scrapy-redis是一个基于redis的scrapy组件,通过它可以快速实现简单分布式爬虫程序,该组件本质上提供了三大功能:
- scheduler - 调度器
- dupefilter - URL去重规则(被调度器使用)
- pipeline - 数据持久化
分布式爬虫优点:
充分利用多机器的宽带加速爬取
充分利用多机器的IP加速爬取速度
scrapy-redis组件
1. URL去重
定义去重规则(被调度器调用并应用)
a. 内部会使用以下配置进行连接Redis
# REDIS_HOST = 'localhost' # 主机名
# REDIS_PORT = 6379 # 端口
# REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置)
# REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,})
# REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis
# REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8'
b. 去重规则通过redis的集合完成,集合的Key为:
key = defaults.DUPEFILTER_KEY % {'timestamp': int(time.time())}
默认配置:
DUPEFILTER_KEY = 'dupefilter:%(timestamp)s'
c. 去重规则中将url转换成唯一标示,然后在redis中检查是否已经在集合中存在
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.cnblogs.com/wupeiqi.html')
result = request.request_fingerprint(req)
print(result) # 8ea4fd67887449313ccc12e5b6b92510cc53675c
PS:
- URL参数位置不同时,计算结果一致;
- 默认请求头不在计算范围,include_headers可以设置指定请求头
示例:
from scrapy.utils import request
from scrapy.http import Request
req = Request(url='http://www.baidu.com?name=8&id=1',callback=lambda x:print(x),cookies={'k1':'vvvvv'})
result = request.request_fingerprint(req,include_headers=['cookies',])
print(result)
req = Request(url='http://www.baidu.com?id=1&name=8',callback=lambda x:print(x),cookies={'k1':666})
result = request.request_fingerprint(req,include_headers=['cookies',])
print(result)
"""
# Ensure all spiders share same duplicates filter through redis.
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2. 调度器
"""
调度器,调度器使用PriorityQueue(有序集合)、FifoQueue(列表)、LifoQueue(列表)进行保存请求,并且使用RFPDupeFilter对URL去重
a. 调度器
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表)
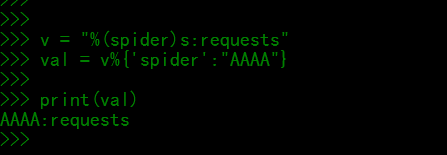
SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key
SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle
SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空
SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。
SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key
SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 去重规则对应处理的类
"""
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Default requests serializer is pickle, but it can be changed to any module
# with loads and dumps functions. Note that pickle is not compatible between
# python versions.
# Caveat: In python 3.x, the serializer must return strings keys and support
# bytes as values. Because of this reason the json or msgpack module will not
# work by default. In python 2.x there is no such issue and you can use
# 'json' or 'msgpack' as serializers.
# SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat"
# Don't cleanup redis queues, allows to pause/resume crawls.
# SCHEDULER_PERSIST = True
# Schedule requests using a priority queue. (default)
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
# Alternative queues.
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue'
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue'
# Max idle time to prevent the spider from being closed when distributed crawling.
# This only works if queue class is SpiderQueue or SpiderStack,
# and may also block the same time when your spider start at the first time (because the queue is empty).
# SCHEDULER_IDLE_BEFORE_CLOSE = 10
3. 数据持久化
2. 定义持久化,爬虫yield Item对象时执行RedisPipeline
a. 将item持久化到redis时,指定key和序列化函数
REDIS_ITEMS_KEY = '%(spider)s:items'
REDIS_ITEMS_SERIALIZER = 'json.dumps'
b. 使用列表保存item数据
4. 起始URL相关
"""
起始URL相关
a. 获取起始URL时,去集合中获取还是去列表中获取?True,集合;False,列表
REDIS_START_URLS_AS_SET = False # 获取起始URL时,如果为True,则使用self.server.spop;如果为False,则使用self.server.lpop
b. 编写爬虫时,起始URL从redis的Key中获取
REDIS_START_URLS_KEY = '%(name)s:start_urls'
"""
# If True, it uses redis' ``spop`` operation. This could be useful if you
# want to avoid duplicates in your start urls list. In this cases, urls must
# be added via ``sadd`` command or you will get a type error from redis.
# REDIS_START_URLS_AS_SET = False
# Default start urls key for RedisSpider and RedisCrawlSpider.
# REDIS_START_URLS_KEY = '%(name)s:start_urls'
#settings示例


# ################################## scrapy redis ################################# REDIS_HOST = '192.168.16.56' # 主机名 REDIS_PORT = 6379 # 端口 # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) # REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) # REDIS_PARAMS['redis_cls'] = 'redis.StrictRedis' # 指定连接Redis的Python模块 默认:redis.StrictRedis REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8' SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) """ 每一个爬虫,都有自己scrapy-redis中的队列,在redis中对应的一个key renjian:requests: ['http://www.baidu.com','http://www.baidu.com','http://www.baidu.com','http://www.baidu.com','http://www.baidu.com','http://www.baidu.com',] jianren:requests: ['http://www.bing.com','http://www.bing.com','http://www.bing.com','http://www.bing.com','http://www.bing.com'] """ SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key """ renjian:dupefilter:{} jianren:dupefilter:{} """ SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 去重规则对应处理的类 # 调度器使用scrapy_redis !!! SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 去重使用 scrapy_redis !!! DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # PIPELINES # ITEM_PIPELINES = { # 'scrapy_redis.pipelines.RedisPipeline': 300, # } # REDIS_ITEMS_KEY = '%(spider)s:items' # REDIS_ITEMS_SERIALIZER = 'json.dumps' # 起始URL REDIS_START_URLS_AS_SET = False REDIS_START_URLS_KEY = '%(name)s:start_urls'
scrapy-redis示例
# DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # # # from scrapy_redis.scheduler import Scheduler # from scrapy_redis.queue import PriorityQueue # SCHEDULER = "scrapy_redis.scheduler.Scheduler" # SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 默认使用优先级队列(默认),其他:PriorityQueue(有序集合),FifoQueue(列表)、LifoQueue(列表) # SCHEDULER_QUEUE_KEY = '%(spider)s:requests' # 调度器中请求存放在redis中的key # SCHEDULER_SERIALIZER = "scrapy_redis.picklecompat" # 对保存到redis中的数据进行序列化,默认使用pickle # SCHEDULER_PERSIST = True # 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空 # SCHEDULER_FLUSH_ON_START = False # 是否在开始之前清空 调度器和去重记录,True=清空,False=不清空 # SCHEDULER_IDLE_BEFORE_CLOSE = 10 # 去调度器中获取数据时,如果为空,最多等待时间(最后没数据,未获取到)。 # SCHEDULER_DUPEFILTER_KEY = '%(spider)s:dupefilter' # 去重规则,在redis中保存时对应的key # SCHEDULER_DUPEFILTER_CLASS = 'scrapy_redis.dupefilter.RFPDupeFilter'# 去重规则对应处理的类 # # # # REDIS_HOST = '10.211.55.13' # 主机名 # REDIS_PORT = 6379 # 端口 # # REDIS_URL = 'redis://user:pass@hostname:9001' # 连接URL(优先于以上配置) # # REDIS_PARAMS = {} # Redis连接参数 默认:REDIS_PARAMS = {'socket_timeout': 30,'socket_connect_timeout': 30,'retry_on_timeout': True,'encoding': REDIS_ENCODING,}) # # REDIS_PARAMS['redis_cls'] = 'myproject.RedisClient' # 指定连接Redis的Python模块 默认:redis.StrictRedis # REDIS_ENCODING = "utf-8" # redis编码类型 默认:'utf-8'
import scrapy class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = ( 'http://www.chouti.com/', ) def parse(self, response): for i in range(0,10): yield