一、文件打开
open(path,flag[,encoding][,errors])
参数说明:
path:要打开文件的路径
flag:打开方式(
r:以只读的方式打开文件,文件的描述符放在文件开头
rb:以二进制格式只读的方式打开文件,文件的描述符放在文件开头
r+:打开一个文件用于读写,文件描述符放在文件的开头
w:打开一个文件只用于写入,文件的描述符放在文件的开头,如果该文件已经存在会覆盖,如果不存在则创建新文件
wb:打开一个文件只用于写入二进制,如果该文件会覆盖,如果该文件不存在新创建文件
w+:打开一个文件用于读写,如果该文件存在会覆盖,如果该文件不存在新创建文件
a:打开一个文件用于追加,如果文件存在文件描述符将会被放到文件末尾
a+:打开一个文件用于追加)
encoding:编码方式
errors:错误处理
errors="ignore" 忽略错误
二、文件指针
seek(offset[,whence]) 移动文件指针位置,offest偏移多少字节,whence从哪里开始;
mode=r(只读) 指针其实位置在0
mode=a(追加 ) 指针其实在EOF
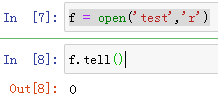
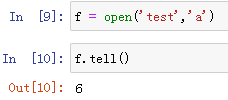
tell() 显示指针当前位置
文本模式下:
whence 0 缺省值,表示从头开始,offest只能接受正整数;
whence 1 表示从当前位置;offset只接受0;
whence 2 表示从EOF开始,offset只接受0;
示例:
f = open('test',r+)
f.write('abcdefg')
此时指针在末尾,当f.read()读的时候是没有数据的;
f.seek(3) 表示偏移3个字节,f.read()的结果为defg;
当f.seek(0),指针到开头时,再去f.read()的时候就可以读取到数据了;
f.seek(0,1),表示指针回到末尾;
whence只接受0,1,2三个参数;
中文示例:
f = open('test',r+)
f.write('北京欢迎你')
测试:
在mac中运行:
f.seek(2)
f.read()
会报错,UnicodeDecodeError;f.seek(3)则不报错,在mac系统中,一个中文占3个字节;
在windows中运行:
f.seek()
f.read()
不会报错,在windows系统中,一个中文占2个字节;
二进制模式下:
whence 0 缺省值,表示从头开始,offset只能是正整数
whence 1 表示从当前位置开始,offset可正可负;
whence 2 表示从EOF开始,offset可正可负;
f=open('test','rb+')
f.write('abcdef')
示例:
f.seek(-3,2) 从文件末尾开始向左偏移3,得到的结果为def; 二进制模式下支持任意起点的偏移,从头,从尾,从中间位置开始; 向后seek可以超界,但是向前seek的时候,不能超界,否则抛异常;
三、buffer缓冲区
-1表示使用缺省大小的buffer,如果是二进制模式,使用io.DEFAULT_BUFFER_SIZE值,默认是4096或者8192(字节);如果是文本模式,如果是终端设备,是行缓存的方式,如果不是,则使用二进制模式的策略;
0 只在二进制模式中使用,表示关闭buffer;
1 只在文本模式中使用,表示使用行缓冲,意思就是见到换行符就flush;
1< 大于1用于指定buffer的大小;
缓冲一般是一个队列;缓存一般是字典的方式存储;
缓冲区是一个内存空间,一般来说是FIFO(先进先出)队列,到缓冲区满了或者达到阈值,数据才会flush到磁盘;
flush() 将缓冲区数据写入磁盘;
close() 关闭前会调用flush()
示例:
f = open('test','w+')
f.write('!'*1024)
这时候分两种情况:
1、当执行一次写操作,再执行一次seek,或者tell或者read的时候,指针都会发生变化,因此会进行一次flush,将缓冲区的内容写入磁盘,cat test就可以看到内容;
2、当只执行写操作,不做seek、read、tell操作,这时候写的内容在缓冲区,没有写入磁盘,因此cat test是看不到内容的;当我连续执行了9次写操作,再去cat test的时候发现可以看到内容了,这是>因为,默认缓冲区8192字节(8K)写满溢出了,做了一次flush;
import io
print(io.DEFAULT_BUFFER_SIZE)。查看默认缓冲区大小;
在文本模式中,f = open('test','w+',4),指定buffer大小为4,似乎不起作用,依然用的是系统默认的buffer_size;
示例2:
在二进制模式中关闭buffer;
f = open('test','wb+',0) #0表示在二进制模式中关闭buffer
f.write(b'!'*1024)
此时的效果就是,不写buffer,立即写磁盘;
总结:
1、文本模式中,一般都用默认缓冲区大小;
2、二进制模式,是一个个字节的操作,可以指定buffer的大小;
3、一般来说,默认缓冲区大小是个比较好的选择,除非明确知道,否则不调整它;
4、一般编程中,明确知道要写磁盘了,都会手动调用一次flush,而不是等到自动flush或者close的时候;
encoding:编码,仅文本模式使用
windows下缺省GBK(0xBOA1),linux下缺省UTF-8(0xE5 95 8A)
四、其他参数
newline
该参数用来指定读取时,对换行符的处理;文本模式中,换行的转换,可以为None,空串,
、
、
;
mac的换行符是
;Linux的换行符是
;windows的换行符是
;
读取文件时:
测试文件的换行符都是 ;
情况1:缺省为None,表示通用换行符“ ”,即文件换行符是啥,读出来都是“ ”;
当读取文件时,所有的 都被替换成了 ;
情况2:newline = "",表示读取的换行符保持不变;
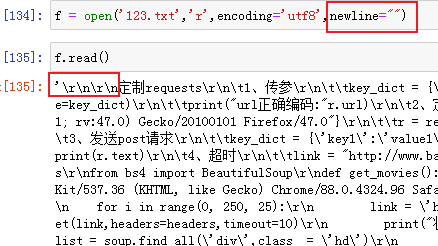
情况3:newline=" ",newline=" ",表示换行符就是指定字符,就会按照指定的字符分行;执行效果跟情况2一样;
文件写入时:
情况1:缺省值为None;写入的" "自动变为系统默认的换行符;写入“ ”,用notepad++打开发现被替换成了系统默认的换行符;


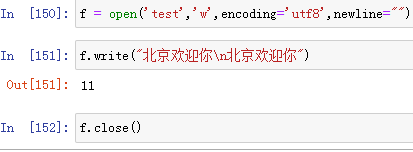
情况2:newline="" 和 newline=" ",表示不做任何转换写入;

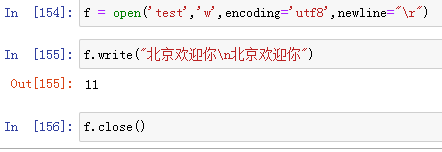
情况3:newline=" " 表示将“ ”、“ ”都当做“ ”写入;

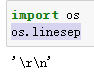
os.linesep
查看操作系统默认的换行符
read
read(size=-1)
size表示读取的多少个字符或者字节,负数或者None表示读取到EOF;
行读取
readline(size=-1)
一行一行读取文件内容,size设置一次能读取行内几个字符或者字节;
readlines(hint=-1)
读取所有行的列表,指定hint则返回指定的行数;
示例:
读取文件内容的时候,可以不用readlines;可以直接迭代;
f = open('test','r+') for line in f: print(line)
write
write(s) 把字符串s写入到文件中并返回字符的个数;
writelines(lines) 将字符串列表写入文件;
close
释放文件描述符,并关闭文件对象;
其他
seekable() 是否可seek
readable() 是否可读
writeable() 是否可写
closed 是否已经关闭
上下文管理
问题的引出,在Linux中执行:
# -*- coding: utf-8 -*- lst = [] for _ in range(2000): lst.append(open('test')) print(len(lst))
在Linux下执行该python脚本,发现会报错,“OSError: [Errno 24] Too many open files: 'test'”;这是因为打开的文件数过多,超过了系统定义的最大文件打开数;
可以用ulimit -n查看系统的最大文件打开数;
由此,这种只打开,不关闭的情况,会导致系统的最大文件打开数耗尽;为了避免这种情况的发生,python提供了上下文管理,它会在程序运行结束后,自动关闭文件;
with
一种特殊语法,交给解释器去释放文件对象;
写法1:
with open('test') as f:
f.write('abcdefg')
with语句块执行完成后,会自动关闭文件对象;
写法2:
f = open('test','w+')
with f:
f.write('abcdefg')
#f.write(str(1/0)) 抛异常,验证在抛异常情况下,是否能关闭文件,f.closed 查看是否关闭;