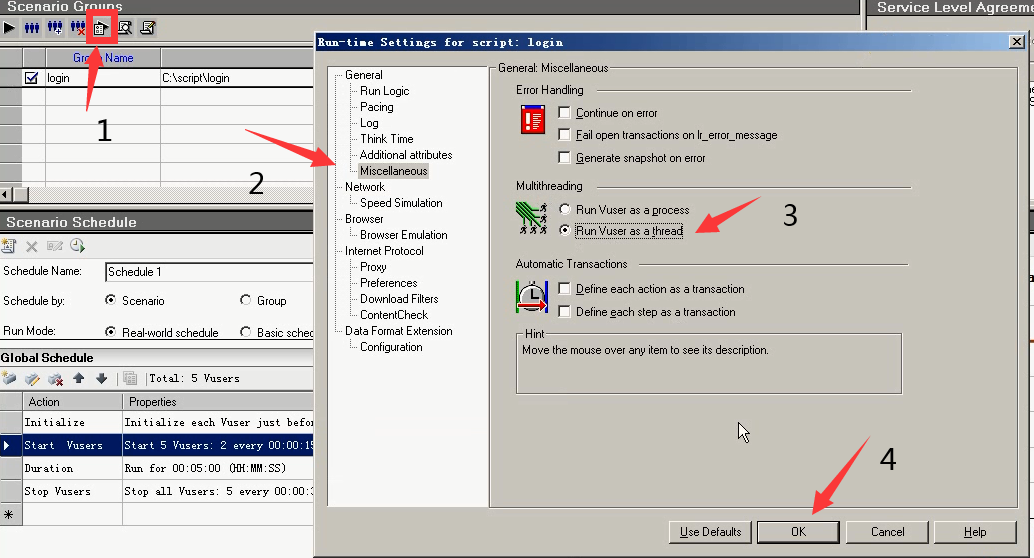
先看一下任务管理器,有没有mmdrv进程。如果没有了,点击运行。运行完,结果如下,5个虚拟用户是1个mmdrv,每个用户大概1兆左右。

Vusers----Add Vusers:添加用户(三个小人图标)
Add Group:添加代码(三个小人加图标)

Controller场景设置
2.场景方案
2.1手工场景
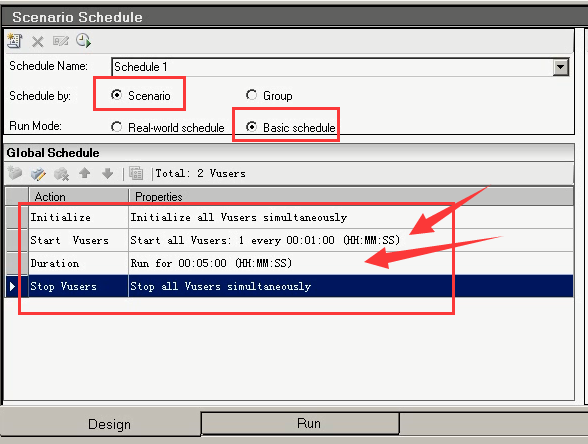
场景方案:
schedule by:scenario ,group
Run mode:real-world schedule, basic schedule
运行过程:
初始化--->什么时候开始vuer_init
加载虚拟用户---->什么开始执行action
持续时间----->执行完1次Action后是否重复
停止----->如何运行vuser_end
1.目的:用于设计用户的添加和减少过程,模拟真实用户请求模型
2.按数量分配:设置用户负载方式
1)通过Scenario Schedule中的Schedule by和Run Mode来设置的
Schedule by :有以下两种
Scenario:以场景方式运行。(可以使多个组按照相同的运行轨迹执行脚本),共用用户量。
Group:以组的方式运行。可以使每一个组有一个单独的运行轨迹。
Scenario和Group的区别:
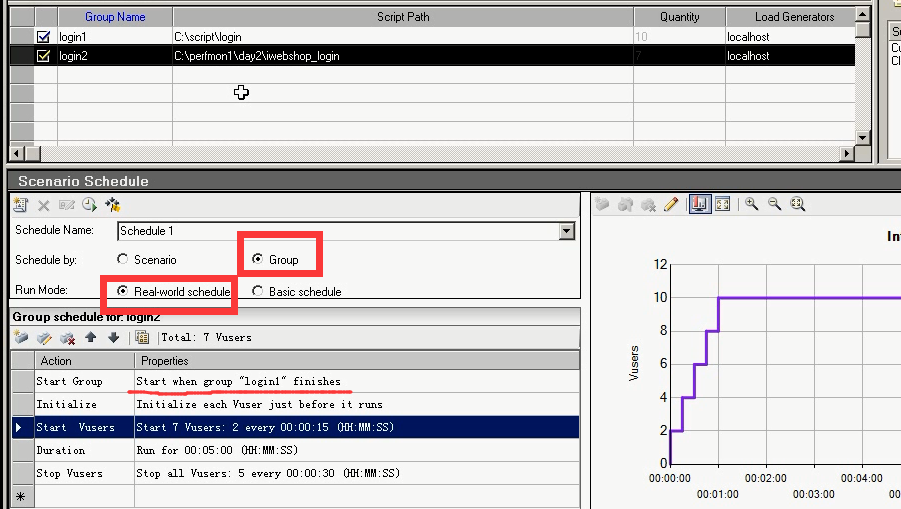
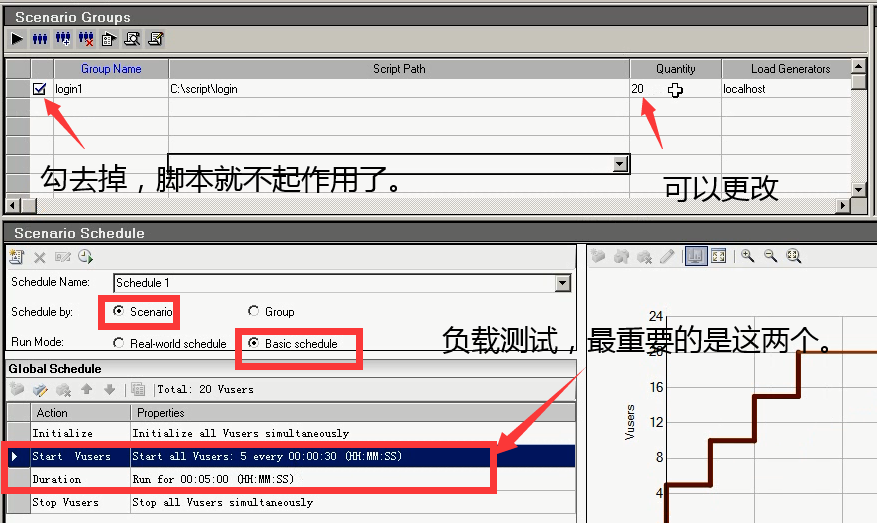
选择Scenario,在login这个脚本上,设置启动用户为20个,持续时间为10分钟。你会发现,这个设置会作用在每一个脚本上面,包括下面的iwebshop_login上面。

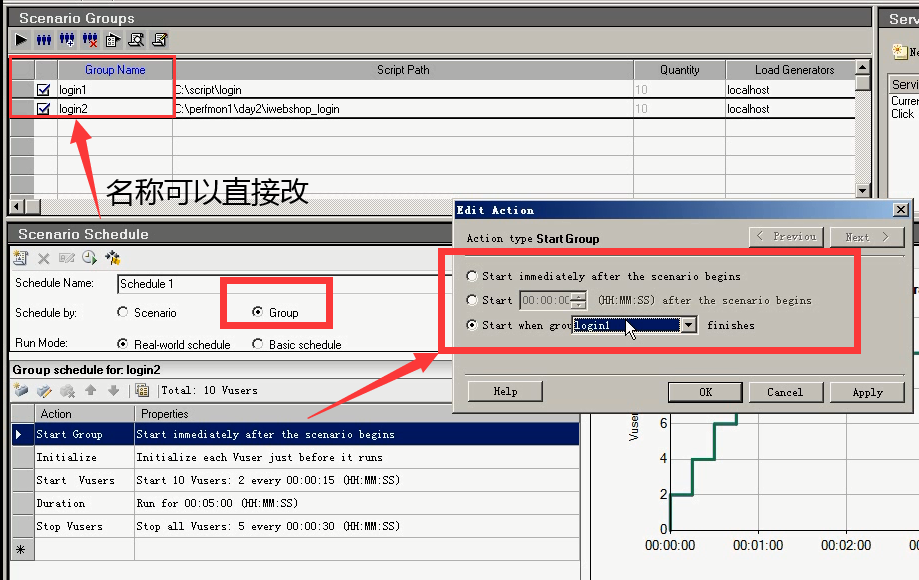
选择Group,会多一行Start Group。点击进去后,有三个选项。
1.当我这个场景开始之后,就直接开始这个脚本(或者说这个组),一当点击运行,这个组就开始了。
2.当我这个场景运行一段时间之后就开始它。
3.哪个组完成后,我再运行它。(可以做多个脚本的衔接。)
假如选择loign2脚本,设置在login1脚本完成后,我再运行它。
Run Modle(运行模式):也有两种
1.Real-world schedule:(实际模式),可以添加一些新的Action。按照公司真实的每一天每一个小时或者每一个阶段,对于该系统或者该项目的访问量,来模拟这个上升(Ramp up)或者下降(Ramp down)的曲线图。
2.Basic schedule:(最基本模式)
start vuser(运行虚拟用户的过程或者运行Action的过程):这个加载的过程我们又叫上升过程(Ramp up)。
stop vuser :Ramp down(下降过程)

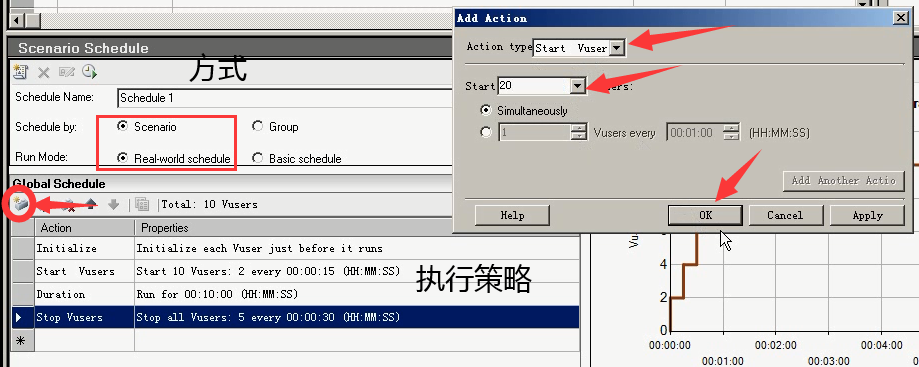
下面的执行策略是可以再添加的。方式随便选两个(Scenario和Real-world schedule)
点击左图标,选择Action:Start Vuser和Strat 20 Vusers。点击ok。(上面的停止之后,再加20个用户。)
这个东西,可以模拟一天,或者某一段时间。该系统的一个用户访问量(简称pv),或者它的一个峰值情况。哪段时间用户量比较大,哪段时间用户量比较小。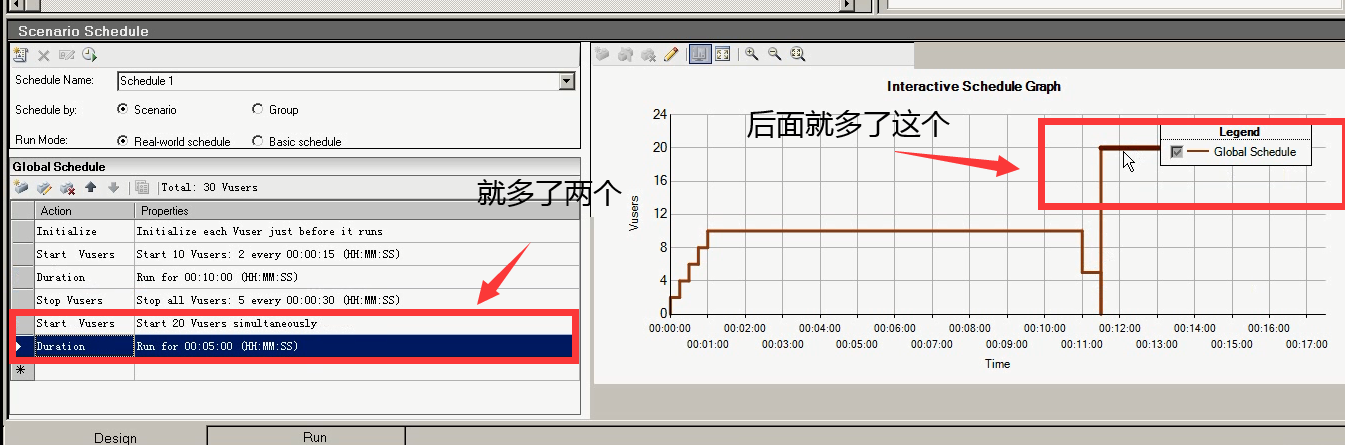
选中一行,点击叉图标。可以删除。
一般我们现在是只要下面4行。(初始化,开始加载,持续时间,停止。),对于这种情况,是因为没有公司一天访问量数据来说,如果知道每天公司访问量,需要画出那张图来,需要根据图来
做。

2)画曲线图
Initialize:什么时候运行vuser
Start Vusers:什么时候开始执行Action
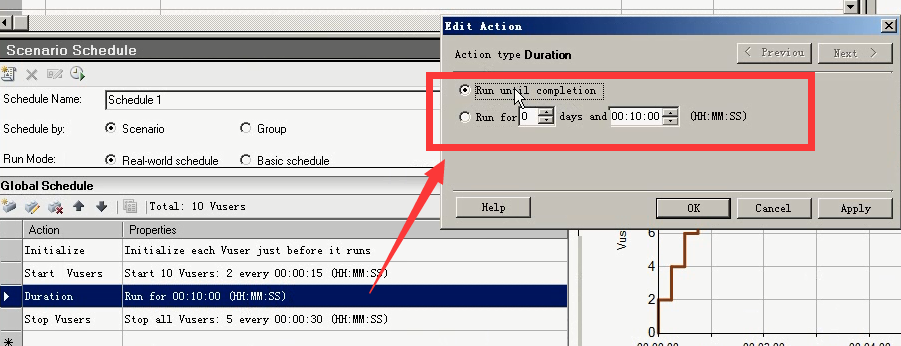
Duriation:
选2,表示持续运行多长时间
选1,表示执行完之后不再执行。
Stop Vusers:选择1.Simultaneously:立即结束 选择2.每多长时间结束几个
点击Add action添加action(模拟实际公司该系统的一个访问情况。)
3) 场景策略
运行方式
组方式:schedule by--->group(各组可以使用不同的策略)
场景方式:schedule by--->scenario(组可以采用相同的策略)
运行模式
基础模式:Basic schedule
实际模式:Real -world schedule
4)设置的几种组合
第一种:Scenario+Real-world schedule
- 多个脚本间按照相同模式跑,运行轨迹时一样的
- 虚拟用户数可以更改。(如下图这里更改)
- 可以继续增加策略,常用来做验收测试

这种方式的组合,可以做验收性的测试。当我们性能测试完成以后,给相应的用户来做演示。我们可以添加多个Action(点击图标就可以添加)。来模拟我们一天,或者某一个时间段内,它的访问
量,运行一次脚本,看看该系统是否能够支撑这个东西。

第二种:Group+Real-world schedule
- 多个脚本之间按照独立设置模式跑
- 可以 设定多个组之间的首尾衔接
- 常用于做独立功能的性能测试
可以把每一功能,放在一个单独的组(脚本)里面,来做性能测试。做完之后,可以再做下一个功能测试。
第三种:scenario+basic schedule
举例:同时初始化+同时启动+指定持续时间+同时停止---》可以做性能测试、压力测试
举例:同时初始化+分阶段增加虚拟用户+指定持续时间+同时停止----》可以做负载测试
例:负载测试。Strats Vusers:每多长时间加载多少用户:。Duration:需要调一定的时间,必须要有运行时间。不能选择选择运行完就结束。初始化和停止都随便。
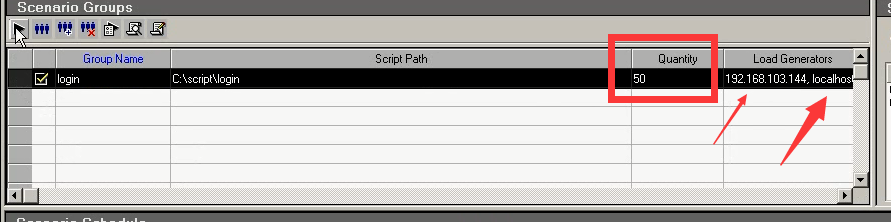
3.按百分比分配
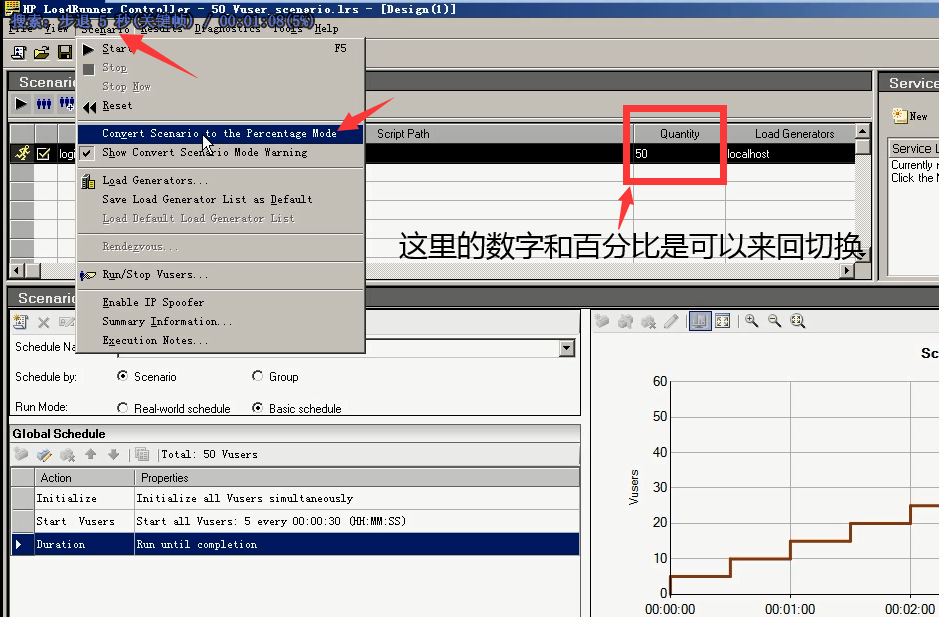
点击Yes。百分比,是没有Group,所有脚本按一个策略去跑的。不可以单独设置某一个脚本。
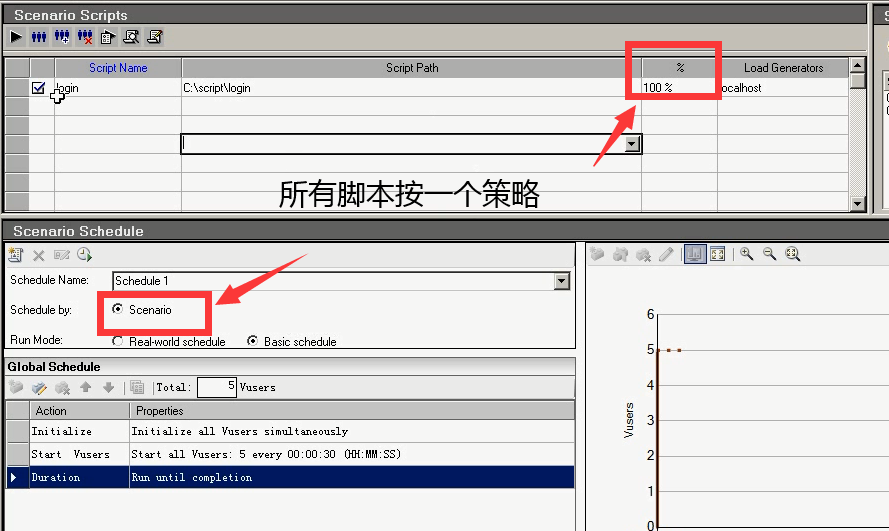
注意:一般都是按数字去运行的。
2.2 目标场景
基于目标场景:常用来做验收演示
例:200个用户同时操作,吞吐量达到一定值,响应时间达到一定的值。
注意:一般我们还是手工场景,按数量分配。
3.多机联合
我们在去运行脚本的时候,脚本的运行是通过Controller去控制的。控制我们的压力机来做的。很多时候,我们会发现,当我们的Controller和我们的压力机在同一台机器上,即运行着我们的
LoadRunner(Controller),又运行着压力机。 测试机受到了本身的LoadRunner跑的过程中的影响,测试机本身就会造成内存不足,或者cpu过高的情况。测试机可能会出现这样的情况,为了避免
这种情况,我们通过Controller去下达命令,由多台不同的压力机去执行我们相应的脚本。由其他机器执行我们的脚本。
那么想要其他的机器也能执行我们相应的脚本。那么必须在其他机器上装有Load Generator(压力机),你可以不装LoadRunner,但必须装压力机。
其他机器作为我们的压力机跑的有哪些? 怎么做的?
windows系统可以作为压力机---->开启代理:LoadRunner Agent process
Linux系统可以作为压力机----->Linux上只可以装Load Generator
多机联合:是多台机器安装客户端(LoadRunner,又叫压力机,负载机或者测试机。),多个客户端联合而已。
- 实现压力机和控制器分类
- 可以指定多台压力机
- 由控制器下达命令运行压力机
多机联合
1)打开路径:在场景controller中选择load Generators

2)添加新的压力机
1.在测试机上安装load Generators(可以安装在linux上,也可以安装在windows上。)
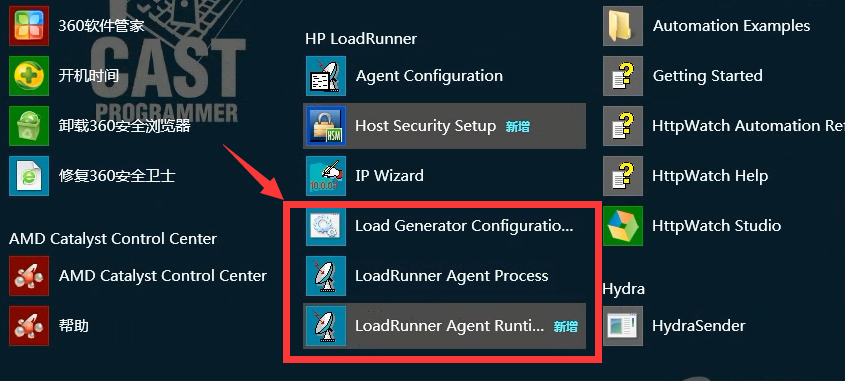
注意:windows上可以安装load Generators和LoadRunner。Linux上只能安装load Generators。
2.开启LoadRunner Agent precess:开始--->所有程序-->HP Loadrunner--->Advanced settings-->Loadrunner agent process
3.防火墙关闭(测试机上的)
4.添加
load Generators---Add----输入负载机的IP以及OS(操作系统)即可
一般很少拿linux作为压力机。
注意:如果是Linux的压力机,一定要在more---unix environment选项卡中设置勾选 don't use RSH。
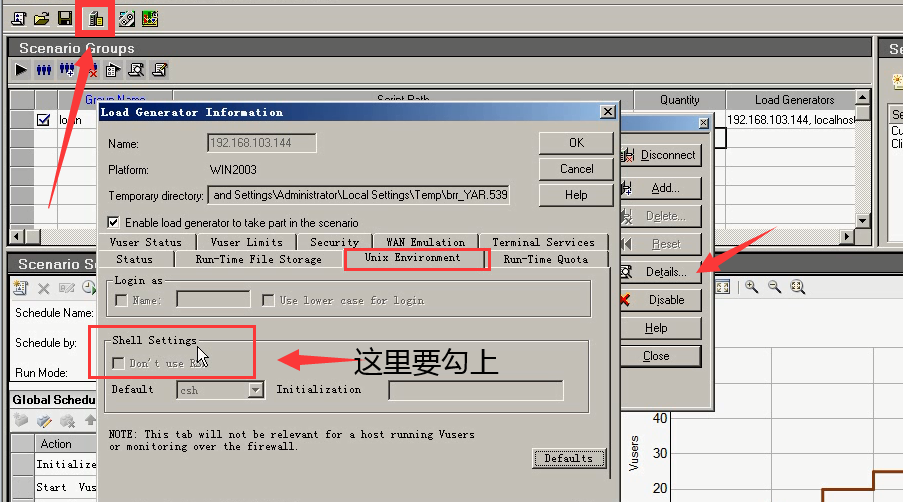
3)添加压力机的标准依据
1.被测环境和压力机要在一个局域网内
2.压力机本身的系统资源
- 1.内存,cpu
- 2.压力机资源占用率不超过80%
例:多机联合
1)别的上单独装有压力机(load Generators)
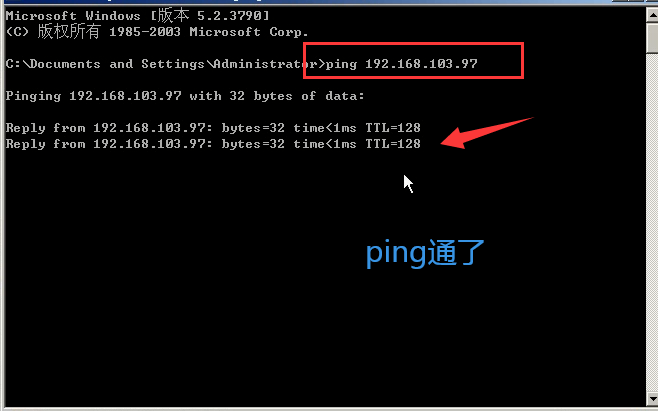
2)看一下它的ip:cmd------ipconfig

3)ping一下上面的ip
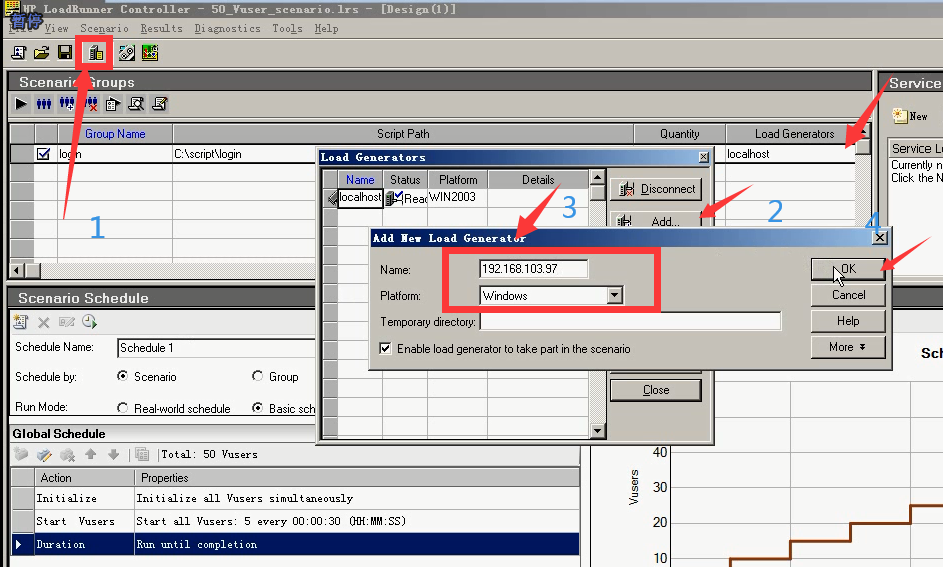
4)选择97的作为我们的压力机,按下面的4步进行操作,点击ok。
可以选小房子添加,也可以选localhost的三角符号添加。
5)就出现了这台压力机,点击connect进行连接。
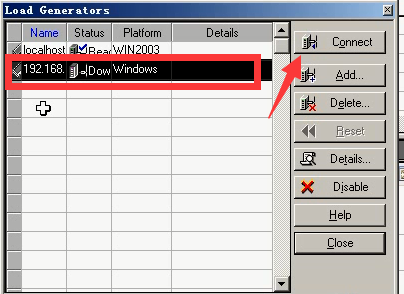
6)出现Ready,表示能连上,说明代理起来了。
代理在开始菜单里面,LoadRunner Agent Process。(想要连的机器上,需要安装这个。),把代理起起来后,就可以ping它了。

7)从这里选97的。

8)开启前两个。
9)点击这个修改一下脚本的ip。写脚本的时候,千万不要带有localhost。

10)ctrl+h:换成97的。要让97来跑121的。代码就是简单登陆。保存一下脚本:file-save

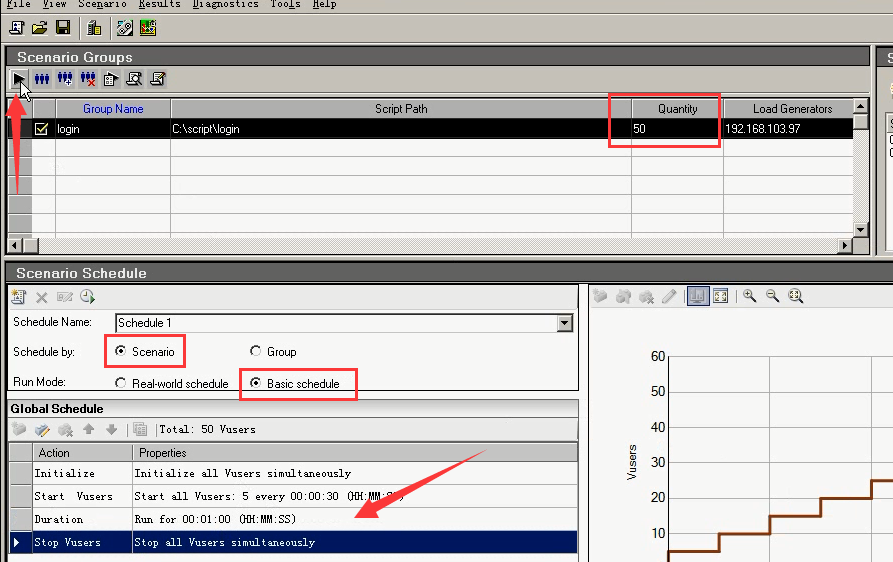
11)刷新脚本,点击ok。

12)设置50个用户,运行1分钟。
13)迭代设置1次,日志关闭,忽略思考时间。以线程跑。
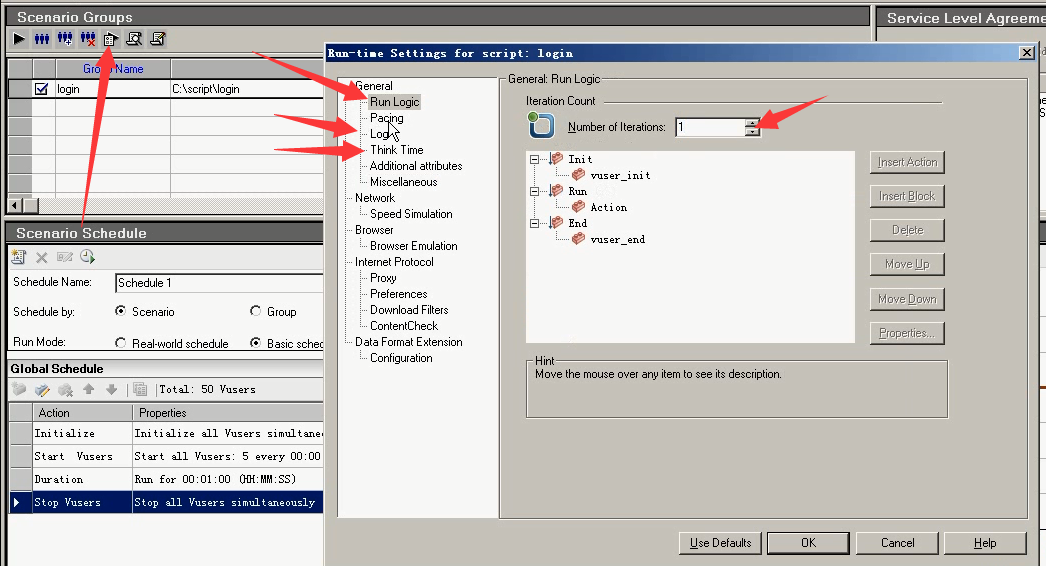
运行的时候,以线程开始跑。

14)点击运行,点击确定。报错,是操作系统的问题。
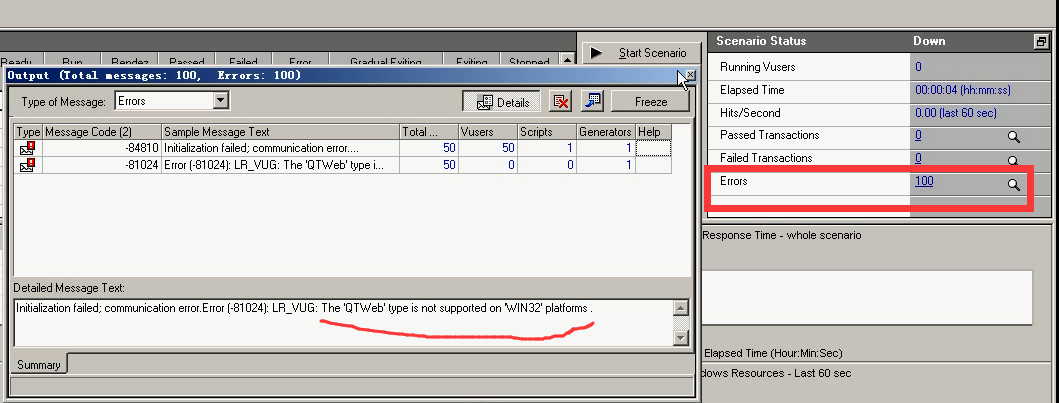
15)开启另一台,换成2003的。

16)把之前的断开,删除。
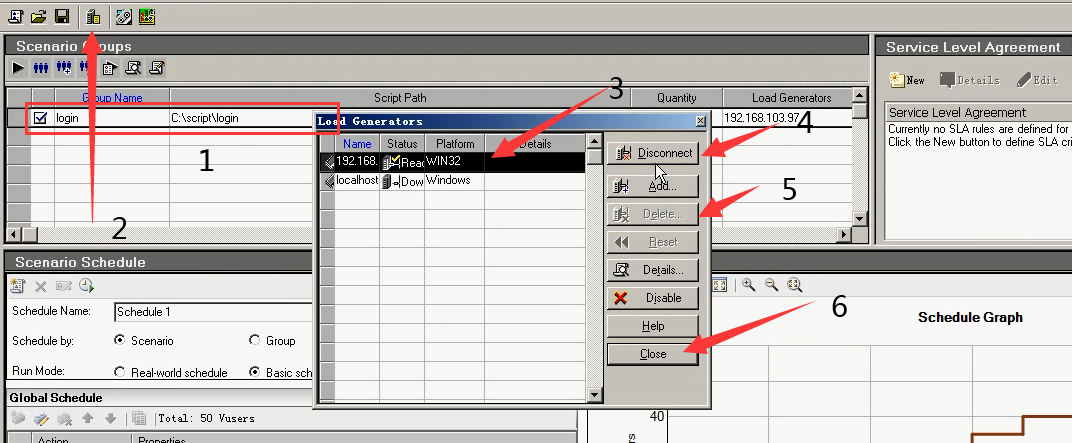
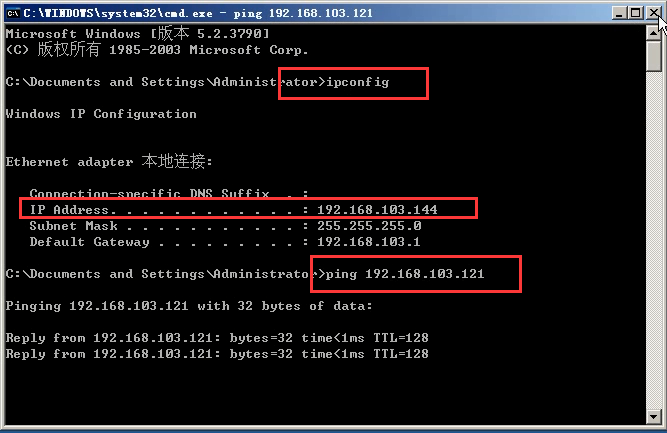
17)看一下ip(144),ping一下121的。能够ping通。
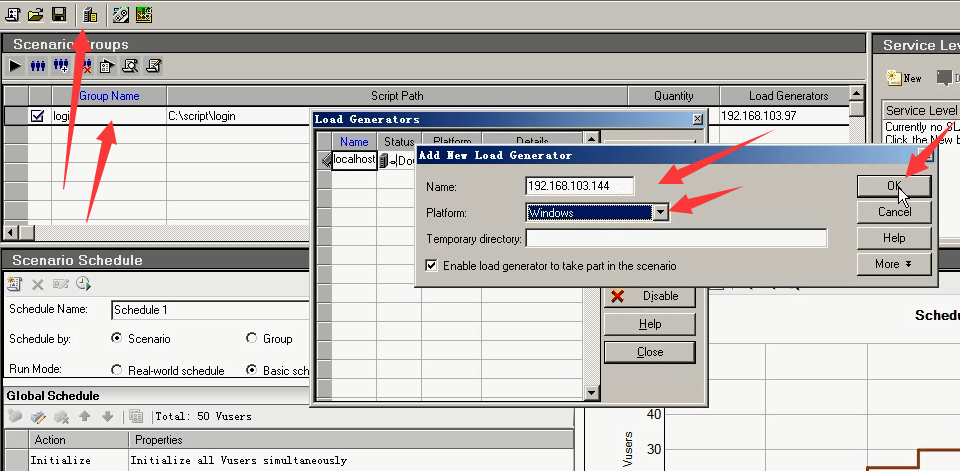
18)选中login脚本,点击小房子---Add---填写144的ip。windows作为操作系统。点击ok
19)选中144的,点击connect---出现Ready(表示连接成功)-----点击close。
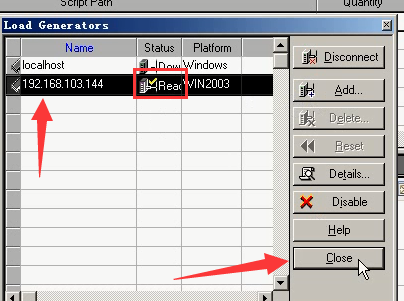
20)选上144,点击运行。
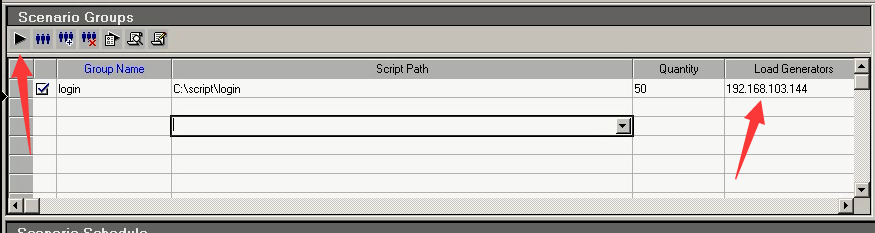
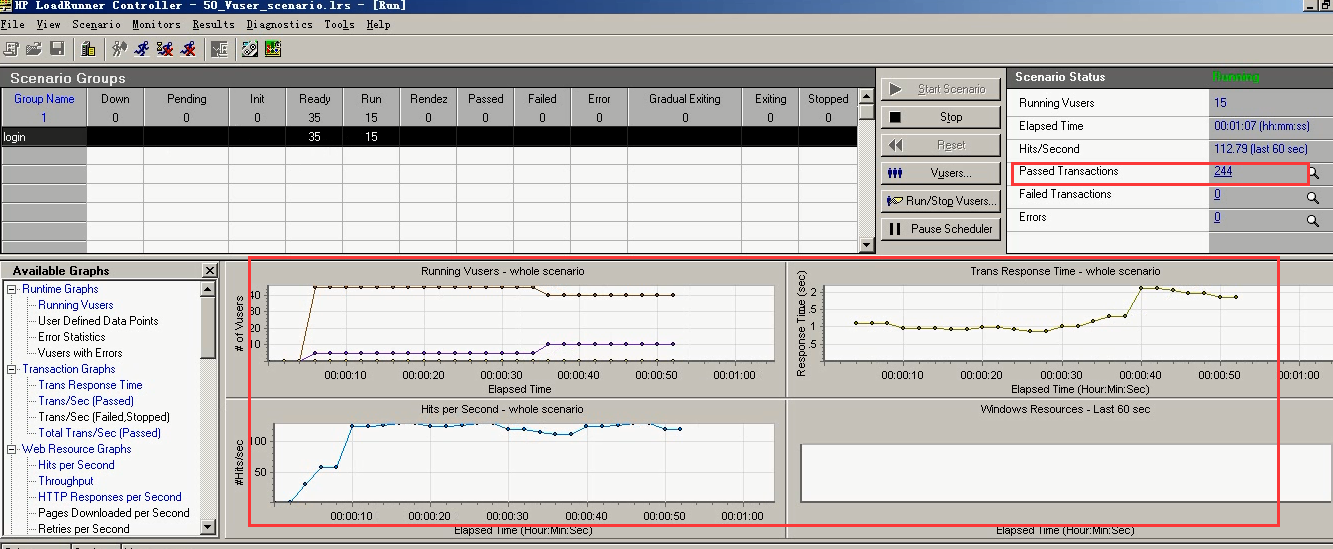
21)144的机器在跑,跑的是121的脚本。成功了。
22)想要多台压力机来跑(现在是一个其他压力机来跑的),需呀先切换到百分比模式。点击是。
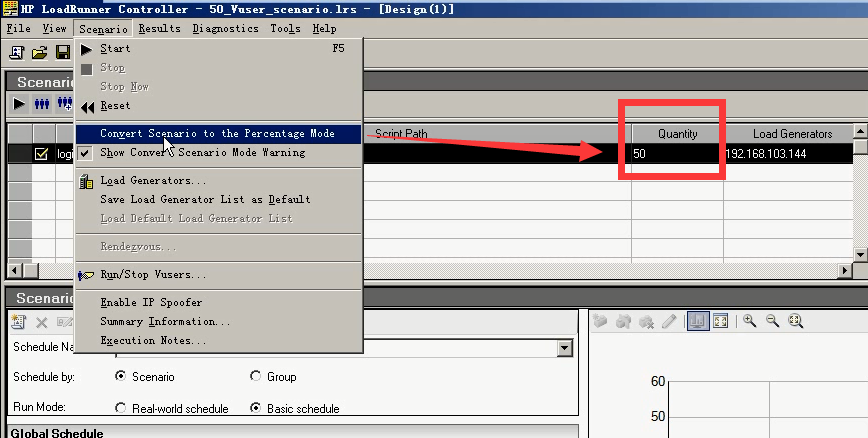
23)切换到百分比模式后,就可以一次性选择两个个。点击ok。

24)长这样子。
25)还可以换回数字,发现还有两台压力机。
26)两台压力机上在跑,也没有什么问题。任务管理器,可以看cpu的使用情况。这里是100%有点问题。弄好之后,可以stop---stop now一下。

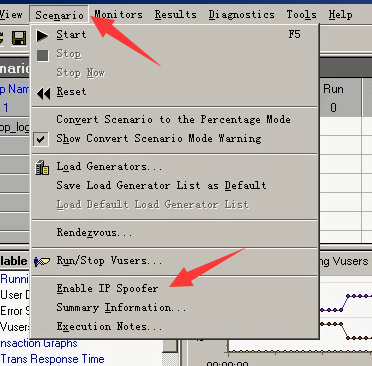
4.IP欺骗
IP欺骗:适用于局域网
为每个vuser分配单独的ip地址(虚拟ip)
注意:当使用完IP欺骗后要进行释放(释放方法:直接关闭IP Spoofer,或者在计算机网络里,高级配置中。把一个个删了也行。)
当服务器屏蔽工具时,可采用IP欺骗功能
前提:当前的网卡设置必须为静态IP,非DHCP分配。将网络从自动获取改为手动获取方式。设置完成后,可以ipconfig查一下ip。看是不是和以前一样。
在开始---控制面板---网络连接---本地连接----属性----Internet 协议(Tcp/IP)

例:IP欺骗
1.开始---HP-loadrunner--tools--IP-wizard

2.create new settings

3.输入服务器IP
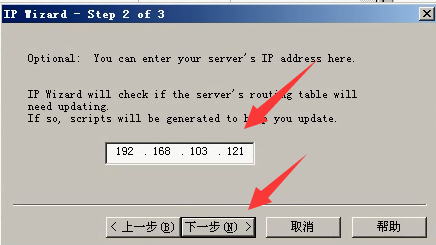
4.点击Add按钮添加
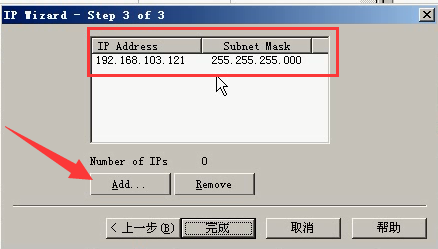
5.选择IP分类,填写IP起始点,以及个数

常识:A类IP和B类IP和C类IP(我们用的是C类)

6.点击Ok,完成
可以保存下来。点击save as.

保存完后,点击ok。就会向这台机器里面写入ip

在开始---控制面板---网络连接---本地连接----支持----详细信息。就可以看到设置的ip的地址。
也可以在开始---控制面板---网络连接---本地连接----属性----Internet 协议(Tcp/IP)------高级。也可以看到设置的ip的地址。
7.打开DOS窗口,输入ipconfig来验证。(你会发现有很多IP)
8.打开Controller控制器----选择Enabled IP SPoofer
右下角出现这个:说明IP欺骗开启起来了。

9.在Tools菜单下勾选Expert Mode
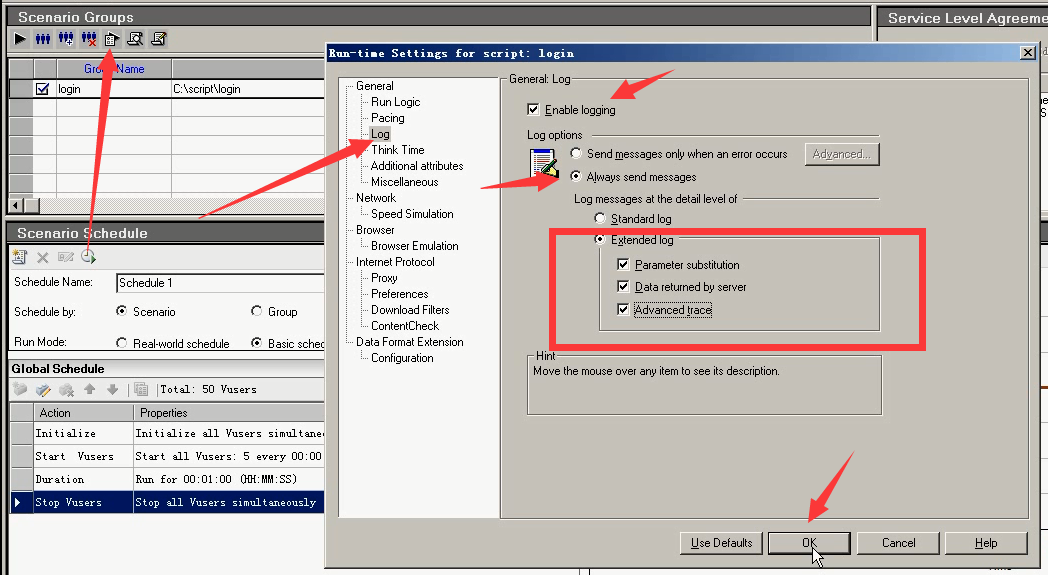
10.在Run-time settings中选择Log--->勾选Extended log--->勾选所有的扩展信息
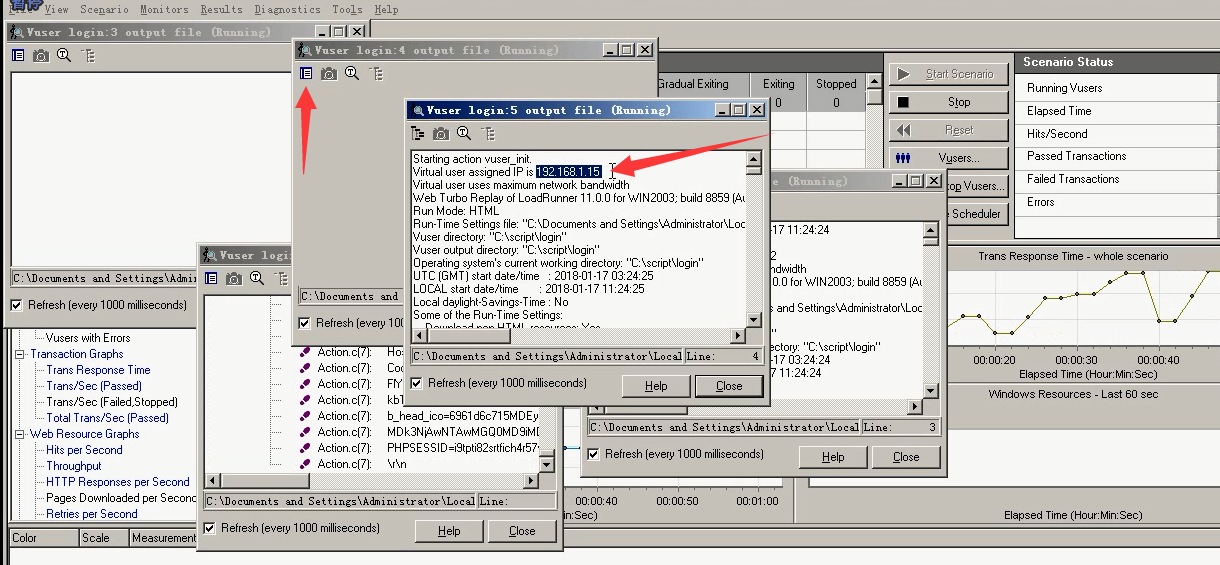
11.运行脚本,查看,通过选中Run 5---show vuser log。每一个用户都是使用自己的IP。有可能出现比较卡的情况。
当IP欺骗做完以后,想要释放掉:
1)在开始菜单中找到IP Wiazrd
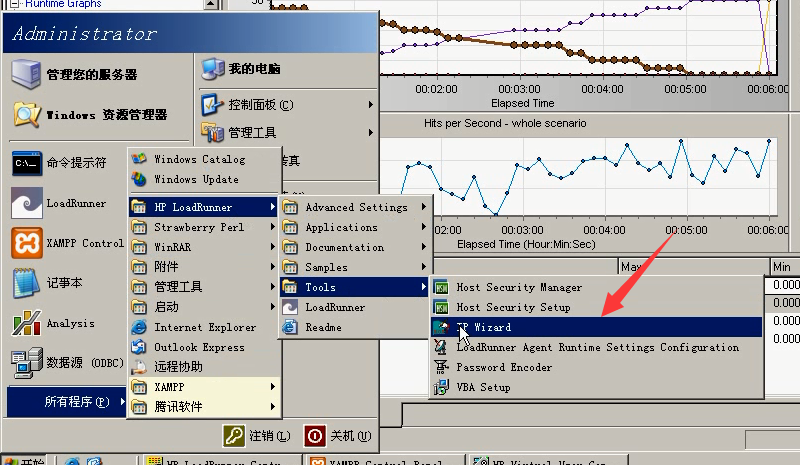
2)选第三个,点击下一步。
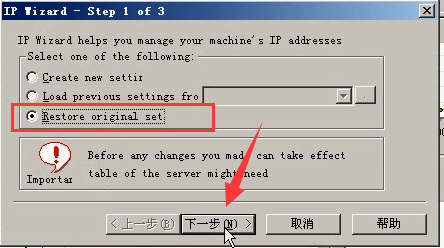
3)输入服务器IP
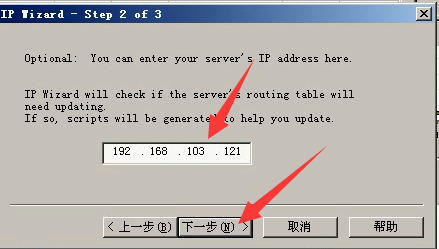
4)点击完成
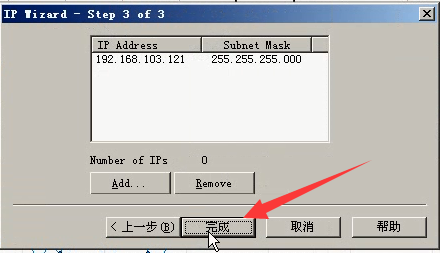
5)直接点击ok

6)就会全部释放掉

7)可以看有没有全部释放,如果全部释放了,把原来的地址加上来就行。
下次用的时候,可以把IP欺骗关了:点击Scenario-------点击Enable IP Spooder
关了,下面就没有蓝色小图标。(因为有的时候不想要IP欺骗,没关运行脚本就会报错。)
5 系统监控
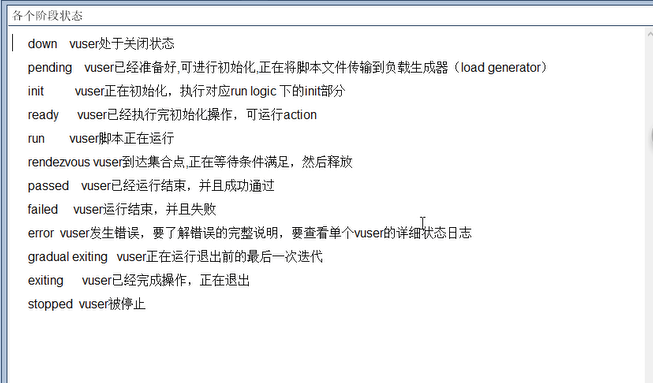
5.1 各个阶段状态(对于用户运行状态来说):
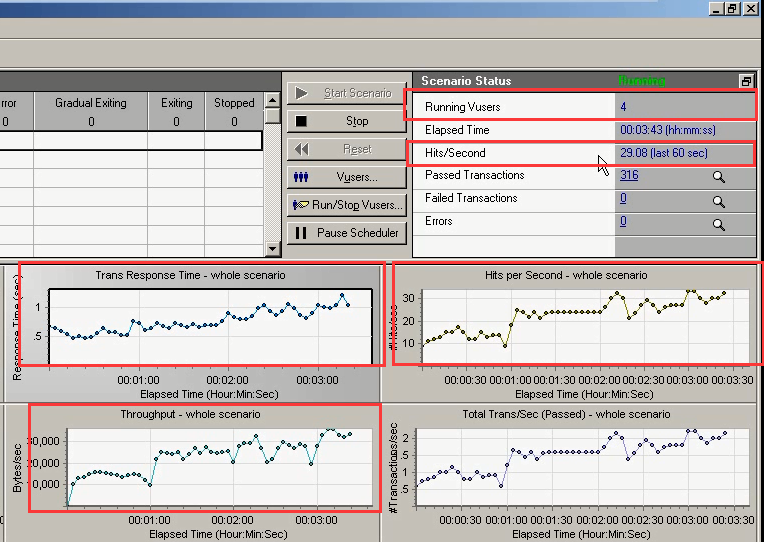
5.2场景监控图
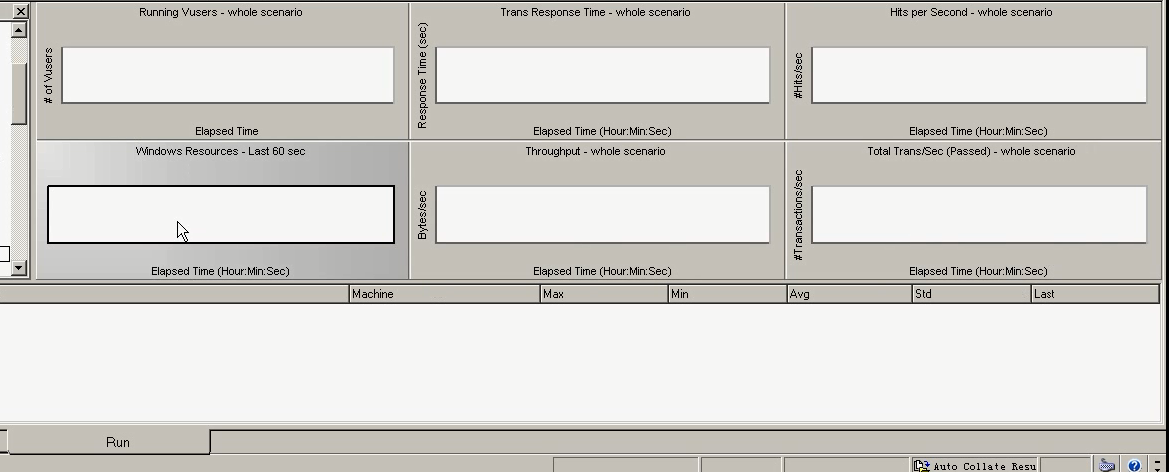
监控的六张图
第一张图表:Running Vusers (每秒)运行的虚拟用户(在RuningVuser Graphs里。)
第二张图表:Trans Response time (事物的)响应时间(RT),来源代码中的事务,事务增加,RT增加(在Transaction Graphs里)
第三张图表:Trans/Sec 每秒的事务,成功数(TPS)(在Transaction Graphs里)有成功数,也有失败数。
第四张图表:Hits per Second 每秒钟的点击数,或者每秒钟的请求数,或者每秒的并发请求数,每秒向服务端发送的请求次数(hits/s)(在Web Resource Graphs里)
第五张图表:Throughput (吞吐率) 每秒服务端返回的字节数(在Web Resource Graphs里)
第六张图表:System resources(系统资源):分为windows resources(当前服务器的性能指标,下面讲的是这个)和Linux(但是对于服务器来说,更多的是Linux)。
Linux:rpc服务和nmon工具(下一篇博客会讲)
第六张图表参数:windows Resource Graphs
1.可以通过LR自带的计数器监控。Linux:需要安装rpc进程
2.也可以通过第三方软件监控。nmon/cacti等等
3.可以命令监控。http://www.linuxde.net/
4.常见计数器:
1)Processor
- % Processor time:处理器时间百分比
- %userTime:应用程序使用时间
- %privlieged Time:windows自身使用cpu时间
- cpu队列长度
2)内存
- 可用内存
- page/sec
- page reads/sec:每秒从磁盘读取的数量
3)磁盘:PhysicDisk
4)网络:Network Interface(Bytes Total/sec:接收和发送的总数)
例:详细介绍6张图表
1)第一张图表:跑的运行用户数量:Running Vusers
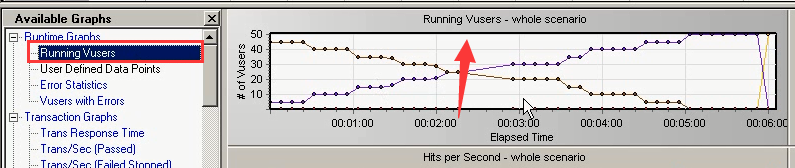
横坐标是:时间。纵坐标是:当前运行的用户数量。可以看出是多少秒加载完几个用户。随着时间发生变化,用户数量也在发生变化。每15秒加载5个,就按照这个规律加载进来。假如我们设置1分
钟持续时间停下来。它就直接停下来。相应的完成的用户量在增加。

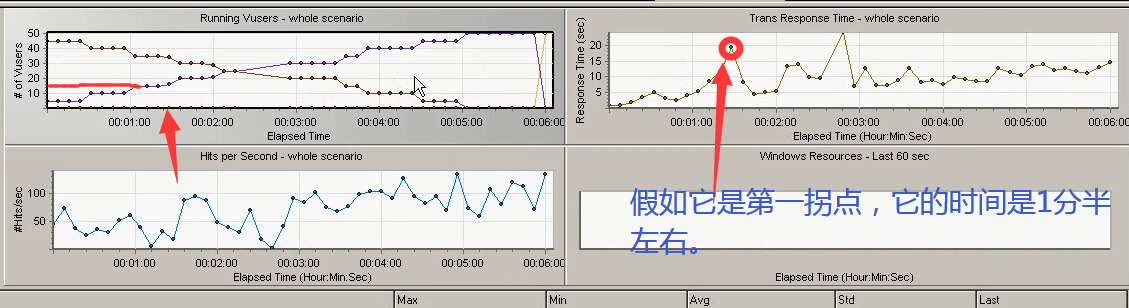
2)第二张图表: 事物的响应时间图表:Trans Response Time

横坐标是:运行时间。纵坐标是:事物的响应时间。取点:每隔15秒取的点,它取的点不一定是哪一个用户的。只是在这个时间点上取到了一个就放过来。
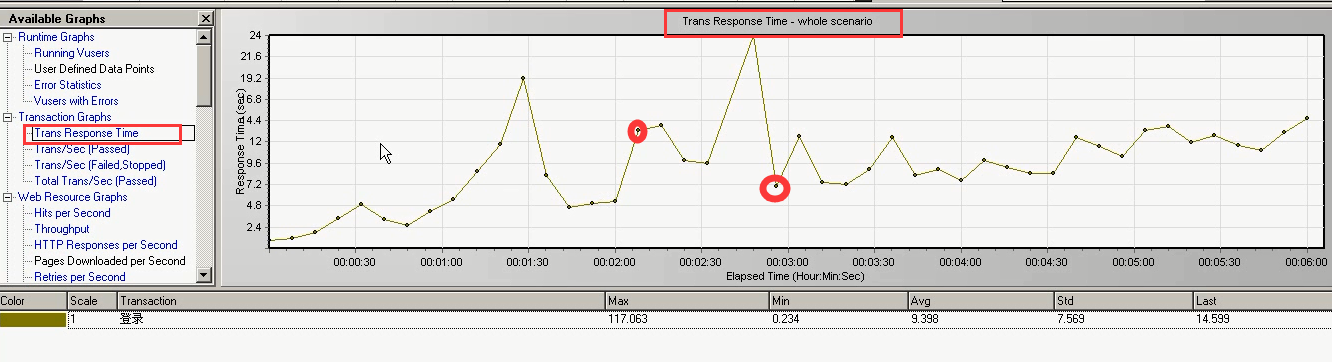
可以根据响应时间图表和用户数图表。来去确定最佳的用户数量,和最大用户数量。
举例:在响应时间图表中,找到第一拐点。看它对应的时间(1分20秒),在用户数量表中,相同的时间里,对应的用户数量。就是最佳用户数量(15左右)。
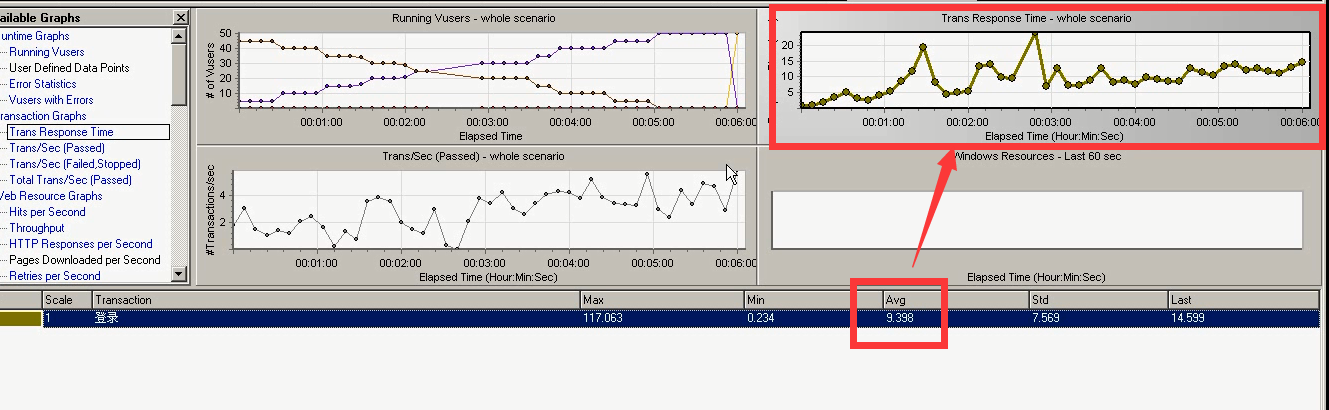
3)第三张图表:每秒钟通过的事物的数量:Trans?Sec (Pass) 可以判断服务器的处理能力。
横坐标:时间,纵坐标是:每秒钟事物的处理数量。

每秒钟的通过的事物数量,可以通过响应时间表中来计算。(结果和每秒钟通过的事物的数量表的差不多)。
假设:响应时间: Avg为0.25秒。(通过一个事物的平均时间为0.25秒)
1秒通过的事物数为4个(一个用户在1秒内可以通过的事物数为4个。)
在1秒内,15个用户通过的事物数量为60个。
4)第四张图表:(Web Resource Graphs)Hits per Second: 每秒钟的点击数,并发数,每秒向服务端发送的请求次数(hits/s)
横坐标是:时间 纵坐标是:每秒钟向服务器发送的请求数量。(可以理解为并发数)

可以自定义数量
选中任何一张图表---右键-----View Graphs -------Custom Number

假如想看到6张图表。往上加到:6。点击ok
就有6张图表了。
5)第五张图表:Throughput (吞吐率) 每秒服务端返回的字节数
反应的是服务器的处理能力,还反应了服务器的带宽消耗。
纵坐标是:每秒的字节数。(压测的时候,对于吞吐的监控,可以知道每秒的字节数。想要知道服务器的网络带宽有没有问题,可以把单位:每秒的字节数转换为每秒的兆币。
6)第六张表:windows Resource Graphs:windows服务器的性能指标

你会发现是空的,因为没有设置监控服务器的什么资源。
1)首先要添加计数器:Add Measurements
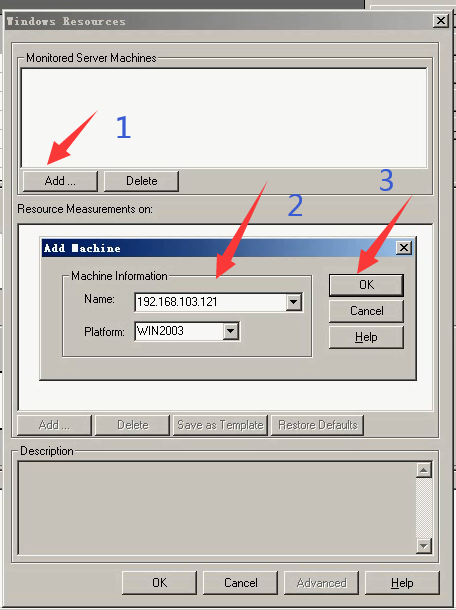
2)填写服务器(放脚本的服务器IP或者名称)
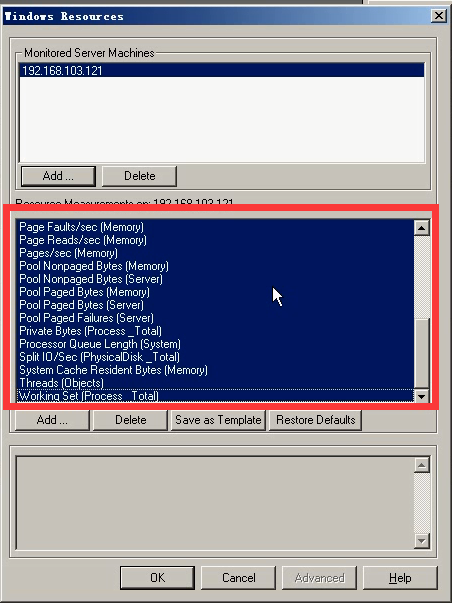
3)会生成很多信息,但是我们只要挑选一些我们需要的。所以全部删除。
4)想要监控cpu的使用率。点击Add-----Object(类型):Processor--------Counter(某一类型的具体信息):% Processor Time------Instance(几核cpu):Total-----点击Add(就可以了)
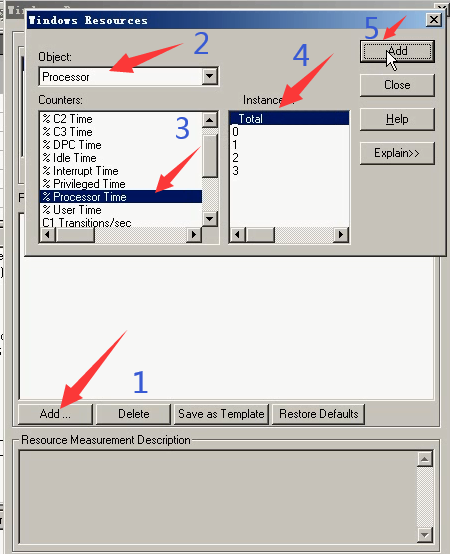
5)添加:%userTime:应用程序使用时间。点击close。
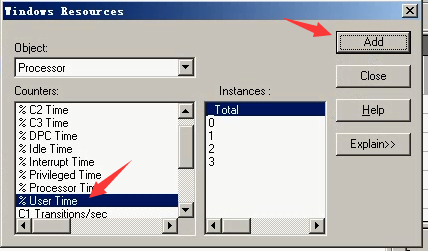
6)就可以看到这两个东西都进来了。
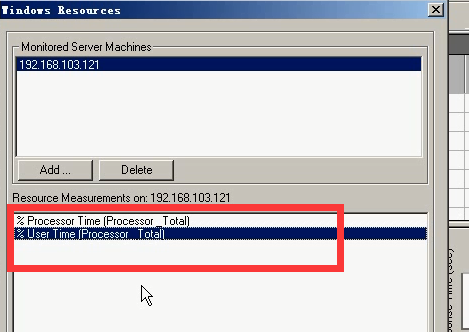
7)添加:%privlieged Time:windows自身使用cpu时间
点击Add------选择%privlieged Time-----点击Add
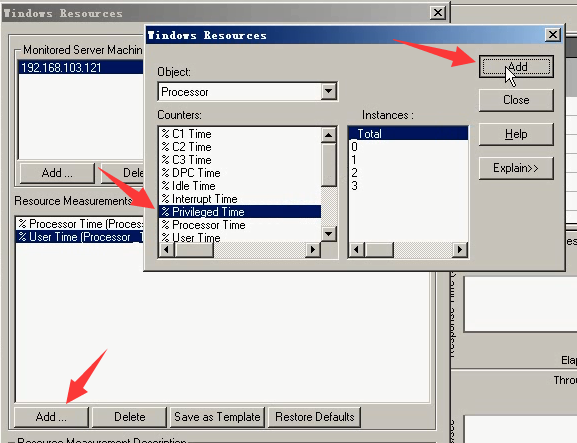
继续:
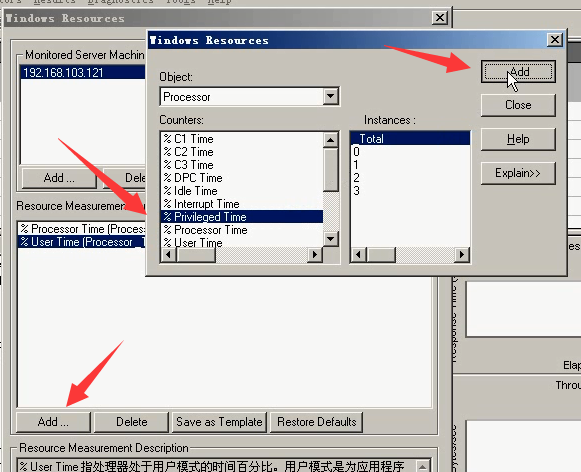
8)cpu队列长度:队列长度超过cpu个数+1,那就说明cpu不足,cpu消耗过高。
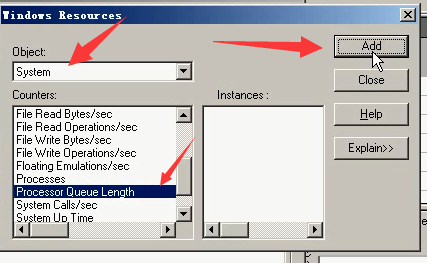
9)内存的使用情况,添加:内存-----可用内存

10)内存:page/sec

11)内存:page reads/sec:每秒从磁盘读取的数量。点击close。

12)加了几个关于cpu的和内存的。点击ok。

13)现在就能监控一些信息,在没有压的情况。这6张图表,是以后一定要有的。
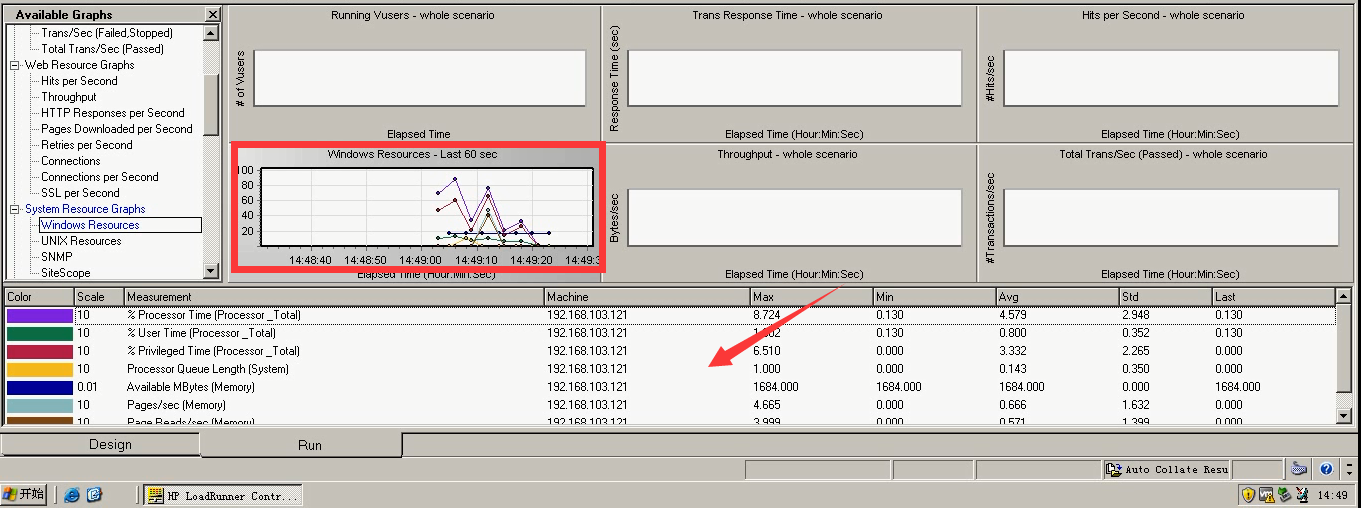
场景监控图:
- Running vusers
- TPS
- RT---响应时间
- hps
- throughput--->吞吐量(可以评估服务器处理能力、服务器的网络带宽)
系统资源图表:
- CPU
- 内存
- 磁盘
- 网络
6.负载测试模拟
iwebshop网站
例:6张图表已经添加进去,模拟一下监控负载。
1)点击,打开login脚本。
2)简单的模拟登陆操作,看一下地址为否要更新。
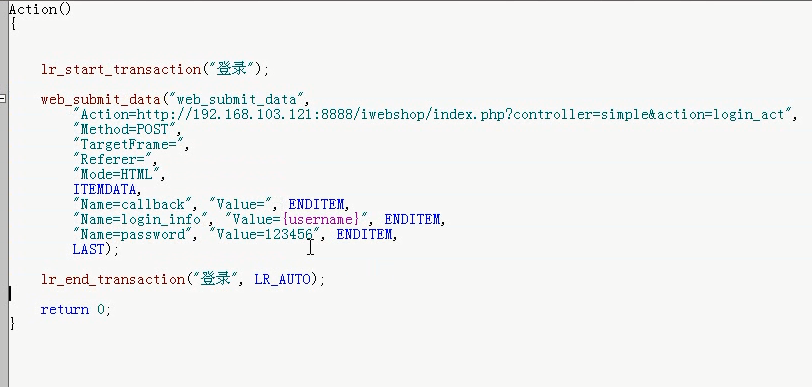
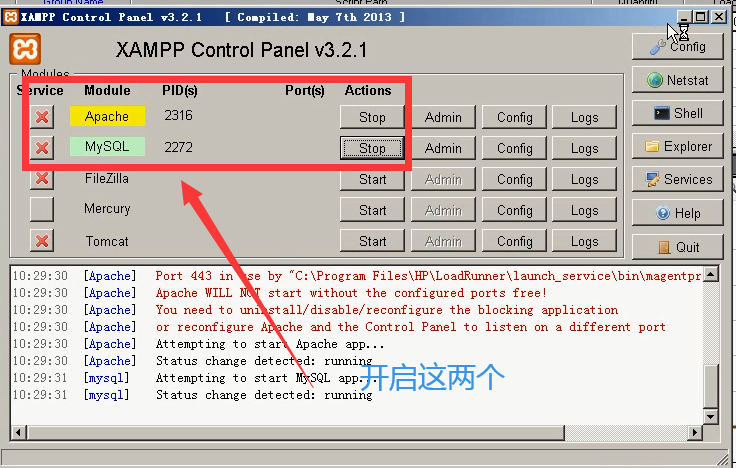
3)开启xampp。前两个开启,最小化。
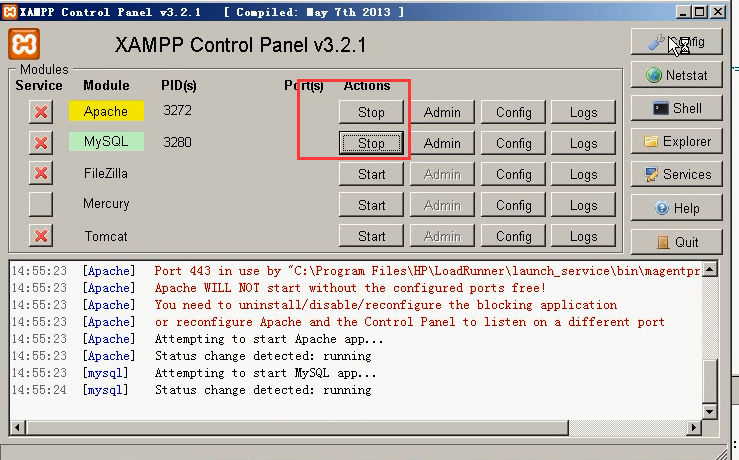
4)先把IP欺骗释放掉。点击Enable IP Spoofer。下面没有蓝色的图表就可以了。
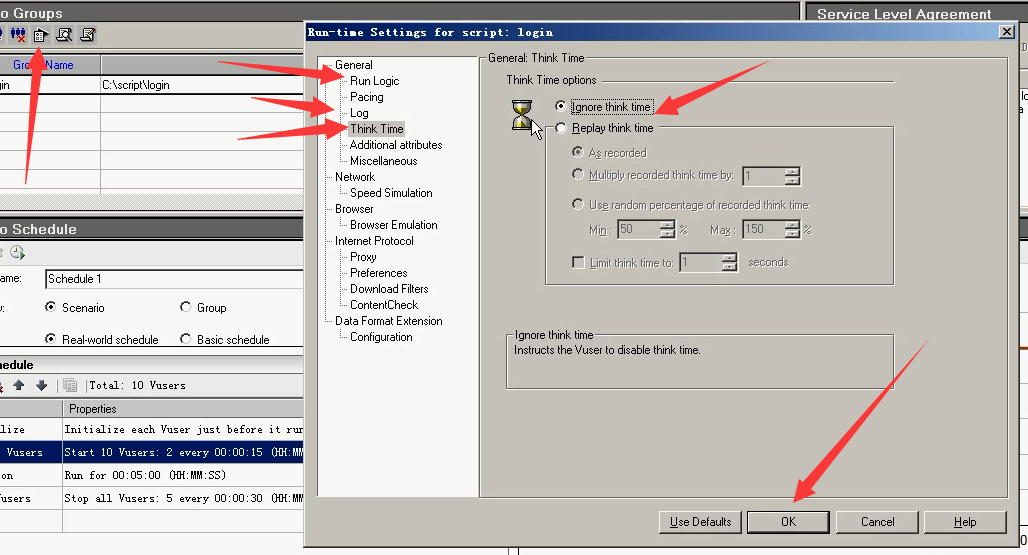
5)设置迭代次数为1次,因为是时间控制。设置关闭日志,(因为日志的开起,会对cpu或者内存都有一些消耗的情况)。设置忽略思考时间,(同样要关闭,不然也会消耗内存)。
6)设置弯成,点击运行。
虚拟用户数:5个
策略:Scenario+Basic schedule
一次性初始化,逐步增压,当加载完持续运行一段时间。同时停止所有用户。
7)有些目录存在了,直接点击是。覆盖掉。
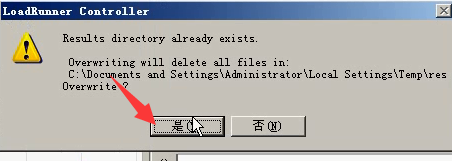
8)第一个拐点,并发用户量为2个,最佳并发用户数为60左右。
看Hits/Second:逐步增加,到了65以后,就开始平稳,然后下降。
吞吐表和每秒点击数表有点相似。
用户在2个的时候,响应时间开始上涨。吞吐,服务器的处理能力不再变化。就断定第一个拐点就在2个用户并发的时候。

9)想要看一下2个用户并发到底是什么情况。需要调整一下,点击stop,等一下。或者重启一下机器。
10)其他不变,只要修改用户数为2个
11)点击start Scenario,点击是。
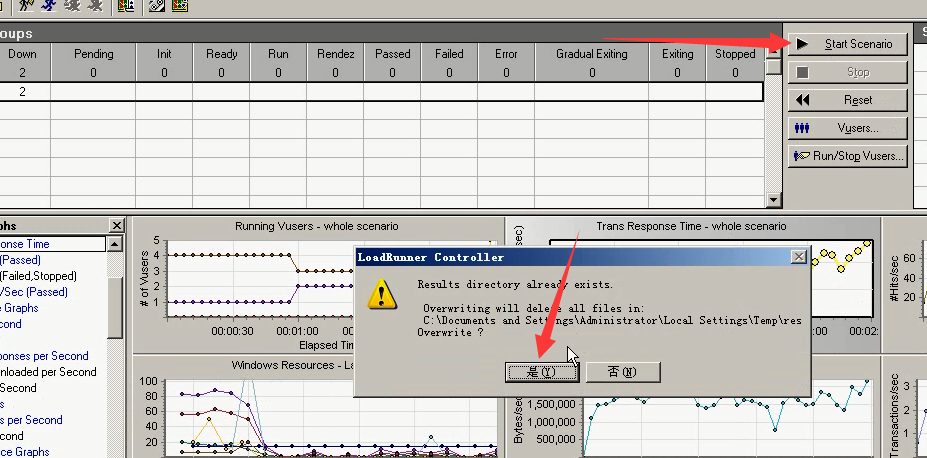
12)吞吐表
Avg/1024/1024=网络带宽。
这里的网络带宽不到1兆,说明网络带宽没有什么问题。
如果网络带宽,接近服务器的网络带宽,说明网络带宽有问题。如果远远小于就没问题。

13)响应时间,事物的平均响应时间为0.624秒。
如果实际的时候,我要求你在多少多少并发的时候,在2秒甚至3秒一下的话。就可以给它相应的用户,如果在,就表示能够满足这么多用户的并发的。
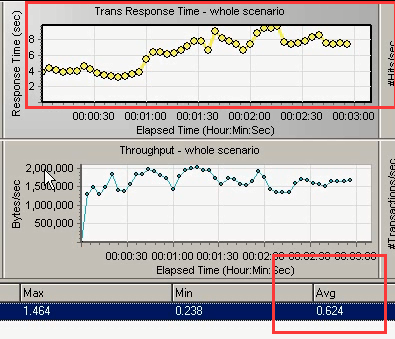
14)还可以看服务器的一些资源消耗。(内存支持2个用户的并发是可以的。)。可以stop停一下。这些加压数据都收集到了。
% Processor time:cpu的消耗为73%(没什么问题)
%userTime:应用程序使用时间为14%
%privlieged Time:windows自身使用cpu的消耗为54%
Processor Queue Length:cpu队列长度为1.2(cpu个数+1多一点点)
Available MBytes :可用内存为1492(正常情况下,会出现下降。因为现在是2个用户都已经达到了,所以变换不到。)
Pafes/sec:页交换频率为1.0(没有很大,可以把这些程序读取进来,执行它。)
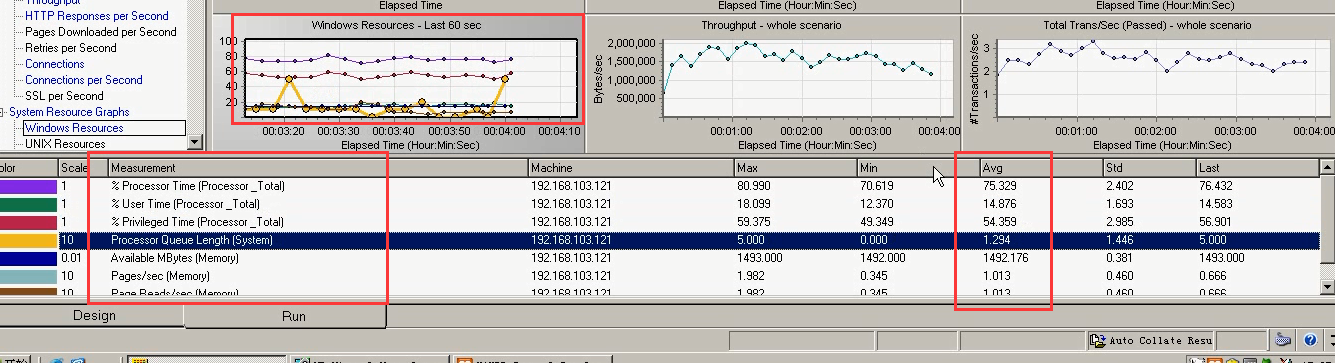
webtours网站1
1)打开之前的代码。
2)选择脚本,2个用户。

3)设置迭代次数为1次,因为是时间控制。设置关闭日志,(因为日志的开起,会对cpu或者内存都有一些消耗的情况)。设置忽略思考时间,(同样要关闭,不然也会消耗内存)。
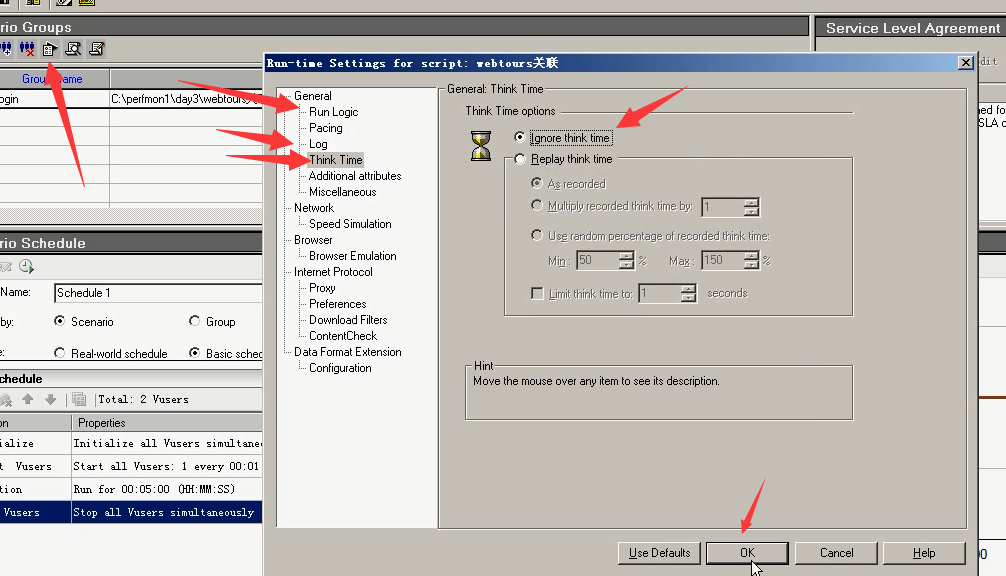
4)1分钟加载一个,持续运行5分钟。
5)把这个网站打开
6)打开脚本,ctrl+h,改一下IP。保存脚本--file save

7)刷新脚本

8)运行脚本,点击是。

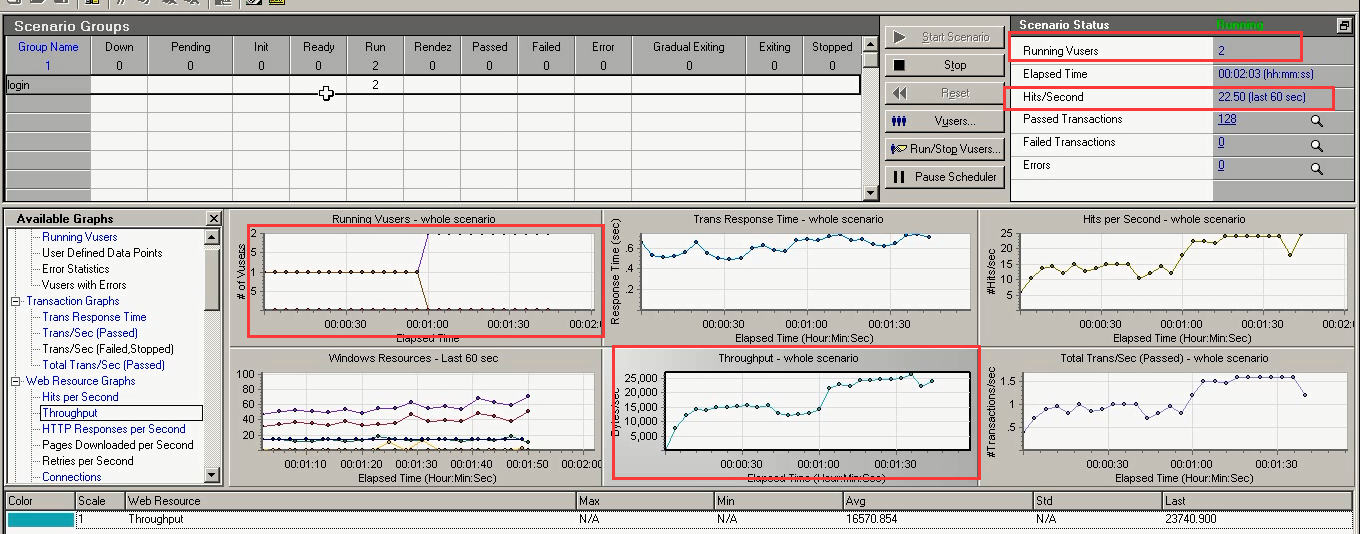
9)2个用户时,还在轻负载区。(看的是整体趋势,并不是某一个点。)
随着用户并发数的增加,吞吐量也在增加。
现在用户量为2个,已经全部增加完了。吞吐还是上升趋势。说明用户量为2个还没有达到最佳的用户数。
如果在重负载区,不到2个,吞吐有可能就不再变了。
10)继续调整,虚拟用户数为10个。如果在运行的过程中,吞吐平稳,那就达到了最佳用户数。

11)运行,观察。最佳并发数为3个。看完可以stop停下来。
当并发用户数为2个,吞吐和每秒点击数在增加。(说明还在轻负载区)

当用户数为3个,吞吐和每秒点击数在增加。响应时间也在增加。(最佳并发用户数)
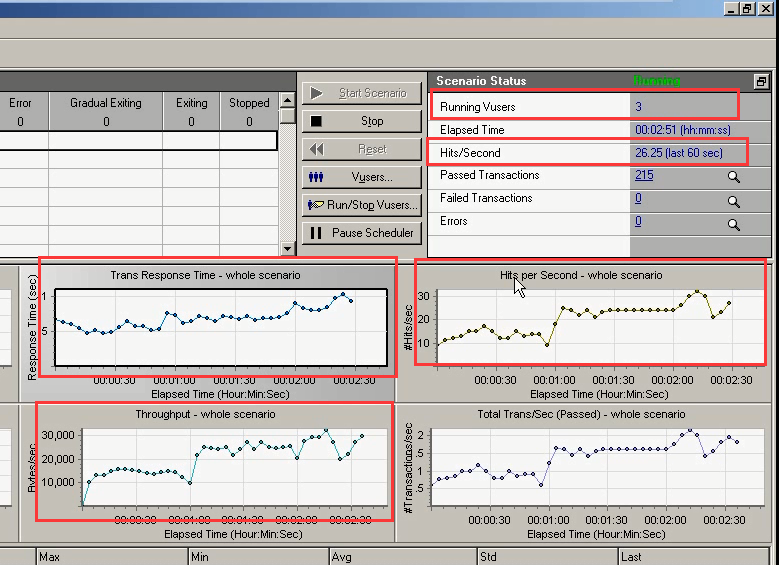
当用户数为4个,吞吐和每秒点击数在增加。响应时间也在增加。(每秒点击数恢复到平稳。)
当用户数为5个,吞吐和每秒点击数在急剧下降。响应时间在急剧增加。(崩溃区)

webtours网站2
50个用户,负载测试。
1)这是录的脚本,做了一下参数化。
2)开启服务器(如果前面开过了,就不用再开了)
3)点击运行,没什么问题。
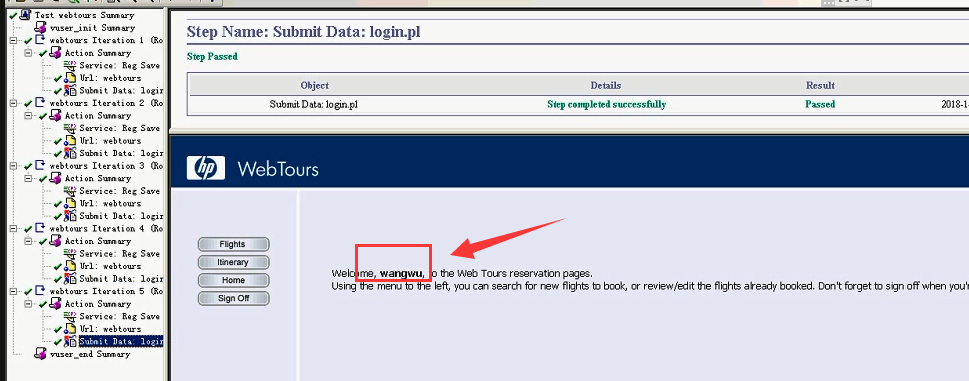
4)看一下结果:View----Test Results
5)几个登陆都没有问题。
6)打开Controller

7)加了50个用户
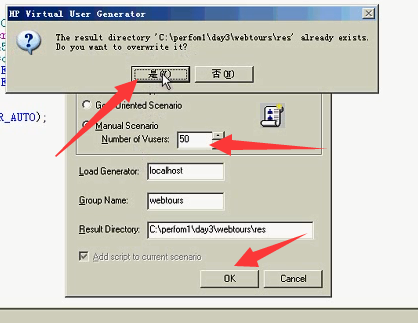
如果以后在公司,打开Controller。出现License报错:
说明:1.LoadRunner没有破解。2.或者破解错了。
如果没有破解,只能用VuGen,Controller是打不开的。
8)设置迭代次数为1次,设置关闭日志,设置忽略思考时间。

9)完成策略,点击运行。
策略:Scenario+Basic schedule
1分钟加载5个,持续运行5分钟。
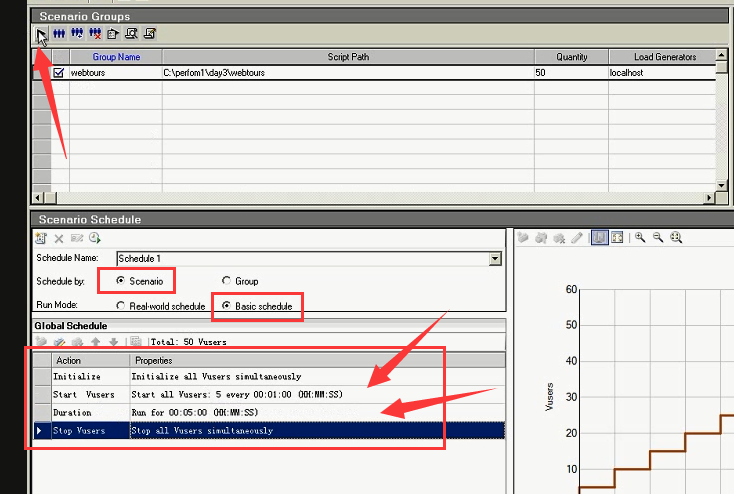
10)需要加载这6张图表。

11)观察
5个用户,每秒点击数为57。还在持续往上涨。

10个用户,每秒点击数为62。吞吐还在涨。(在轻负载区)

15个用户,每秒点击数为103。吞吐也还在涨。(最佳并发数在15个到20个之间。)
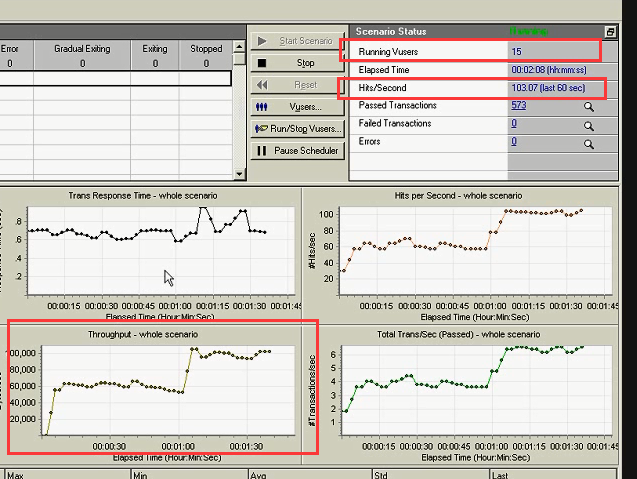
20个用户,每秒点击数为102。在重负载区。(和15个用户的点击数,差不多,说明服务器的处理能力就这么大。)
找到重负载区,可以做压力测试。


25个用户,每秒点击数为98。开始下降。有报错:参数关联找不到了。(在重负载区)

30个用户,每秒点击数和吞吐都在下降。也有报错:网络连接有问题(崩溃区)
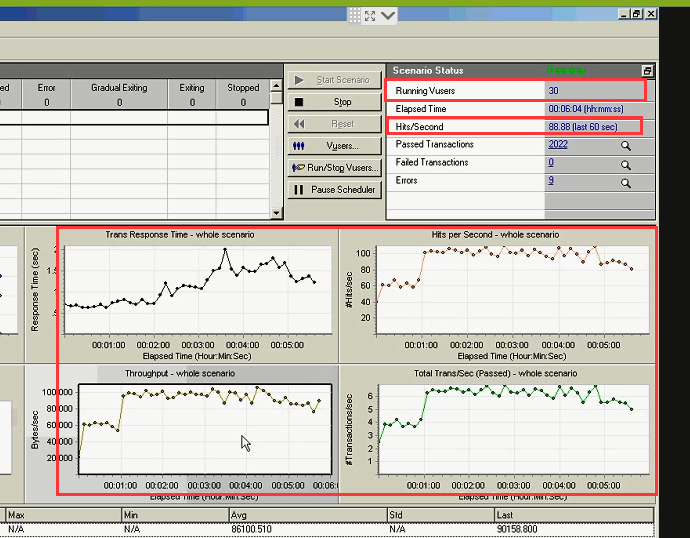
35个用户, 每秒点击数和吞吐都在下降。也有报错。(崩溃区)

可以看相应的日志目录:Results----Results Settings

可以看到每个用户的错误信息

随便点开一个看看:超时的找不到我们响应的信息。

也可以打开分析器
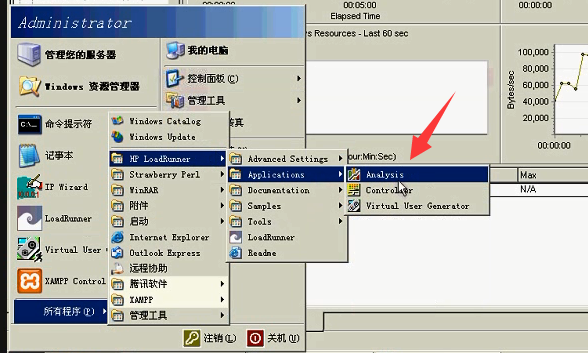
可以打开选择上面的路径,类型是LoadRunner results

可以看相应的数据,然后分析它的问题。

注意:最好在运行的时候,看一些数据的变化(取一些点,看这些点的变化)。也可以运行完,在分析器里看。
run user (运行用户数)和hits/s(并发数)、tps(每秒通过的事物数)三者的关系
1.run user 和hits/s
(一个用户在发送请求,可能不止一个,一个甚至更多个请求。)
run<hits/s:说明服务端、网络、客户端压力机都是正常的,压力机没有瓶颈
run>hits/s:(一个用户连一个请求都发不上了。)
开始时出现:说明用户数没有充分利用,检查压力机,网络,服务器。
测试中出现:是服务端的瓶颈
2.run增加,hits没有增加
有两个原因:
- 首先分析检查压力机
- 其次分析服务端有瓶颈
run user 增加hits下降,检查压力机的CPU内存(如果有问题,就扩大cpu核数,或扩大容量),或服务端的处理能力下降(看吞吐)
3.三者关系
- 压力机产生虚拟用户running vuser
- 虚拟用户运行脚本(请求函数)产生hits
- 服务器接收hits,处理成功后产生tps
RT和throughput
throughput(吞吐率)
- 说明服务端的处理能力
- 评估网络带宽有无瓶颈(计算,Avg/1024/1024和服务器的带宽比较。)
RT:响应时间
响应时间增大
- 网络带宽有瓶颈
- 网络带宽无瓶颈,说明服务端的处理能力下降(有可能是图片过大,设计不合理。服务器处理时间过长。)
四种用户
- 并发用户(并不是Running Vusers,那只是设置用户数。这里是跑的过程中看的。)
- 并发请求:hits/s
- 系统用户
- 在线用户:在线访问的用户
如果公司,要求看并发量。问清是并发用户,还是并发请求数(一般是这个)。
tps/hps
Tps:每秒钟事物数(多业务)
hps:每秒钟的http请求数
7.作业
要求:多用户同时登陆的时候性能情况(或则压力情况)或者多用户在退出的时候的性能情况。还加多用户同时打开网页。

1)代码
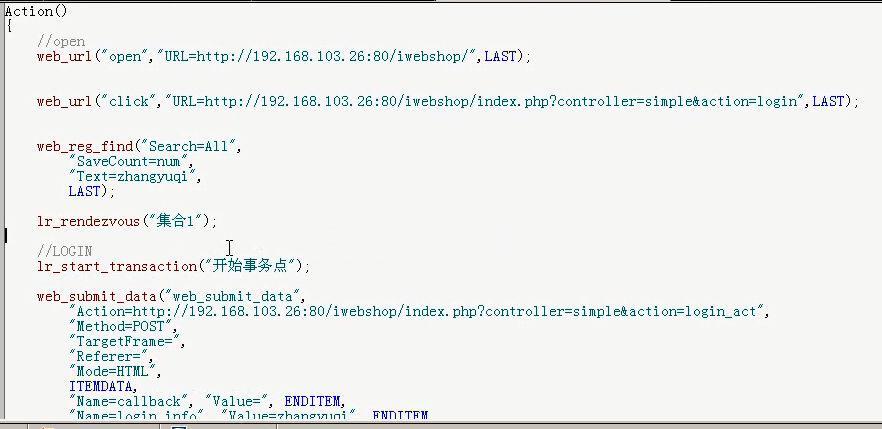
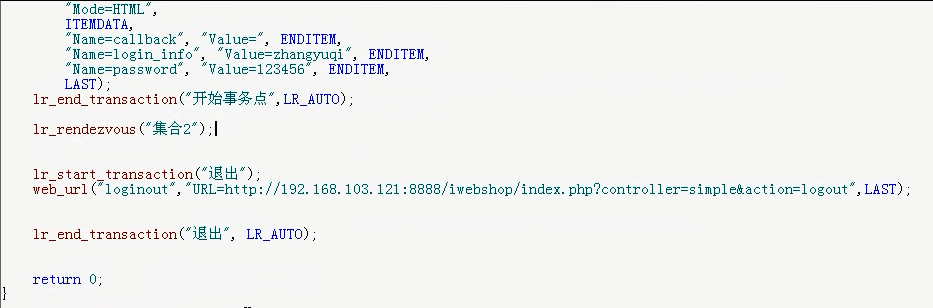
这里参数化掉

注释掉检查点函数。ctrl+h。把IP换一下。

2)设置迭代次数为:5次。Vuser-----RunTime Settins(为了保证在Controller没有问题。脚本多运行几遍。)

3)可以运行后,保存一下脚本:file ------save as
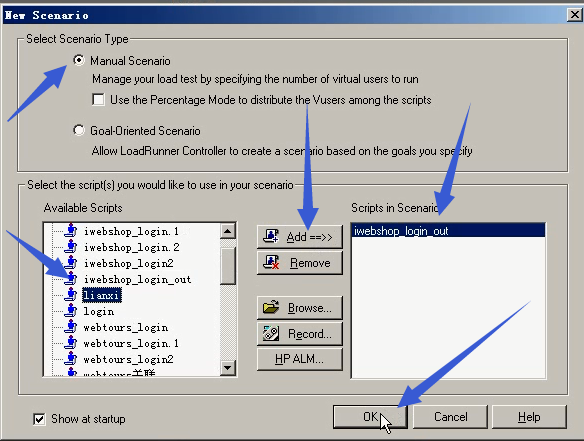
4)之前的Controller关掉。重新打开Controller:Tools----Create Controller Scenario

5)把脚本拿进来。
6)设置集合1的策略:Scenario------Rendezvous。集合2和集合1一样的,选中集合2,再设置1遍就行。
选择第一种策略:所有用户达到100%做集合。
不想让时间限制我,让它失去作用,就写大大的数字:90000s
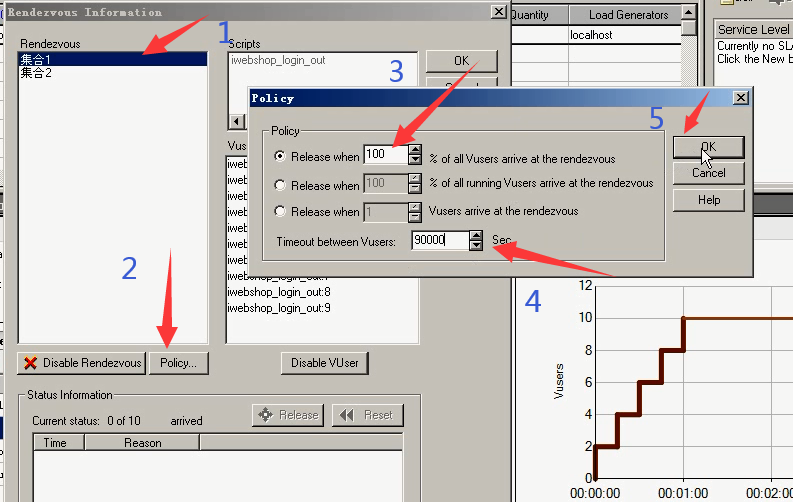
7)2个集合点都设置完成,就点击ok。集合点设置完毕。
要求:
在集合点1的时候,集合到所有设置的所有用户。然后同时操作。过完之后,要进行集合点2,集合点2的时候,10个用户同时操作。接下来要该Duration,Duration持续过程中,又要去集合,又要做下一步操作。

8)把思考时间和日志都关掉。
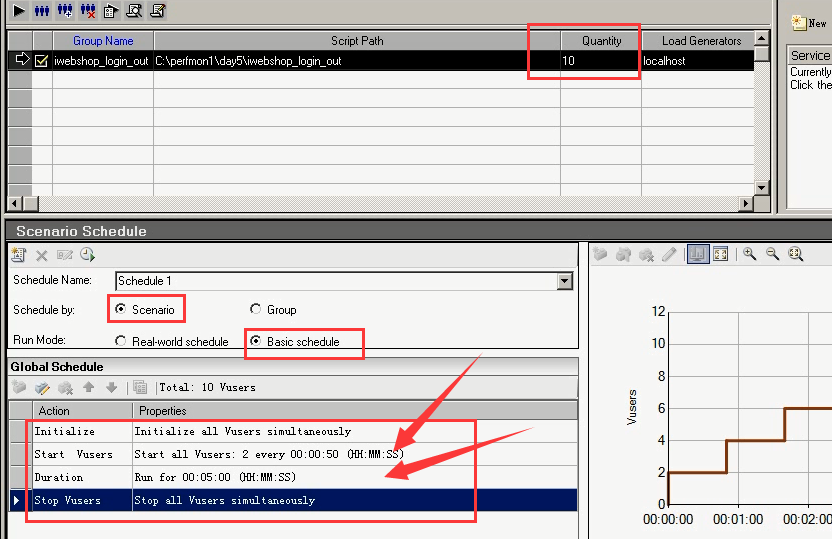
9)Scenario+Basic
每50秒加载两个用户
持续运行时间为5分钟
10)把6张图表拿进来。
11)把服务器资源拿过来。选中windows Resources ------右键------Add Measurements---点击Add-----IP----点击ok。
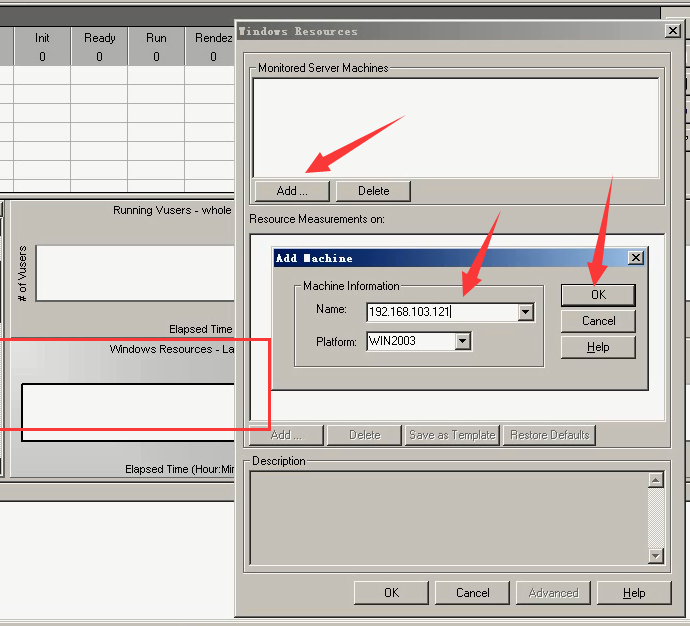
12)通过delete把之前的删除,通过Add点击添加以下5个。
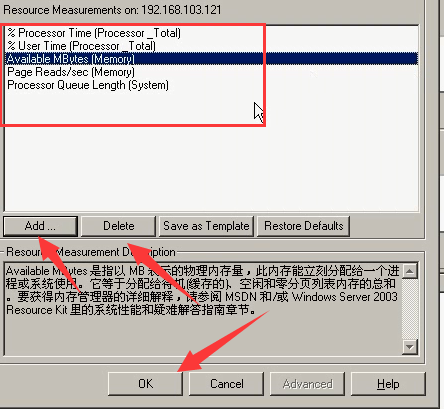
13)存放结果:Results------Results settings

14)压力机也是本机(这是默认的,不用改)。点击start scenario运行。
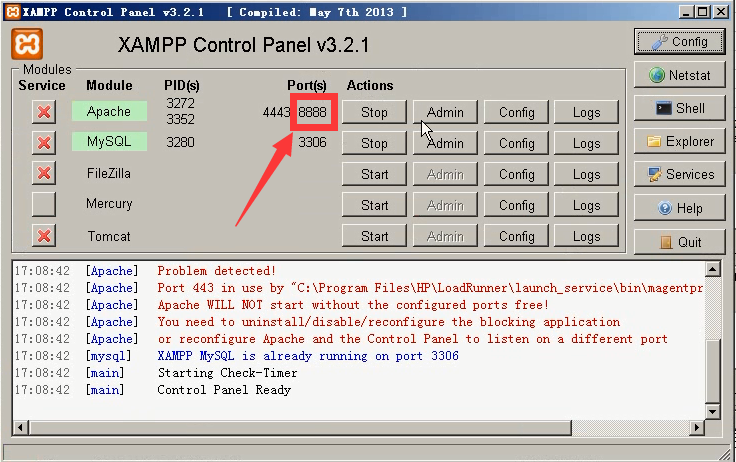
15)会报错,连不上。是端口出现问题。代码里的端口都改成8888
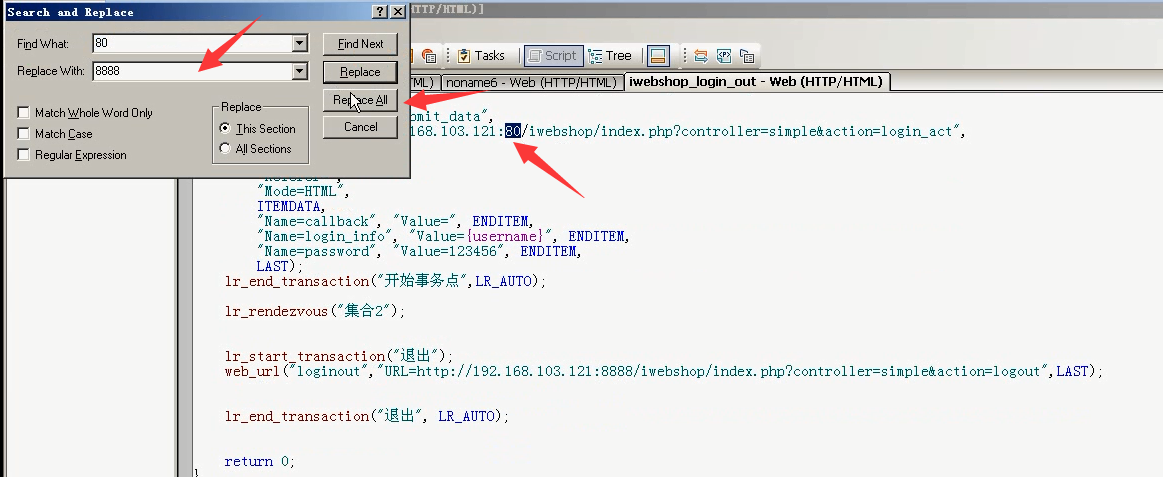
ctrl+h:把80都换成8888。保存以下脚本:file save
16)更新一下脚本。刷新完,点击ok。
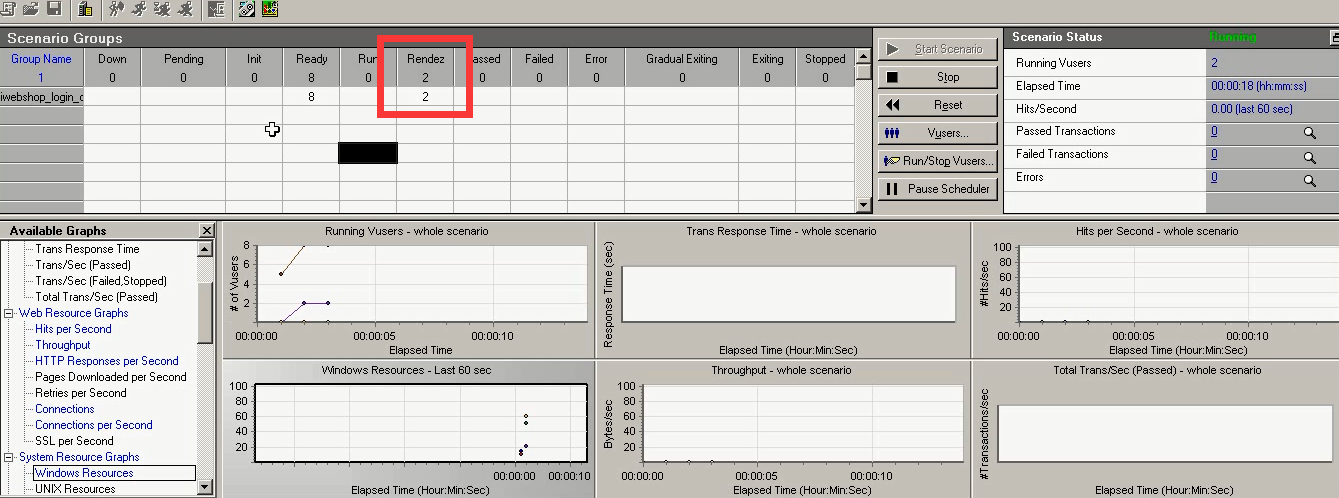
17)点击运行,观察。
Rendez 2:开始进行集合。集合数为:2
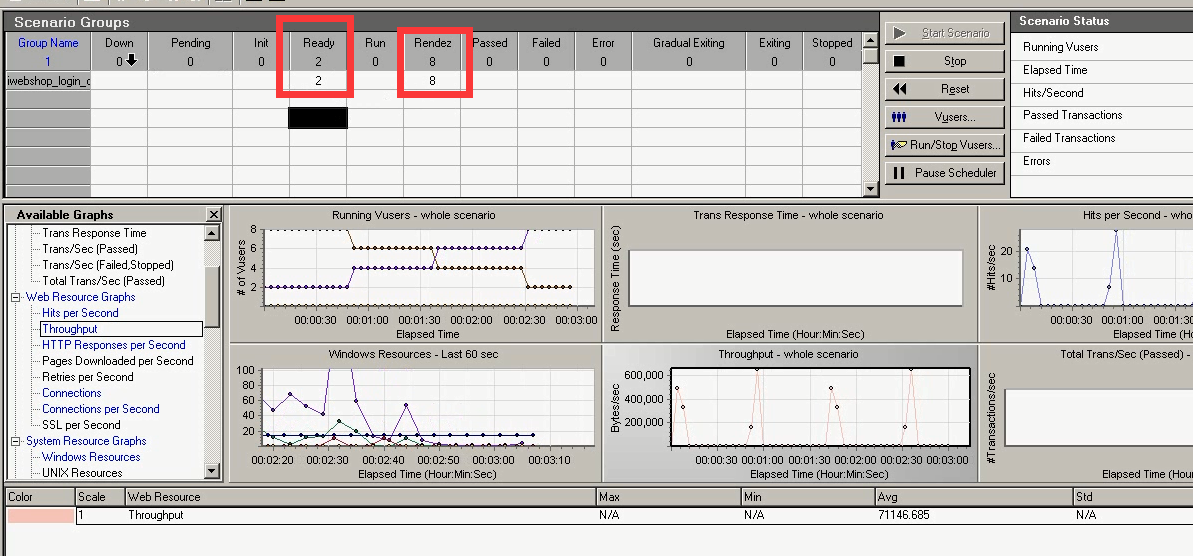
Rendez 4:集合数为4,不会产生响应时间。但是会有吞吐,打开网页。

Rendez 6:集合数为6。可用内存为1389,之前是1390。在下降。

Rendez 8:集合数为8,ready:2。第十个用户也马上进来了。
Run 10:发生了一次性集合。(有事物的响应时间了。)
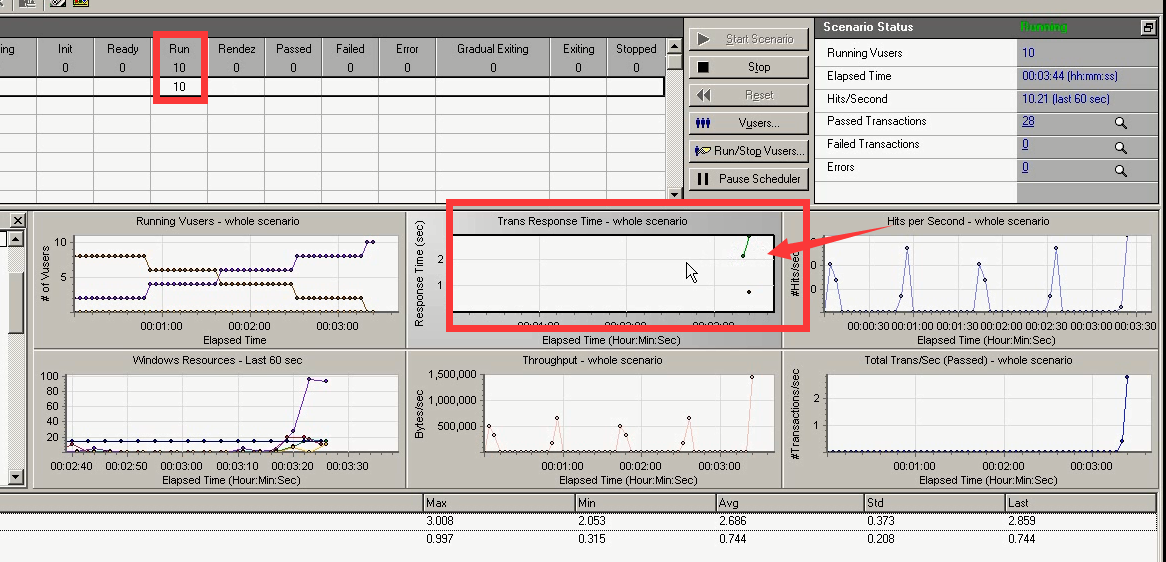
Run 10:第二次集合
吞吐一次性就上去了,很正常。多个用户进行登陆或者退出操作去了。

10个用户不断在执行事物,吞吐再增长。说明往上压,对服务器的影响不是很大,还可以调整用户量。
之后来回做集合的操作。也可以一直压,压完直接去结果里面看,然后分析也是可以的。
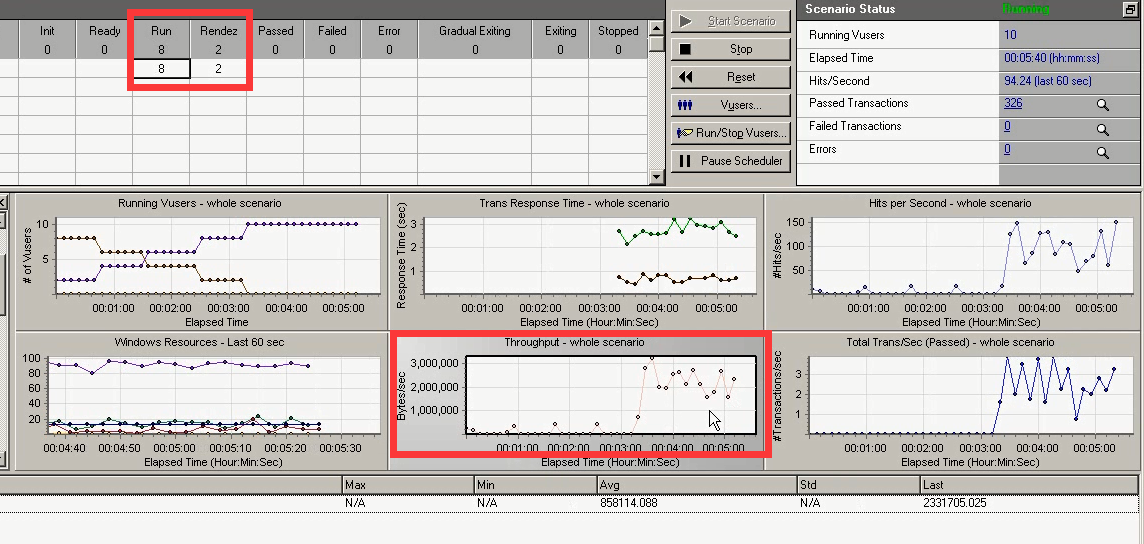
对于多业务而言,也是一样的。只需要设置集合点。就能在点上进行操作。可以达到某一定的用户量进行操作(可以看到加载到10个用户过程中,随着用户的变化,吞吐的变化。)比如设置:50%用户,为5个用户。
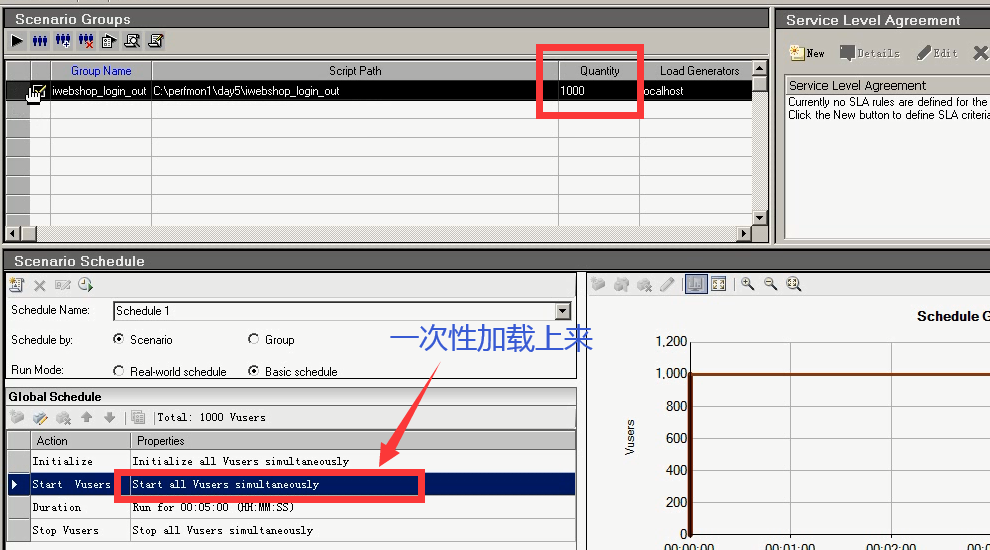
例:单业务:压一下页面。1000个并发达到是多少?
直接一次性加载上来。就可以。
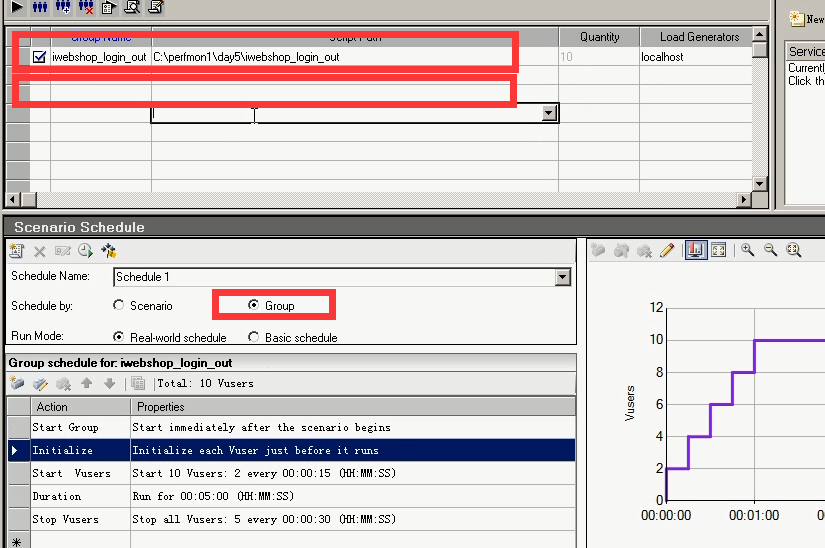
一个功能,一个脚本。一个功能,一个脚本。按照组的模式来,等上一个功能完了,再进行下一个功能。也是可以的。上面我们的是多个功能放在一个脚本里 的。
关于Controller这块,我们主要是为了去压数据。找它的一些点。然后在它的点上,进行修改数据。继续压,然后看它的一些情况。
IP欺骗是针对局域网的,在公网上,做了IP欺骗也没有用,显示的是同一个IP。IP欺骗不用了,要即时的关闭。