27 Apr 18
一、全局解释器锁 (GIL)
运行test.py的流程:
a、将python解释器的代码从硬盘读入内存
b、将test.py的代码从硬盘读入内存 (一个进程内装有两份代码)
c、将test.py中的代码像字符串一样读入python解释器中解析执行
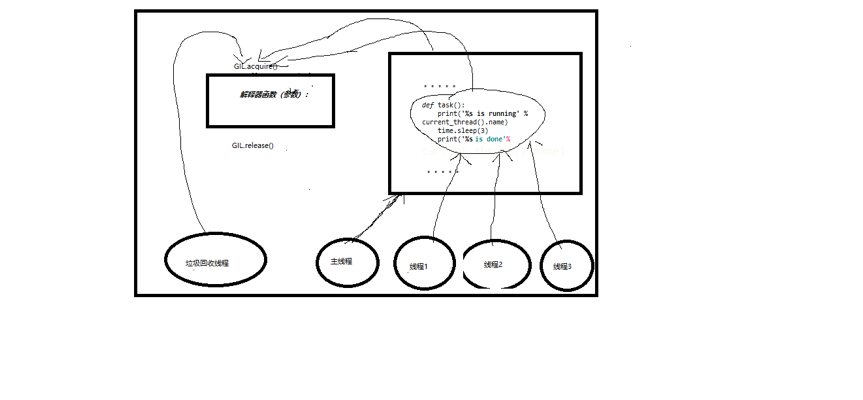
1 、GIL:全局解释器锁 (CPython解释器的特性)
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management (垃圾回收机制,由解释器定期执行)is not thread-safe(如果不是串行改数据,当x=10的过程中内存中产生一个10,还没来的及绑定x,就有可能被垃圾回收机制回收).However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
GIL本质就是一把夹在解释器身上的互斥锁(执行权限)。同一个进程内的所有线程都需要先抢到GIL锁,才能执行解释器代码
2、GIL的优缺点:
优点:保证Cpython解释器内存管理的线程安全
缺点:在Cpython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,也就说Cpython解释器的多线程无法实现并行无法利用多核优势
注意:
a、GIL不能并行,但有可能并发,不一定为串行。因为串行是一个任务完完全全执行完毕后才进行下一个;而cpython中,一个线程在io时,被CPU释放时,会被强行取消GIL的使用权限
b、多核(多CPU)的优势是提升运算效率
c、计算密集型--》使用多进程,以用上多核
d、IO密集型--》使用多线程
二、Cpython解释器并发效率验证
1、计算密集型应该使用多进程
from multiprocessing import Process
from threading import Thread
import time
# import os
# print(os.cpu_count()) #查看cpu个数
def task1():
res=0
for i in range(1,100000000):
res+=i
def task2():
res=0
for i in range(1,100000000):
res+=i
def task3():
res=0
for i in range(1,100000000):
res+=i
def task4():
res=0
for i in range(1,100000000):
res+=i
if __name__ == '__main__':
# p1=Process(target=task1)
# p2=Process(target=task2)
# p3=Process(target=task3)
# p4=Process(target=task4)
p1=Thread(target=task1)
p2=Thread(target=task2)
p3=Thread(target=task3)
p4=Thread(target=task4)
start_time=time.time()
p1.start()
p2.start()
p3.start()
p4.start()
p1.join()
p2.join()
p3.join()
p4.join()
stop_time=time.time()
print(stop_time - start_time)
2、IO密集型应该使用多线程
from multiprocessing import Process
from threading import Thread
import time
def task1():
time.sleep(3)
def task2():
time.sleep(3)
def task3():
time.sleep(3)
def task4():
time.sleep(3)
if __name__ == '__main__':
# p1=Process(target=task1)
# p2=Process(target=task2)
# p3=Process(target=task3)
# p4=Process(target=task4)
# p1=Thread(target=task1)
# p2=Thread(target=task2)
# p3=Thread(target=task3)
# p4=Thread(target=task4)
# start_time=time.time()
# p1.start()
# p2.start()
# p3.start()
# p4.start()
# p1.join()
# p2.join()
# p3.join()
# p4.join()
# stop_time=time.time()
# print(stop_time - start_time) #3.138049364089966
p_l=[]
start_time=time.time()
for i in range(500):
p=Thread(target=task1)
p_l.append(p)
p.start()
for p in p_l:
p.join()
print(time.time() - start_time)
三、线程互斥锁与GIL对比
GIL能保护解释器级别代码(和垃圾回收机制有关)但保护不了其他共享数据(比如自己的代码)。所以在程序中对于需要保护的数据要自行加锁
from threading import Thread,Lock
import time
mutex=Lock()
count=0
def task():
global count
mutex.acquire()
temp=count
time.sleep(0.1)
count=temp+1
mutex.release()
if __name__ == '__main__':
t_l=[]
for i in range(2):
t=Thread(target=task)
t_l.append(t)
t.start()
for t in t_l:
t.join()
print('主',count)
四、基于多线程实现并发的套接字通信
服务端:
from socket import *
from threading import Thread
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
tpool=ThreadPoolExecutor(3) #进程和线程都不能无限多,导入模块来限制进程和线程池重点数目;进程线程池中封装了Process、Thread模块的功能
def communicate(conn,client_addr):
while True: # 通讯循环
try:
data = conn.recv(1024)
if not data: break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
def server():
server=socket(AF_INET,SOCK_STREAM)
server.bind(('127.0.0.1',8080))
server.listen(5)
while True: # 链接循环
conn,client_addr=server.accept()
print(client_addr)
# t=Thread(target=communicate,args=(conn,client_addr))
# t.start()
tpool.submit(communicate,conn,client_addr)
server.close()
if __name__ == '__main__':
server()
客户端:
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg=input('>>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data=client.recv(1024)
print(data.decode('utf-8'))
client.close()
五、进程池与线程池
为什么要用“池”:池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务
池子内什么时候装进程:并发的任务属于计算密集型
池子内什么时候装线程:并发的任务属于IO密集型
1、进程池
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time,os,random
def task(x):
print('%s 接客' %os.getpid())
time.sleep(random.randint(2,5))
return x**2
if __name__ == '__main__':
p=ProcessPoolExecutor() # 默认开启的进程数是cpu的核数
# alex,武佩奇,杨里,吴晨芋,张三
for i in range(20):
p.submit(task,i)
2、线程池
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time,os,random
def task(x):
print('%s 接客' %x)
time.sleep(random.randint(2,5))
return x**2
if __name__ == '__main__':
p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5
# alex,武佩奇,杨里,吴晨芋,张三
for i in range(20):
p.submit(task,i)
六、同步、异步、阻塞、非阻塞
1、阻塞与非阻塞指的是程序的两种运行状态
阻塞:遇到IO就发生阻塞,程序一旦遇到阻塞操作就会停在原地,并且立刻释放CPU资源
非阻塞(就绪态或运行态):没有遇到IO操作,或者通过某种手段让程序即便是遇到IO操作也不会停在原地,执行其他操作,力求尽可能多的占有CPU
2、同步与异步指的是提交任务的两种方式:
同步调用:提交完任务后,就在原地等待,直到任务运行完毕后,拿到任务的返回值,才继续执行下一行代码
异步调用:提交完任务后,不在原地等待,直接执行下一行代码。等全部执行完毕后取出结果
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor
import time,os,random
def task(x):
print('%s 接客' %x)
time.sleep(random.randint(1,3))
return x**2
if __name__ == '__main__':
# 异步调用
p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5
# alex,武佩奇,杨里,吴晨芋,张三
obj_l=[]
for i in range(10):
obj=p.submit(task,i)
obj_l.append(obj)
# p.close()
# p.join()
p.shutdown(wait=True) (等同于p.close()(不允许向池中放新任务) + p.join())
print(obj_l[3].result())
print('主')
# 同步调用
p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5
# alex,武佩奇,杨里,吴晨芋,张三
for i in range(10):
res=p.submit(task,i).result()
print('主')