Redis 教程

Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。
REmote DIctionary Server(Redis) 是一个由Salvatore Sanfilippo写的key-value存储系统。
Redis是一个开源的使用ANSI C语言编写、遵守BSD协议、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
它通常被称为数据结构服务器,因为值(value)可以是 字符串(String), 哈希(Map), 列表(list), 集合(sets) 和 有序集合(sorted sets)等类型。
Redis教程:http://www.redis.net.cn/tutorial/3501.html
Redis命令:
http://www.redis.net.cn/order/
http://doc.redisfans.com/
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作全并后的原子性执行。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,应为数据量不能大于硬件内存。在内存数据库方面的另一个优点是, 相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。 同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
您可以对这些类型进行原子操作,如附加到字符串;递增哈希值;列表进栈;计算交集,差集和并集;在有序集合中获取最大值。
为了实现卓越的性能,Redis的数据存储在内存中。你可以不定期导出数据到磁盘,或把操作追加到日志。
Redis主从复制,首次采用快速的非阻塞同步,网络中断等异常时会自动重连。
其他特性有事务,Pub/Sub, Lua脚本,keys生存期,配置Redis为cache。
Redis用ANSI C书写,可以无外部依赖地在和多数POSIX系统的,如Linux, * BSD ,Mac OS X运行。测试和开发多基于Linux和OSX,建议使用Linux。不支持windows。
数据模型
Redis的外层由键、值映射的字典构成。与其他非关系型数据库主要不同在于:Redis中值的类型不仅限于字符串,还支持如下抽象数据类型:
- 字符串列表
- 无序不重复的字符串集合
- 有序不重复的字符串集合
- 键、值都为字符串的哈希表
值的类型决定了值本身支持的操作。Redis支持高层的服务器原子操作,比如交集、并集、差集。
持久化
Redis的通常内存中的保存整个数据集。2.4以上版本可配置使用他们虚拟内存但是很快不推荐使用。目前通过两种方式实现持久化:
- 快照:一种半持久模式。不时把数据集以异步方式从内存以RDB格式写入硬盘。
- 1.1版本开始使用更安全的AOF格式替代,一种只能追加的日志类型。当内存中数据集修改时产生该日志。Redis能在后台重修可追加的记录作修改来避免无限增长的日志。
默认情况下,Redis的每2秒同步数据到磁盘,如果整个系统异常也知会丢失几秒的数据。
同步
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可作为其他从服务器的主服务器。这使得Redis可执行单层树复制。从盘可以有意无意的数据不一致。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树根。复制用于读(非写)扩展和数据冗余。
性能
当数据不需要持久化时,Redis基于内存,写与读操作速度没有明显差别。Redis以单一的过程和单线程执行,单个的Redis实例不能执行存储过程之类的并发操作。
集群
Redis的项目有一个集群规范,但集群功能目前处于测试阶段。据Redis的创造者圣菲利波,Redis的集群的第一个测试版计划在在2013年年底,将支持key空间自动分区和热模式碎片重整,但只支持单key操作。将来Redis集群会支持多达1000个节点,支持心跳的容错和故障检测,增量版本控制以防止冲突,slave选举和推荐为master,并所有群集节点之间的发布和订阅。
Linux 下安装
下载地址:http://www.redis.net.cn/download/,下载最新文档版本。
本教程使用的最新文档版本为 2.8.17,下载并安装:
- $ wget http://download.redis.io/releases/redis-2.8.17.tar.gz
- $ tar xzf redis-2.8.17.tar.gz
- $ cd redis-2.8.17
- $ make
make完后 redis-2.8.17目录下会出现编译后的redis服务程序redis-server,还有用于测试的客户端程序redis-cli
下面启动redis服务.
- $ ./redis-server
注意这种方式启动redis 使用的是默认配置。也可以通过启动参数告诉redis使用指定配置文件使用下面命令启动。
- $ ./redis-server redis.conf
redis.conf是一个默认的配置文件。我们可以根据需要使用自己的配置文件。
启动redis服务进程后,就可以使用测试客户端程序redis-cli和redis服务交互了。 比如:
- $ ./redis-cli
- redis> set foo bar
- OK
- redis> get foo
- "bar"
Ubuntu 下安装
在 Ubuntu 系统安装 Redi 可以使用以下命令:
- $sudo apt-get update
- $sudo apt-get install redis-server
启动 Redis
- $redis-server
查看 redis 是否启动?
- $redis-cli
以上命令将打开以下终端:
- redis 127.0.0.1:6379>
127.0.0.1 是本机 IP ,6379 是 redis 服务端口。现在我们输入 PING 命令。
- redis 127.0.0.1:6379> ping
- PONG
以上说明我们已经成功安装了redis。
Redis 的配置文件位于 Redis 安装目录下,文件名为 redis.conf。
你可以通过 CONFIG 命令查看或设置配置项。
语法
Redis CONFIG 命令格式如下:
- redis 127.0.0.1:6379> CONFIG GET CONFIG_SETTING_NAME
实例
- redis 127.0.0.1:6379> CONFIG GET loglevel
- 1) "loglevel"
- 2) "notice"
使用 * 号获取所有配置项:
Redis 数据类型
一、Redis安装和基本使用
|
1
2
3
4
|
wget http://download.redis.io/releases/redis-3.0.6.tar.gztar xzf redis-3.0.6.tar.gzcd redis-3.0.6make |
启动服务端
|
1
|
src/redis-server |
启动客户端
|
1
2
3
4
5
|
src/redis-cliredis> set foo barOKredis> get foo"bar" |
二、Python操作Redis
|
1
2
3
4
5
6
7
|
sudo pip install redisorsudo easy_install redisor源码安装详见:https://github.com/WoLpH/redis-py |
API使用
redis-py 的API的使用可以分类为:
- 连接方式
- 连接池
- 操作
- String 操作
- Hash 操作
- List 操作
- Set 操作
- Sort Set 操作
- 管道
- 发布订阅
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)。
String(字符串)
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
#在Redis中设置值,默认不存在则创建,存在则修改
r.set('name', 'zhangsan')
'''参数:
set(name, value, ex=None, px=None, nx=False, xx=False)
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行,同setnx(name, value)
xx,如果设置为True,则只有name存在时,当前set操作才执行'''
setex(name, value, time)
#设置过期时间(秒)
psetex(name, time_ms, value)
#设置过期时间(豪秒)
string类型是Redis最基本的数据类型,一个键最大能存储512MB。
实例
- redis 127.0.0.1:6379> SET name "redis.net.cn"
- OK
- redis 127.0.0.1:6379> GET name
- "redis.net.cn"
在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 name,对应的值为redis.net.cn。
注意:一个键最大能存储512MB。
mset()
#批量设置值 r.mset(name1='zhangsan', name2='lisi') #或 r.mget({"name1":'zhangsan', "name2":'lisi'})
get(name)
获取值
mget(keys, *args)
#批量获取 print(r.mget("name1","name2")) #或 li=["name1","name2"] print(r.mget(li))
getset(name, value)
#设置新值,打印原值 print(r.getset("name1","wangwu")) #输出:zhangsan print(r.get("name1")) #输出:wangwu
getrange(key, start, end)
#根据字节获取子序列 r.set("name","zhangsan") print(r.getrange("name",0,3))#输出:zhan
setrange(name, offset, value)
#修改字符串内容,从指定字符串索引开始向后替换,如果新值太长时,则向后添加 r.set("name","zhangsan") r.setrange("name",1,"z") print(r.get("name")) #输出:zzangsan r.setrange("name",6,"zzzzzzz") print(r.get("name")) #输出:zzangszzzzzzz
setbit(name, offset, value)

#对二进制表示位进行操作 ''' name:redis的name offset,位的索引(将值对应的ASCII码变换成二进制后再进行索引) value,值只能是 1 或 0 ''' str="345" r.set("name",str) for i in str: print(i,ord(i),bin(ord(i)))#输出 值、ASCII码中对应的值、对应值转换的二进制 ''' 输出: 3 51 0b110011 4 52 0b110100 5 53 0b110101''' r.setbit("name",6,0)#把第7位改为0,也就是3对应的变成了0b110001 print(r.get("name"))#输出:145
getbit(name, offset)
#获取name对应值的二进制中某位的值(0或1) r.set("name","3") # 对应的二进制0b110011 print(r.getbit("name",5)) #输出:0 print(r.getbit("name",6)) #输出:1
bitcount(key, start=None, end=None)
#获取对应二进制中1的个数 r.set("name","345")#0b110011 0b110100 0b110101 print(r.bitcount("name",start=0,end=1)) #输出:7 ''' key:Redis的name start:字节起始位置 end:字节结束位置'''
strlen(name)
#返回name对应值的字节长度(一个汉字3个字节) r.set("name","zhangsan") print(r.strlen("name")) #输出:8
incr(self, name, amount=1)
#自增mount对应的值,当mount不存在时,则创建mount=amount,否则,则自增,amount为自增数(整数) print(r.incr("mount",amount=2))#输出:2 print(r.incr("mount"))#输出:3 print(r.incr("mount",amount=3))#输出:6 print(r.incr("mount",amount=6))#输出:12 print(r.get("mount")) #输出:12
incrbyfloat(self, name, amount=1.0)
#类似 incr() 自增,amount为自增数(浮点数)
decr(self, name, amount=1)
#自减name对应的值,当name不存在时,则创建name=amount,否则,则自减,amount为自增数(整数)
append(name, value)
#在name对应的值后面追加内容 r.set("name","zhangsan") print(r.get("name")) #输出:'zhangsan r.append("name","lisi") print(r.get("name")) #输出:zhangsanlisi
Hash(哈希)
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
实例
- redis 127.0.0.1:6379> HMSET user:1 username redis.net.cn password redis.net.cn points 200
- OK
- redis 127.0.0.1:6379> HGETALL user:1
- 1) "username"
- 2) "redis.net.cn"
- 3) "password"
- 4) "redis.net.cn"
- 5) "points"
- 6) "200"
- redis 127.0.0.1:6379>
以上实例中 hash 数据类型存储了包含用户脚本信息的用户对象。 实例中我们使用了 Redis HMSET, HEGTALL 命令,user:1 为键值。
每个 hash 可以存储 232 - 1 键值对(40多亿)。
redis中的Hash 在内存中类似于一个name对应一个dic来存储
hset(name, key, value)
#name对应的hash中设置一个键值对(不存在,则创建,否则,修改) r.hset("dic_name","a1","aa")
hget(name,key)
r.hset("dic_name","a1","aa") #在name对应的hash中根据key获取value print(r.hget("dic_name","a1"))#输出:aa
hgetall(name)
#获取name对应hash的所有键值 print(r.hgetall("dic_name"))
hmset(name, mapping)
#在name对应的hash中批量设置键值对,mapping:字典 dic={"a1":"aa","b1":"bb"} r.hmset("dic_name",dic) print(r.hget("dic_name","b1"))#输出:bb
hmget(name, keys, *args)
# 在name对应的hash中获取多个key的值 li=["a1","b1"] print(r.hmget("dic_name",li)) print(r.hmget("dic_name","a1","b1"))
hlen(name)、hkeys(name)、hvals(name)
dic={"a1":"aa","b1":"bb"}
r.hmset("dic_name",dic)
#hlen(name) 获取hash中键值对的个数
print(r.hlen("dic_name"))
#hkeys(name) 获取hash中所有的key的值
print(r.hkeys("dic_name"))
#hvals(name) 获取hash中所有的value的值
print(r.hvals("dic_name"))
hexists(name, key)
#检查name对应的hash是否存在当前传入的key print(r.hexists("dic_name","a1"))#输出:True
hdel(name,*keys)
#删除指定name对应的key所在的键值对 r.hdel("dic_name","a1")
hincrby(name, key, amount=1)
#自增hash中key对应的值,不存在则创建key=amount(amount为整数) print(r.hincrby("demo","a",amount=2))
hincrbyfloat(name, key, amount=1.0)
#自增hash中key对应的值,不存在则创建key=amount(amount为浮点数)
hscan(name, cursor=0, match=None, count=None)
hscan_iter(name, match=None, count=None)
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素导列表的头部(左边)或者尾部(右边)。
实例
- redis 127.0.0.1:6379> lpush redis.net.cn redis
- (integer) 1
- redis 127.0.0.1:6379> lpush redis.net.cn mongodb
- (integer) 2
- redis 127.0.0.1:6379> lpush redis.net.cn rabitmq
- (integer) 3
- redis 127.0.0.1:6379> lrange redis.net.cn 0 10
- 1) "rabitmq"
- 2) "mongodb"
- 3) "redis"
- redis 127.0.0.1:6379>
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
edis中的List在在内存中按照一个name对应一个List来存储
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 r.lpush("list_name",2) r.lpush("list_name",3,4,5)#保存在列表中的顺序为5,4,3,2
rpush(name,values)
#同lpush,但每个新的元素都添加到列表的最右边
lpushx(name,value)
#在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
rpushx(name,value)
#在name对应的list中添加元素,只有name已经存在时,值添加到列表的最右边
llen(name)
# name对应的list元素的个数 print(r.llen("list_name"))
linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值 r.linsert("list_name","BEFORE","2","SS")#在列表内找到第一个元素2,在它前面插入SS '''参数: name: redis的name where: BEFORE(前)或AFTER(后) refvalue: 列表内的值 value: 要插入的数据'''
r.lset(name, index, value)
#对list中的某一个索引位置重新赋值 r.lset("list_name",0,"bbb")
r.lrem(name, value, num)
#删除name对应的list中的指定值 r.lrem("list_name","SS",num=0) ''' 参数: name: redis的name value: 要删除的值 num: num=0 删除列表中所有的指定值; num=2 从前到后,删除2个; num=-2 从后向前,删除2个'''
lpop(name)
#移除列表的左侧第一个元素,返回值则是第一个元素 print(r.lpop("list_name"))
lindex(name, index)
#根据索引获取列表内元素 print(r.lindex("list_name",1))
lrange(name, start, end)
#分片获取元素 print(r.lrange("list_name",0,-1))
ltrim(name, start, end)
#移除列表内没有在该索引之内的值 r.ltrim("list_name",0,2)
rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边 #src 要取数据的列表 #dst 要添加数据的列表
brpoplpush(src, dst, timeout=0)
#同rpoplpush,多了个timeout, timeout:取数据的列表没元素后的阻塞时间,0为一直阻塞 r.brpoplpush("list_name","list_name1",timeout=0)
blpop(keys, timeout)
#将多个列表排列,按照从左到右去移除各个列表内的元素 r.lpush("list_name",3,4,5) r.lpush("list_name1",3,4,5) while True: print(r.blpop(["list_name","list_name1"],timeout=0)) print(r.lrange("list_name",0,-1),r.lrange("list_name1",0,-1)) '''keys: redis的name的集合 timeout: 超时时间,获取完所有列表的元素之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞'''
r.brpop(keys, timeout)
#同blpop,将多个列表排列,按照从右像左去移除各个列表内的元素
Set(集合)
Redis的Set是string类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是O(1)。
sadd 命令
添加一个string元素到,key对应的set集合中,成功返回1,如果元素以及在集合中返回0,key对应的set不存在返回错误。
- sadd key member
实例
- redis 127.0.0.1:6379> sadd redis.net.cn redis
- (integer) 1
- redis 127.0.0.1:6379> sadd redis.net.cn mongodb
- (integer) 1
- redis 127.0.0.1:6379> sadd redis.net.cn rabitmq
- (integer) 1
- redis 127.0.0.1:6379> sadd redis.net.cn rabitmq
- (integer) 0
- redis 127.0.0.1:6379> smembers redis.net.cn
- 1) "rabitmq"
- 2) "mongodb"
- 3) "redis"
注意:以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
Set集合就是不允许重复的列表
sadd(name,values)
#给name对应的集合中添加元素 r.sadd("set_name","aa") r.sadd("set_name","aa","bb")
smembers(name)
#获取name对应的集合的所有成员
scard(name)
#获取name对应的集合中的元素个数 r.scard("set_name")
sdiff(keys, *args)
#在第一个name对应的集合中且不在其他name对应的集合的元素集合 r.sadd("set_name","aa","bb") r.sadd("set_name1","bb","cc") r.sadd("set_name2","bb","cc","dd") print(r.sdiff("set_name","set_name1","set_name2"))#输出:{aa}
sdiffstore(dest, keys, *args)
#相当于把sdiff获取的值加入到dest对应的集合中
sinter(keys, *args)
# 获取多个name对应集合的并集 r.sadd("set_name","aa","bb") r.sadd("set_name1","bb","cc") r.sadd("set_name2","bb","cc","dd") print(r.sinter("set_name","set_name1","set_name2"))#输出:{bb}
sinterstore(dest, keys, *args)
#获取多个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name, value)
#检查value是否是name对应的集合内的元素
smove(src, dst, value)
#将某个元素从一个集合中移动到另外一个集合
spop(name)
#从集合的右侧移除一个元素,并将其返回
srandmember(name, numbers)
# 从name对应的集合中随机获取numbers个元素 print(r.srandmember("set_name2",2))
srem(name, values)
#删除name对应的集合中的某些值 print(r.srem("set_name2","bb","dd"))
sunion(keys, *args)
#获取多个name对应的集合的并集 r.sunion("set_name","set_name1","set_name2")
sunionstore(dest,keys, *args)
#获取多个name对应的集合的并集,并将结果保存到dest对应的集合中
有序集合:
在集合的基础上,为每元素排序,元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数专门用来做排序。
zadd(name, *args, **kwargs)
# 在name对应的有序集合中添加元素 r.zadd("zset_name", "a1", 6, "a2", 2,"a3",5) #或 r.zadd('zset_name1', b1=10, b2=5)
zcard(name)
#获取有序集合内元素的数量
zcount(name, min, max)
#获取有序集合中分数在[min,max]之间的个数 print(r.zcount("zset_name",1,5))
zincrby(name, value, amount)
#自增有序集合内value对应的分数 r.zincrby("zset_name","a1",amount=2)#自增zset_name对应的有序集合里a1对应的分数
zrange( name, start, end, desc=False, withscores=False, score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 aa=r.zrange("zset_name",0,1,desc=False,withscores=True,score_cast_func=int) print(aa) '''参数: name redis的name start 有序集合索引起始位置 end 有序集合索引结束位置 desc 排序规则,默认按照分数从小到大排序 withscores 是否获取元素的分数,默认只获取元素的值 score_cast_func 对分数进行数据转换的函数'''
zrevrange(name, start, end, withscores=False, score_cast_func=float)
#同zrange,集合是从大到小排序的
zrank(name, value)、zrevrank(name, value)
#获取value值在name对应的有序集合中的排行位置(从0开始) print(r.zrank("zset_name", "a2")) print(r.zrevrank("zset_name", "a2"))#从大到小排序
zscore(name, value)
#获取name对应有序集合中 value 对应的分数 print(r.zscore("zset_name","a1"))
zrem(name, values)
#删除name对应的有序集合中值是values的成员 r.zrem("zset_name","a1","a2")
zremrangebyrank(name, min, max)
#根据排行范围删除
zremrangebyscore(name, min, max)
#根据分数范围删除
zinterstore(dest, keys, aggregate=None)
r.zadd("zset_name", "a1", 6, "a2", 2,"a3",5) r.zadd('zset_name1', a1=7,b1=10, b2=5) # 获取两个有序集合的交集并放入dest集合,如果遇到相同值不同分数,则按照aggregate进行操作 # aggregate的值为: SUM MIN MAX r.zinterstore("zset_name2",("zset_name1","zset_name"),aggregate="MAX") print(r.zscan("zset_name2"))
zunionstore(dest, keys, aggregate=None)
#获取两个有序集合的并集并放入dest集合,其他同zinterstore,
其他常用操作
delete(*names)
#根据name删除redis中的任意数据类型
exists(name)
#检测redis的name是否存在
keys(pattern='*')
#根据* ?等通配符匹配获取redis的name
expire(name ,time)
# 为某个name设置超时时间
rename(src, dst)
# 重命名
move(name, db))
# 将redis的某个值移动到指定的db下
randomkey()
#随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd 命令
添加元素到集合,元素在集合中存在则更新对应score
- zadd key score member
实例
- redis 127.0.0.1:6379> zadd redis.net.cn 0 redis
- (integer) 1
- redis 127.0.0.1:6379> zadd redis.net.cn 0 mongodb
- (integer) 1
- redis 127.0.0.1:6379> zadd redis.net.cn 0 rabitmq
- (integer) 1
- redis 127.0.0.1:6379> zadd redis.net.cn 0 rabitmq
- (integer) 0
- redis 127.0.0.1:6379> ZRANGEBYSCORE redis.net.cn 0 1000
- 1) "redis"
- 2) "mongodb"
- 3) "rabitmq"
应用场景 - 实时用户统计 当我们需要在页面上显示当前的在线用户时,就可以使用Redis来完成了。首先获得当前时间(以Unix timestamps方式)除以60,可以基于这个值创建一个key。然后添加用户到这个集合中。当超过你设定的最大的超时时间,则将这个集合设为过期;而当需要查询当前在线用户的时候,则将最后N分钟的集合交集在一起即可。由于redis连接对象是线程安全的,所以可以直接使用一个全局变量来表示。
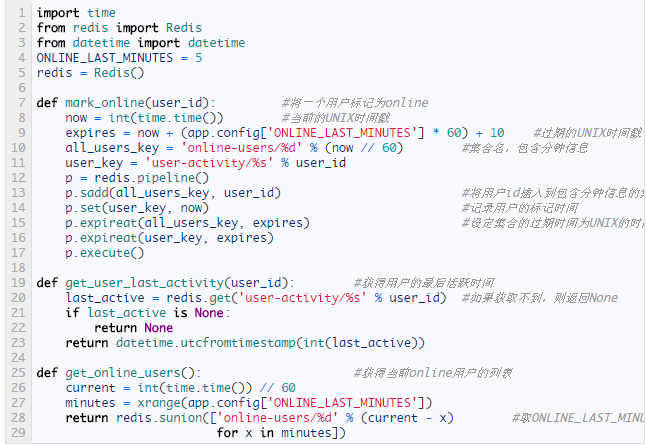
python操作redis
连接方式
redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
r = redis.Redis(host='192.168.0.110', port=6379,db=0)
r.set('name', 'zhangsan') #添加
print (r.get('name')) #获取
连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='192.168.0.110', port=6379)
r = redis.Redis(connection_pool=pool)
r.set('name', 'zhangsan') #添加
print (r.get('name')) #获取
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
pool = redis.ConnectionPool(host='192.168.0.110', port=6379)
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline(transaction=True)
r.set('name', 'zhangsan')
r.set('name', 'lisi')
pipe.execute()
发布和订阅
首先定义一个RedisHelper类,连接Redis,定义频道为monitor,定义发布(publish)及订阅(subscribe)方法。
#!/usr/bin/env python
#-*- coding:utf-8 -*-
import redis
class RedisHelper(object):
def __init__(self):
self.__conn = redis.Redis(host='192.168.0.110',port=6379)#连接Redis
self.channel = 'monitor' #定义名称
def publish(self,msg):#定义发布方法
self.__conn.publish(self.channel,msg)
return True
def subscribe(self):#定义订阅方法
pub = self.__conn.pubsub()
pub.subscribe(self.channel)
pub.parse_response()
return pub
发布者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#发布
from RedisHelper import RedisHelper
obj = RedisHelper()
obj.publish('hello')#发布
订阅者
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#订阅
from RedisHelper import RedisHelper
obj = RedisHelper()
redis_sub = obj.subscribe()#调用订阅方法
while True:
msg= redis_sub.parse_response()
print (msg)
任务异步化
打开浏览器,输入地址,按下回车,打开了页面。于是一个HTTP请求(request)就由客户端发送到服务器,服务器处理请求,返回响应(response)内容。
我们每天都在浏览网页,发送大大小小的请求给服务器。有时候,服务器接到了请求,会发现他也需要给另外的服务器发送请求,或者服务器也需要做另外一些事情,于是最初们发送的请求就被阻塞了,也就是要等待服务器完成其他的事情。
更多的时候,服务器做的额外事情,并不需要客户端等待,这时候就可以把这些额外的事情异步去做。从事异步任务的工具有很多。主要原理还是处理通知消息,针对通知消息通常采取是队列结构。生产和消费消息进行通信和业务实现。
生产消费与队列
上述异步任务的实现,可以抽象为生产者消费模型。如同一个餐馆,厨师在做饭,吃货在吃饭。如果厨师做了很多,暂时卖不完,厨师就会休息;如果客户很多,厨师马不停蹄的忙碌,客户则需要慢慢等待。实现生产者和消费者的方式用很多,下面使用Python标准库Queue写个小例子:
import random
import time
from Queue import Queue
from threading import Thread
queue = Queue(10)
class Producer(Thread):
def run(self):
while True:
elem = random.randrange(9)
queue.put(elem)
print "厨师 {} 做了 {} 饭 --- 还剩 {} 饭没卖完".format(self.name, elem, queue.qsize())
time.sleep(random.random())
class Consumer(Thread):
def run(self):
while True:
elem = queue.get()
print "吃货{} 吃了 {} 饭 --- 还有 {} 饭可以吃".format(self.name, elem, queue.qsize())
time.sleep(random.random())
def main():
for i in range(3):
p = Producer()
p.start()
for i in range(2):
c = Consumer()
c.start()
if __name__ == '__main__':
main()大概输出如下:
厨师 Thread-1 做了 1 饭 --- 还剩 1 饭没卖完
厨师 Thread-2 做了 8 饭 --- 还剩 2 饭没卖完
厨师 Thread-3 做了 3 饭 --- 还剩 3 饭没卖完
吃货Thread-4 吃了 1 饭 --- 还有 2 饭可以吃
吃货Thread-5 吃了 8 饭 --- 还有 1 饭可以吃
吃货Thread-4 吃了 3 饭 --- 还有 0 饭可以吃
厨师 Thread-1 做了 0 饭 --- 还剩 1 饭没卖完
厨师 Thread-2 做了 0 饭 --- 还剩 2 饭没卖完
厨师 Thread-1 做了 1 饭 --- 还剩 3 饭没卖完
厨师 Thread-1 做了 1 饭 --- 还剩 4 饭没卖完
吃货Thread-4 吃了 0 饭 --- 还有 3 饭可以吃
厨师 Thread-3 做了 3 饭 --- 还剩 4 饭没卖完
吃货Thread-5 吃了 0 饭 --- 还有 3 饭可以吃
吃货Thread-5 吃了 1 饭 --- 还有 2 饭可以吃
厨师 Thread-2 做了 8 饭 --- 还剩 3 饭没卖完
厨师 Thread-2 做了 8 饭 --- 还剩 4 饭没卖完Redis 队列
Python内置了一个好用的队列结构。我们也可以是用redis实现类似的操作。并做一个简单的异步任务。
Redis提供了两种方式来作消息队列。一个是使用生产者消费模式模式,另外一个方法就是发布订阅者模式。前者会让一个或者多个客户端监听消息队列,一旦消息到达,消费者马上消费,谁先抢到算谁的,如果队列里没有消息,则消费者继续监听。后者也是一个或多个客户端订阅消息频道,只要发布者发布消息,所有订阅者都能收到消息,订阅者都是ping的。
生产消费模式
主要使用了redis提供的blpop获取队列数据,如果队列没有数据则阻塞等待,也就是监听。
import redis
class Task(object):
def __init__(self):
self.rcon = redis.StrictRedis(host='localhost', db=5)
self.queue = 'task:prodcons:queue'
def listen_task(self):
while True:
task = self.rcon.blpop(self.queue, 0)[1]
print "Task get", task
if __name__ == '__main__':
print 'listen task queue'
Task().listen_task()发布订阅模式
使用redis的pubsub功能,订阅者订阅频道,发布者发布消息到频道了,频道就是一个消息队列。
import redis
class Task(object):
def __init__(self):
self.rcon = redis.StrictRedis(host='localhost', db=5)
self.ps = self.rcon.pubsub()
self.ps.subscribe('task:pubsub:channel')
def listen_task(self):
for i in self.ps.listen():
if i['type'] == 'message':
print "Task get", i['data']
if __name__ == '__main__':
print 'listen task channel'
Task().listen_task()Flask 入口
我们分别实现了两种异步任务的后端服务,直接启动他们,就能监听redis队列或频道的消息了。简单的测试如下:
import redis
import random
import logging
from flask import Flask, redirect
app = Flask(__name__)
rcon = redis.StrictRedis(host='localhost', db=5)
prodcons_queue = 'task:prodcons:queue'
pubsub_channel = 'task:pubsub:channel'
@app.route('/')
def index():
html = """
<br>
<center><h3>Redis Message Queue</h3>
<br>
<a href="/prodcons">生产消费者模式</a>
<br>
<br>
<a href="/pubsub">发布订阅者模式</a>
</center>
"""
return html
@app.route('/prodcons')
def prodcons():
elem = random.randrange(10)
rcon.lpush(prodcons_queue, elem)
logging.info("lpush {} -- {}".format(prodcons_queue, elem))
return redirect('/')
@app.route('/pubsub')
def pubsub():
ps = rcon.pubsub()
ps.subscribe(pubsub_channel)
elem = random.randrange(10)
rcon.publish(pubsub_channel, elem)
return redirect('/')
if __name__ == '__main__':
app.run(debug=True)启动脚本,使用
siege -c10 -r 5 http://127.0.0.1:5000/prodcons
siege -c10 -r 5 http://127.0.0.1:5000/pubsub可以分别在监听的脚本输入中看到异步消息。在异步的任务中,可以执行一些耗时间的操作,当然目前这些做法并不知道异步的执行结果,如果需要知道异步的执行结果,可以考虑设计协程任务或者使用一些工具如RQ或者celery等。
MemCache是什么
MemCache是一个自由、源码开放、高性能、分布式的分布式内存对象缓存系统,用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度。MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序语言。
MemCache和MemCached的区别:
- Redis支持服务器端的数据操作:Redis相比Memcached来说,拥有更多的数据结构和并支持更丰富的数据操作,通常在Memcached里,你需要将数据拿到客户端来进行类似的修改再set回去。这大大增加了网络IO的次数和数据体积。在Redis中,这些复杂的操作通常和一般的GET/SET一样高效。所以,如果需要缓存能够支持更复杂的结构和操作,那么Redis会是不错的选择。
- 内存使用效率对比:使用简单的key-value存储的话,Memcached的内存利用率更高,而如果Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached。
- 性能对比:由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起Memcached,还是稍有逊色。
MemCache的官方网站为http://memcached.org/
MemCache访问模型
为了加深理解,我模仿着原阿里技术专家李智慧老师《大型网站技术架构 核心原理与案例分析》一书MemCache部分,自己画了一张图:
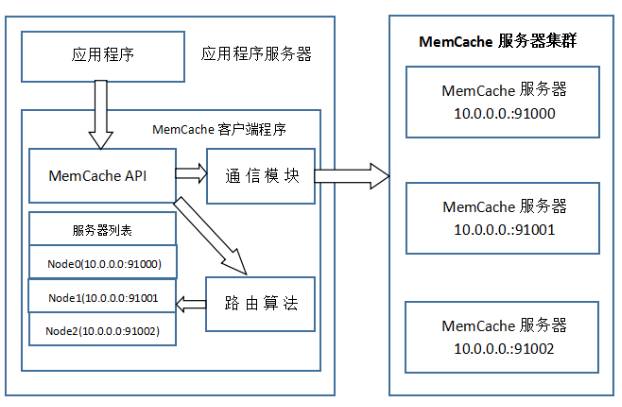
特别澄清一个问题,MemCache虽然被称为”分布式缓存”,但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信(与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据),所谓的”分布式”,完全依赖于客户端程序的实现,就像上面这张图的流程一样。
同时基于这张图,理一下MemCache一次写缓存的流程:
1、应用程序输入需要写缓存的数据
2、API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
3、由服务器编号得到MemCache及其的ip地址和端口号
4、API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作
读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中。
这种MemCache集群的方式也是从分区容错性的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
一致性Hash算法
从上面的图中,可以看出一个很重要的问题,就是对服务器集群的管理,路由算法至关重要,就和负载均衡算法一样,路由算法决定着究竟该访问集群中的哪台服务器,先看一个简单的路由算法。
1、余数Hash
比方说,字符串str对应的HashCode是50、服务器的数目是3,取余数得到2,str对应节点Node2,所以路由算法把str路由到Node2服务器上。由于HashCode随机性比较强,所以使用余数Hash路由算法就可以保证缓存数据在整个MemCache服务器集群中有比较均衡的分布。
如果不考虑服务器集群的伸缩性(什么是伸缩性,请参见大型网站架构学习笔记),那么余数Hash算法几乎可以满足绝大多数的缓存路由需求,但是当分布式缓存集群需要扩容的时候,就难办了。
就假设MemCache服务器集群由3台变为4台吧,更改服务器列表,仍然使用余数Hash,50对4的余数是2,对应Node2,但是str原来是存在Node1上的,这就导致了缓存没有命中。如果这么说不够明白,那么不妨举个例子,原来有HashCode为0~19的20个数据,那么:

现在我扩容到4台,加粗标红的表示命中:

如果我扩容到20+的台数,只有前三个HashCode对应的Key是命中的,也就是15%。当然这只是个简单例子,现实情况肯定比这个复杂得多,不过足以说明,使用余数Hash的路由算法,在扩容的时候会造成大量的数据无法正确命中(其实不仅仅是无法命中,那些大量的无法命中的数据还在原缓存中在被移除前占据着内存)。这个结果显然是无法接受的,在网站业务中,大部分的业务数据度操作请求上事实上是通过缓存获取的,只有少量读操作会访问数据库,因此数据库的负载能力是以有缓存为前提而设计的。当大部分被缓存了的数据因为服务器扩容而不能正确读取时,这些数据访问的压力就落在了数据库的身上,这将大大超过数据库的负载能力,严重的可能会导致数据库宕机。
这个问题有解决方案,解决步骤为:
(1)在网站访问量低谷,通常是深夜,技术团队加班,扩容、重启服务器
(2)通过模拟请求的方式逐渐预热缓存,使缓存服务器中的数据重新分布
2、一致性Hash算法
一致性Hash算法通过一个叫做一致性Hash环的数据结构实现Key到缓存服务器的Hash映射,看一下我自己画的一张图:
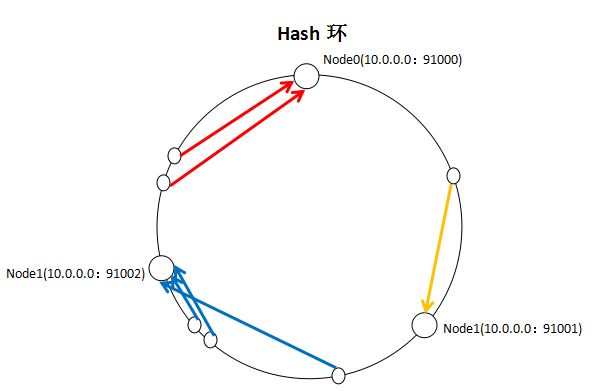
具体算法过程为:先构造一个长度为232的整数环(这个环被称为一致性Hash环),根据节点名称的Hash值(其分布为[0, 232-1])将缓存服务器节点放置在这个Hash环上,然后根据需要缓存的数据的Key值计算得到其Hash值(其分布也为[0, 232-1]),然后在Hash环上顺时针查找距离这个Key值的Hash值最近的服务器节点,完成Key到服务器的映射查找。
就如同图上所示,三个Node点分别位于Hash环上的三个位置,然后Key值根据其HashCode,在Hash环上有一个固定位置,位置固定下之后,Key就会顺时针去寻找离它最近的一个Node,把数据存储在这个Node的MemCache服务器中。使用Hash环如果加了一个节点会怎么样,看一下:
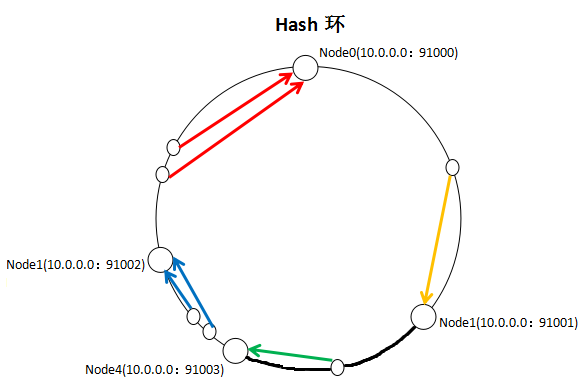
看到我加了一个Node4节点,只影响到了一个Key值的数据,本来这个Key值应该是在Node1服务器上的,现在要去Node4了。采用一致性Hash算法,的确也会影响到整个集群,但是影响的只是加粗的那一段而已,相比余数Hash算法影响了远超一半的影响率,这种影响要小得多。更重要的是,集群中缓存服务器节点越多,增加节点带来的影响越小,很好理解。换句话说,随着集群规模的增大,继续命中原有缓存数据的概率会越来越大,虽然仍然有小部分数据缓存在服务器中不能被读到,但是这个比例足够小,即使访问数据库,也不会对数据库造成致命的负载压力。
至于具体应用,这个长度为232的一致性Hash环通常使用二叉查找树实现,至于二叉查找树,就是算法的问题了,可以自己去查询相关资料。
解析
然后我们来看一下MemCache的原理,MemCache最重要的莫不是内存分配的内容了,MemCache采用的内存分配方式是固定空间分配,还是自己画一张图说明:

这张图片里面涉及了slab_class、slab、page、chunk四个概念,它们之间的关系是:
1、MemCache将内存空间分为一组slab
2、每个slab下又有若干个page,每个page默认是1M,如果一个slab占用100M内存的话,那么这个slab下应该有100个page
3、每个page里面包含一组chunk,chunk是真正存放数据的地方,同一个slab里面的chunk的大小是固定的
4、有相同大小chunk的slab被组织在一起,称为slab_class
MemCache内存分配的方式称为allocator,slab的数量是有限的,几个、十几个或者几十个,这个和启动参数的配置相关。
MemCache中的value过来存放的地方是由value的大小决定的,value总是会被存放到与chunk大小最接近的一个slab中,比如slab[1]的chunk大小为80字节、slab[2]的chunk大小为100字节、slab[3]的chunk大小为128字节(相邻slab内的chunk基本以1.25为比例进行增长,MemCache启动时可以用-f指定这个比例),那么过来一个88字节的value,这个value将被放到2号slab中。放slab的时候,首先slab要申请内存,申请内存是以page为单位的,所以在放入第一个数据的时候,无论大小为多少,都会有1M大小的page被分配给该slab。申请到page后,slab会将这个page的内存按chunk的大小进行切分,这样就变成了一个chunk数组,最后从这个chunk数组中选择一个用于存储数据。
如果这个slab中没有chunk可以分配了怎么办,如果MemCache启动没有追加-M(禁止LRU,这种情况下内存不够会报Out Of Memory错误),那么MemCache会把这个slab中最近最少使用的chunk中的数据清理掉,然后放上最新的数据。针对MemCache的内存分配及回收算法,总结三点:
1、MemCache的内存分配chunk里面会有内存浪费,88字节的value分配在128字节(紧接着大的用)的chunk中,就损失了30字节,但是这也避免了管理内存碎片的问题
2、MemCache的LRU算法不是针对全局的,是针对slab的
3、应该可以理解为什么MemCache存放的value大小是限制的,因为一个新数据过来,slab会先以page为单位申请一块内存,申请的内存最多就只有1M,所以value大小自然不能大于1M了
特性和限制
Memcached单进程在32位系统中最大使用内存为2G,若在64位系统则没有限制,这是由于32位系统限制单进程最多可使用2G内存,要使用更多内存,可以分多个端口开启多个Memcached进程 ,
最大30天的数据过期时间,设置为永久的也会在这个时间过期,常量REALTIME_MAXDELTA
60*60*24*30控制
最大键长为250字节,大于该长度无法存储,常量KEY_MAX_LENGTH 250控制
单个item最大数据是1MB,超过1MB数据不予存储,常量POWER_BLOCK 1048576进行控制,
它是默认的slab大小
最大同时连接数是200,通过 conn_init()中的freetotal进行控制,最大软连接数是1024,通过
settings.maxconns=1024 进行控制
跟空间占用相关的参数:settings.factor=1.25, settings.chunk_size=48, 影响slab的数据占用和步进方式
memcached分服务器端和客户端,可以配置多个服务器端和客户端,应用于分布式的服务非常广泛。
memcached作为小规模的数据分布式平台是十分有效果的。
简单安装:
1.分别把memcached和libevent下载回来,放到 /tmp 目录下:
# cd /tmp
# wget http://www.danga.com/memcached/dist/memcached-1.2.0.tar.gz
# wget http://www.monkey.org/~provos/libevent-1.2.tar.gz

2.先安装libevent:
# tar zxvf libevent-1.2.tar.gz
# cd libevent-1.2
# ./configure -prefix=/usr
# make (如果遇到提示gcc 没有安装则先安装gcc)
# make install
3.测试libevent是否安装成功:
# ls -al /usr/lib | grep libevent
lrwxrwxrwx 1 root root 21 11?? 12 17:38 libevent-1.2.so.1 -> libevent-1.2.so.1.0.3
-rwxr-xr-x 1 root root 263546 11?? 12 17:38 libevent-1.2.so.1.0.3
-rw-r-r- 1 root root 454156 11?? 12 17:38 libevent.a
-rwxr-xr-x 1 root root 811 11?? 12 17:38 libevent.la
lrwxrwxrwx 1 root root 21 11?? 12 17:38 libevent.so -> libevent-1.2.so.1.0.3
还不错,都安装上了。
4.安装memcached,同时需要安装中指定libevent的安装位置:
# cd /tmp
# tar zxvf memcached-1.2.0.tar.gz
# cd memcached-1.2.0
# ./configure -with-libevent=/usr
# make
# make install
如果中间出现报错,请仔细检查错误信息,按照错误信息来配置或者增加相应的库或者路径。
安装完成后会把memcached放到 /usr/local/bin/memcached ,
5.测试是否成功安装memcached:
# ls -al /usr/local/bin/mem*
-rwxr-xr-x 1 root root 137986 11?? 12 17:39 /usr/local/bin/memcached
-rwxr-xr-x 1 root root 140179 11?? 12 17:39 /usr/local/bin/memcached-debug
启动memcache服务
启动Memcached服务:
1.启动Memcache的服务器端:
# /usr/local/bin/memcached -d -m 8096 -u root -l 192.168.77.105 -p 12000 -c 256 -P /tmp/memcached.pid
-d选项是启动一个守护进程,
-m是分配给Memcache使用的内存数量,单位是MB,我这里是8096MB,
-u是运行Memcache的用户,我这里是root,
-l是监听的服务器IP地址,如果有多个地址的话,我这里指定了服务器的IP地址192.168.77.105,
-p是设置Memcache监听的端口,我这里设置了12000,最好是1024以上的端口,
-c选项是最大运行的并发连接数,默认是1024,我这里设置了256,按照你服务器的负载量来设定,
-P是设置保存Memcache的pid文件,我这里是保存在 /tmp/memcached.pid,
2.如果要结束Memcache进程,执行:
# cat /tmp/memcached.pid 或者 ps -aux | grep memcache (找到对应的进程id号)
# kill 进程id号
也可以启动多个守护进程,不过端口不能重复。
memcache 的连接
telnet ip port
注意连接之前需要再memcache服务端把memcache的防火墙规则加上
-A RH-Firewall-1-INPUT -m state --state NEW -m tcp -p tcp --dport 3306 -j ACCEPT
重新加载防火墙规则
service iptables restart
OK ,现在应该就可以连上memcache了
在客户端输入stats 查看memcache的状态信息

pid memcache服务器的进程ID
uptime 服务器已经运行的秒数
time 服务器当前的unix时间戳
version memcache版本
pointer_size 当前操作系统的指针大小(32位系统一般是32bit)
rusage_user 进程的累计用户时间
rusage_system 进程的累计系统时间
curr_items 服务器当前存储的items数量
total_items 从服务器启动以后存储的items总数量
bytes 当前服务器存储items占用的字节数
curr_connections 当前打开着的连接数
total_connections 从服务器启动以后曾经打开过的连接数
connection_structures 服务器分配的连接构造数
cmd_get get命令 (获取)总请求次数
cmd_set set命令 (保存)总请求次数
get_hits 总命中次数
get_misses 总未命中次数
evictions 为获取空闲内存而删除的items数(分配给memcache的空间用满后需要删除旧的items来得到空间分配给新的items)
bytes_read 读取字节数(请求字节数)
bytes_written 总发送字节数(结果字节数)
limit_maxbytes 分配给memcache的内存大小(字节)
threads 当前线程数