数据库存储引擎
一 什么是存储引擎
mysql中建立的库===>文件夹
库中建立的表===>文件
现实生活中我们用来存储数据的文件应该有不同的类型:比如存文本用txt类型,存表格用excel,存图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方
法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和
操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎
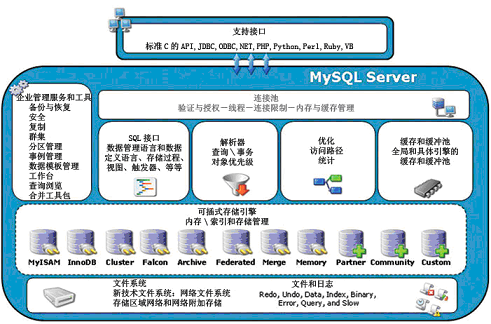
二 mysql支持的存储引擎
MariaDB [(none)]> show enginesG #查看所有支持的存储引擎 MariaDB [(none)]> show variables like 'storage_engine%'; #查看正在使用的存储引擎
MySQL常用的存储引擎
MyISAM存储引擎
由于该存储引擎不支持事务、也不支持外键,所以访问速度较快。因此当对事务完整性没有要求并以访问为主的应用适合使用该存储引擎。
InnoDB存储引擎(主要使用)
由于该存储引擎在事务上具有优势,即支持具有提交、回滚及崩溃恢复能力等事务特性,所以比MyISAM存储引擎占用更多的磁盘空间。因此当需要频繁的更新、删除操作,同时还对事务的完整性要求较高,需要实现并发控制,建议选择。
MEMORY
MEMORY存储引擎存储数据的位置是内存,因此访问速度最快,但是安全上没有保障。适合于需要快速的访问或临时表。
BLACKHOLE
黑洞存储引擎,可以应用于主备复制中的分发主库。
三 使用存储引擎
方法1:建表时指定
MariaDB [db1]> create table innodb_t1(id int,name char)engine=innodb; MariaDB [db1]> create table innodb_t2(id int)engine=innodb; MariaDB [db1]> show create table innodb_t1; MariaDB [db1]> show create table innodb_t2;
方法2:在配置文件中指定默认的存储引擎
/etc/my.cnf [mysqld] default-storage-engine=INNODB innodb_file_per_table=1
查看
[root@egon db1]# cd /var/lib/mysql/db1/ [root@egon db1]# ls db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
练习
创建四个表,分别使用innodb,myisam,memory,blackhole存储引擎,进行插入数据测试
MariaDB [db1]> create table t1(id int)engine=innodb; MariaDB [db1]> create table t2(id int)engine=myisam; MariaDB [db1]> create table t3(id int)engine=memory; MariaDB [db1]> create table t4(id int)engine=blackhole; MariaDB [db1]> quit [root@egon db1]# ls /var/lib/mysql/db1/ #发现后两种存储引擎只有表结构,无数据 db.opt t1.frm t1.ibd t2.MYD t2.MYI t2.frm t3.frm t4.frm #memory,在重启mysql或者重启机器后,表内数据清空 #blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
视图
视图是一个虚拟表(非真实存在),其本质是【根据SQL语句获取动态的数据集,并为其命名】,用户使用时只需使用【名称】即可获取结果集,并可以将其当作表来使用。
SELECT
*
FROM
(
SELECT
nid,
NAME
FROM
tb1
WHERE
nid > 2
) AS A
WHERE
A. NAME > 'alex';
创建视图
--格式:CREATE VIEW 视图名称 AS SQL语句
CREATE VIEW v1 AS
SELET nid,
name
FROM
A
WHERE
nid > 4
删除视图
--格式:DROP VIEW 视图名称 DROP VIEW v1
修改视图
-- 格式:ALTER VIEW 视图名称 AS SQL语句
ALTER VIEW v1 AS
SELET A.nid,
B. NAME
FROM
A
LEFT JOIN B ON A.id = B.nid
LEFT JOIN C ON A.id = C.nid
WHERE
A.id > 2
AND C.nid < 5
使用视图
使用视图时,将其当作表进行操作即可,由于视图是虚拟表,所以无法使用其对真实表进行创建、更新和删除操作,仅能做查询用。
select * from v1
触发器
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为。
创建基本语法
-- 插入前
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
...
END
-- 插入后
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
...
END
-- 删除前
CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW
BEGIN
...
END
-- 删除后
CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW
BEGIN
...
END
-- 更新前
CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END
-- 更新后
CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW
BEGIN
...
END
示例1:
delimiter //
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW
BEGIN
IF NEW. NAME == 'alex' THEN
INSERT INTO tb2 (NAME)
VALUES
('aa')
END
END//
delimiter ;
示例2:
delimiter //
CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW
BEGIN
IF NEW. num = 666 THEN
INSERT INTO tb2 (NAME)
VALUES
('666'),
('666') ;
ELSEIF NEW. num = 555 THEN
INSERT INTO tb2 (NAME)
VALUES
('555'),
('555') ;
END IF;
END//
delimiter ;
特别的:NEW表示即将插入的数据行,OLD表示即将删除的数据行。
删除触发器
DROP TRIGGER tri_after_insert_tb1;
使用触发器
insert into tb1(num) values(666)
存储过程
存储过程是一个SQL语句集合,当主动去调用存储过程时,其中内部的SQL语句会按照逻辑执行。
创建存储过程
-- 创建存储过程
delimiter //
create procedure p1()
BEGIN
select * from t1;
END//
delimiter ;
-- 执行存储过程
call p1()
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
有参数的存储过程:
-- 创建存储过程
delimiter \
create procedure p1(
in i1 int,
in i2 int,
inout i3 int,
out r1 int
)
BEGIN
DECLARE temp1 int;
DECLARE temp2 int default 0;
set temp1 = 1;
set r1 = i1 + i2 + temp1 + temp2;
set i3 = i3 + 100;
end\
delimiter ;
-- 执行存储过程
set @t1 =4;
set @t2 = 0;
CALL p1 (1, 2 ,@t1, @t2);
SELECT @t1,@t2;
结果集:
delimiter //
create procedure p1()
begin
select * from v1;
end //
delimiter ;
结果集+out:
delimiter //
create procedure p2(
in n1 int,
inout n3 int,
out n2 int,
)
begin
declare temp1 int ;
declare temp2 int default 0;
select * from v1;
set n2 = n1 + 100;
set n3 = n3 + n1 + 100;
end //
delimiter ;
事务:
delimiter \
create PROCEDURE p1(
OUT p_return_code tinyint
)
BEGIN
DECLARE exit handler for sqlexception
BEGIN
-- ERROR
set p_return_code = 1;
rollback;
END;
DECLARE exit handler for sqlwarning
BEGIN
-- WARNING
set p_return_code = 2;
rollback;
END;
START TRANSACTION;
DELETE from tb1;
insert into tb2(name)values('seven');
COMMIT;
-- SUCCESS
set p_return_code = 0;
END\
delimiter ;
游标:
delimiter //
create procedure p3()
begin
declare ssid int; -- 自定义变量1
declare ssname varchar(50); -- 自定义变量2
DECLARE done INT DEFAULT FALSE;
DECLARE my_cursor CURSOR FOR select sid,sname from student;
DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE;
open my_cursor;
xxoo: LOOP
fetch my_cursor into ssid,ssname;
if done then
leave xxoo;
END IF;
insert into teacher(tname) values(ssname);
end loop xxoo;
close my_cursor;
end //
delimter ;
动态执行sql:
delimiter \
CREATE PROCEDURE p4 (
in nid int
)
BEGIN
PREPARE prod FROM 'select * from student where sid > ?';
EXECUTE prod USING @nid;
DEALLOCATE prepare prod;
END\
delimiter ;
删除存储过程
drop procedure proc_name;
执行存储过程
-- 无参数 call proc_name() -- 有参数,全in call proc_name(1,2) -- 有参数,有in,out,inout set @t1=0; set @t2=3; call proc_name(1,2,@t1,@t2)
用户操作与权限管理
MySQL用户操作
创建用户
方法一: CREATE USER语句创建
CREATE USER 用户名@’IP地址’ IDENTIFIED BY ‘密码’;
方法二: INSERT语句创建
INSERT INTO mysql.user(user,host, password,ssl_cipher,x509_issuer,x509_subject)
VALUES(‘用户名’,’IP地址’,password(‘密码’),’’,’’,’’);
FLUSH PRIVILEGES;
方法三: GRANT语句创建
GRANT SELECT ON *.* TO 用户名@’IP地址’ IDENTIFIED BY ‘密码’;
FLUSH PRIVILEGES;
删除用户
方法一:DROP USER语句删除
DROP USER 用户名@’IP地址’;
方法二:DELETE语句删除
DELETE FROM mysql.user
WHERE user=’用户名’ AND host=’IP地址’;
FLUSH PRIVILEGES;
修改密码
root用户修改自己密码:
方法一:
# mysqladmin -uroot -p123 password 'new_password' //123为旧密码
方法二:
UPDATE mysql.user SET password=password(‘new_password’)
WHERE user=’root’ AND host=’localhost’;
FLUSH PRIVILEGES;
方法三:
SET PASSWORD=password(‘new_password’);
FLUSH PRIVILEGES;
root修改其他用户密码:
方法一:
SET PASSWORD FOR 用户名@’IP地址’=password(‘new_password’);
FLUSH PRIVILEGES;
方法二:
UPDATE mysql.user SET password=password(‘new_password’)
WHERE user=’用户名’ AND host=’IP地址’;
FLUSH PRIVILEGES;
方法三:
GRANT SELECT ON *.* TO user3@’localhost’ IDENTIFIED BY ‘yuan’;
FLUSH PRIVILEGES;
普通用户修改自己密码:
SET password=password(‘new_password’);
丢失root用户密码:
# vim /etc/my.cnf
skip-grant-tables
# service mysqld restart
# mysql -uroot
mysql> UPDATE mysql.user SET password=password(‘new_password’)
WHERE user=’root’ AND host=’localhost’;
mysql> FLUSH PRIVILEGES;
修改用户名:
rename user '用户名'@'IP地址'; to '新用户名'@'IP地址';
注解 flush privileges:
/* flush privileges 命令本质上的作用是将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。 MySQL用户数据和权限有修改后,搜索希望在"不重启MySQL服务"的情况下直接生效,那么就需要执行这个命令 */
MySQL权限管理
授权
--语法格式:
grant 权限列表 on 库名.表名 to 用户名@'客户端主机' [identified by '密码' with option参数];
示例:


-- 给该用户授予对数据库db1下的表tb1所有的操作权限 grant all privileges on db1.tb1 TO '用户名'@'IP' -- 给该用户授予对数据库db1下所有表进行查操作的权限 grant select on db1.* TO '用户名'@'IP' -- 给该用户授予对所有数据库下所有表进行查和增的操作 grant select,insert on *.* TO '用户名'@'IP' -- 用户只能在该IP段下才能(通配符%表示任意)对所有数据库下所有表进行查操作 grant select on *.* TO '用户名'@'192.168.1.%' -- 用户能用户可以在任意IP下(通配符%表示任意)对所有数据库下所有表进行查操作 grant select on *.* TO '用户名'@'%'
with_option参数:
GRANT OPTION: -- 授权选项
MAX_QUERIES_PER_HOUR: -- 定义每小时允许执行的查询数
MAX_UPDATES_PER_HOUR: -- 定义每小时允许执行的更新数
MAX_CONNECTIONS_PER_HOUR: -- 定义每小时可以建立的连接数
MAX_USER_CONNECTIONS: -- 定义单个用户同时可以建立的连接数
示例: 限制用户每小时的查询数量
mysql> grant select on *.* to '用户名'@'IP地址' identified by '123456' with max_queries_per_hour 5;
查看权限
show grants for '用户'@'IP地址'
回收权限
--语法:
REVOKE 权限列表 ON 库名.表名 FROM 用户名@‘客户端主机’
示例:
REVOKE DELETE ON *.* FROM 用户名@’%’; -- 回收部分权限 REVOKE ALL PRIVILEGES FROM 用户名@’%’; -- 回收所有权限
索引
一 索引简介
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。
索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引特点:创建与维护索引会消耗很多时间与磁盘空间,但查询速度大大提高!
二 索引语法
创建索引
--创建表时
--语法:
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
--------------------------------
--创建普通索引示例:
CREATE TABLE emp1 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_emp_name (name)
--KEY index_dept_name (dept_name)
);
--创建唯一索引示例:
CREATE TABLE emp2 (
id INT,
name VARCHAR(30) ,
bank_num CHAR(18) UNIQUE ,
resume VARCHAR(50),
UNIQUE INDEX index_emp_name (name)
);
--创建全文索引示例:
CREATE TABLE emp3 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
FULLTEXT INDEX index_resume (resume)
);
--创建多列索引示例:
CREATE TABLE emp4 (
id INT,
name VARCHAR(30) ,
resume VARCHAR(50),
INDEX index_name_resume (name,resume)
);
---------------------------------
添加和删除索引
---添加索引
---CREATE在已存在的表上创建索引
CREATE [UNIQUE] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
---ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE] INDEX
索引名 (字段名[(长度)] [ASC |DESC]) ;
CREATE INDEX index_emp_name on emp1(name);
ALTER TABLE emp2 ADD UNIQUE INDEX index_bank_num(band_num);
-- 删除索引
语法:DROP INDEX 索引名 on 表名
DROP INDEX index_emp_name on emp1;
DROP INDEX bank_num on emp2;
三 索引测试实验
--创建表 create table Indexdb.t1(id int,name varchar(20)); --存储过程 delimiter $$ create procedure autoinsert() BEGIN declare i int default 1; while(i<500000)do insert into Indexdb.t1 values(i,'yuan'); set i=i+1; end while; END$$ delimiter ; --调用函数 call autoinsert(); -- 花费时间比较: -- 创建索引前 select * from Indexdb.t1 where id=300000;--0.32s -- 添加索引 create index index_id on Indexdb.t1(id); -- 创建索引后 select * from Indexdb.t1 where id=300000;--0.00s