 一,初识文件操作
一,初识文件操作
使用python来读写文件是一个非常简单的操作,我们使用open()函数来打开一个文件,获取文件的句柄,然后通过句柄就可以进行各种各样的操作了.根据打开的方式不同能够执行操作也会有相应的差异.
打开方式: r,w,a,r+,w+,a+,rb,wb,ab,r+b,w+b,a+b 默认使用的是r(只读模式)
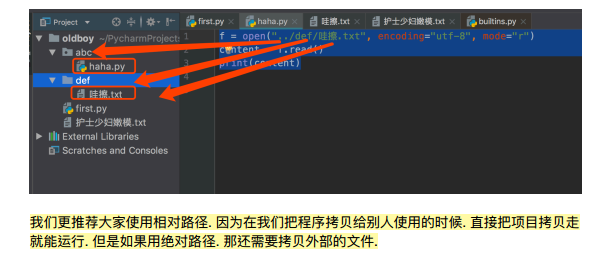
二,文件路径
文件路径 open('文件路径',mode = '模式' , encoding = "路径")
文件路径
1. 绝对路径,从磁盘的根目录寻找 或者 从互联网上寻找一个路径
2. 相对路径(用的多). 相对于当前程序所在的文件夹 ../上一层文件夹
read 读
f = open("哈哈哈哈哈", mode="r", encoding="UTF-8") s = f.read() print(s) f.close() # 如果没有这句话, 你在下面的程序中如果删除这个文件. 就会报错
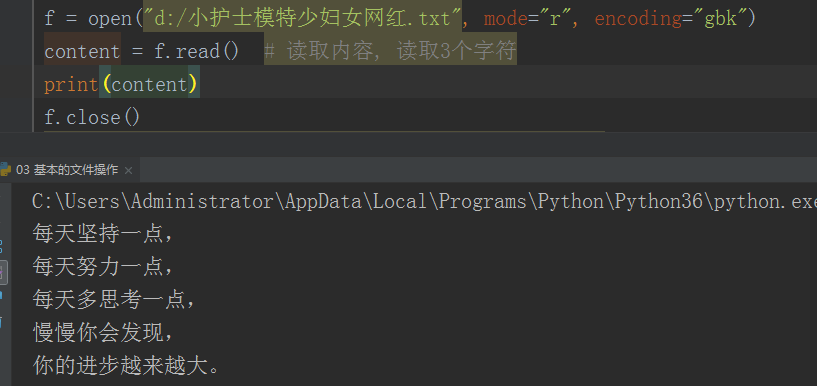
f = open("d:/小护士模特少妇女网红.txt", mode="r", encoding="gbk") line1 = f.readline().strip() # 空白: 空格, , line2 = f.readline().strip() print(line1) print(line2) f.close()
f = open("d:/小护士模特少妇女网红.txt", mode="r", encoding="gbk")
content = f.readlines() # 也是全都加载进来了.
print(content)
结果:['每天坚持一点,
', '每天努力一点,
', '每天多思考一点,
', '慢慢你会发现,
', '你的进步越来越大。
']
.read()一次性全部读出来 缺点:1,读取的大的文件的时候内存容易溢出 2,操作起来比较麻烦
如果read()里面填值的话就是读取内容,读取的是字符
.readliens()也是全部加载进来了,不过是列表的格式
里面读取值的话也是读取这个行的内容,读取的也是字符
*************这个是必须会写的*********************************
# f是一个可迭代对象 f = open("d:/周润发大战奥特曼.txt", mode="r", encoding="gbk") # 默认跟着操作系统走的 GBK for line in f: # 内部其实调用的是readline() print(line.strip()) f.close() # 关闭

因为如果直接读取.readline()这样一句句打印的话,会出现一个问题,就是会打印多了一个
你可以用刚才演示的办法.strip()去除文件里面的空白
或者你也可以把print的默认值end= " "改成空格或者"*"
ps:当你打开这个文件的时候,一定要养成好的习惯f.close()一下,就相当于医生做一台手术,光手术了,没有缝合,你就可以出去了,所以一定要.close()一下
wirte写
f = open("d:/sylar.txt", mode="w", encoding="utf-8")
f.write("周笔畅
") # 写的时候. 先清空. 再写入. w
f.write("胡辣汤
")
f.write("实付款
")
f.flush()#刷新
f.close()#关闭
当你写完文件的时候,一定要.flush()一下,刷新一下,这个添加的话是覆盖添加,就是之前写的文档东西都没有了,更新了一个新的文件夹,这个就是wirte不是一样的
append 追加写
f = open("d:/sylar.txt", mode="a", encoding="utf-8") f.write("娃哈哈") # 追加写 f.write("爽歪歪") f.flush() f.close()
这个就是追加写,和上面的write不一样,是在后面追加写的,但是和write一样一定要更新和关闭
b------------文件拷贝
首先你要了解b模式的话,你就应该要了解什么是b是什么,b是bit
ascll码 只包含英文,数字,特殊字符
gbk 都是两个字节
万国码 Unicode 32bit 4个字节 可以兼容各个国家的文字,因为很浪费空间,所以进行改编
utf-8 可变长度的Unicode 英文是1个字节 欧洲文字占用两个字节 中国文字是占用三个字节
一个字节(byte)是8位(bit)
所以b模式的话就是操作非文本文件的时候就用带b的,所以图形压缩包mp3 等等的都是带b的,他拷贝的是/x../系列的东西
rb读取文件的bit
f1 = open("d:/sylar.txt",mode="rb") for line in f1 : print(line)
wb拷贝
f1 = open("d:/sylar.txt",mode= "rb") f2 = open("f:/哈哈.txt",mode="wb") for line in f1 : f2.write(f1) f1.close() f2.flush() f2.close()
ab追加以字节的形式往里面添加东西(但是不可以读所以不建议使用)若要用的话,a+b最合适了尤其是做断点续传的时候
***************************这个是必须会写的*********************************
r+读写(唯一一个和光标无关的添加,在后面添加的)
f = open("菜单", mode="r+", encoding="utf-8") # r+最常见 s = f.read(1) # 读取一个字符 print(s) f.write("胡辣汤") # r+模式. 如果你执行读了操作. 那么写操作的时候. 都是写在文件的末尾. 和光标没有关系 # f.write("ab") # 在文件开头写入. 写入的是字节,把原来的内容盖上 # for line in f: # print(line) # f.write("蛋炒饭") # 正确用法: 先读后写 f.close()
w+ 写读
f = open("菜单", mode="w+", encoding="utf-8") # 很少用. f.write("疙瘩汤") f.seek(0) # 移动到开头 content = f.read() print("读取的内容是", content) f.flush() f.close()
a+ 追加写
f = open("菜单", mode="a+", encoding="utf-8") f.write("韭菜鸡蛋饺子") f.seek(0) content = f.read() print(content)
这样的话因为光标在后面所以可能会读出来,所以需要吧光标移动到第一个字符
其他相关操作:
1. seek(n) 光标移动到n位置, 注意, 移动的单位是byte. 所以如果是UTF-8的中部分要
是3的倍数.
通常我们使用seek都是移动到开头或者结尾.
移动到开头: seek(0)
移动到结尾: seek(0,2) seek的第二个参数表⽰的是从哪个位置进行偏移, 默认是0, 表
开头, 1表示当前位置, 2表示结尾
f = open ("小娃娃",mode = "r+",encoding = "utf-8") f.seek(0) #光标移动到0 countent = f .read()#读取内容,此时光标移动到结尾 print(count) f.seek(0) #再次将光标移动到开头 f.seek(0,2)将光标移动到结尾 count2 = f.read()#读取内容 什么都没有 print (count2) f.seek(0) #移动到开头 f.write("张国荣") #写入信息,此时光标在9 (中文3*3个=9) f.flush() f.close()
2.tell()使用可以帮我们获取到当前光标的位置
f = open("小娃娃",mode = "r+",encoding = "uft-8") f.seek(0) #光标移动到开头 content = f.read()#获取内容,此时光标移动到结尾 print(content) f.seek(0) #再次将光标移动到开头 f.seek (0,2) #将光标移动到结尾 content2 = f.read()#读取内容 什么都没有 print(content2) f.seek(0) #再次移动到了开头 f.write("麻花藤") #写入信息,此时光标在9 print(f.tell) #获取光标位置9 f.flush() f.close()
3.truncate()截断文件
f = open("小娃娃",mode = "w",encoding = "utf-8") f.write('哈哈") #写入两个字符 f.seek(3) 光标移动到3也就是两个字中间的位置 f.truncate() #删除光标后面的所有内容 f.close() f = open("小娃娃",mode = "r+",encoding = "utf-8") content = f.read(3) #读取12个字符 s.seek(4) print(f.tell()) f.truncate() #后面的内容都删除 f.flush() f.close()
f = open("小娃娃",mode = "w",encoding = "utf-8") f.write('哈哈") #写入两个字符 f.seek(3) 光标移动到3也就是两个字中间的位置 f.truncate() #删除光标后面的所有内容 f.close() f = open("小娃娃",mode = "r+",encoding = "utf-8") content = f.read(3) #读取12个字节 s.seek(4) print(f.tell()) f.truncate() #后面的内容都删除 f.flush() f.close()
深坑:在r+模式下,如果读取了内容,不论读取内容多少,光标显示是多少,在写入或者操作文件的时候都是在结尾进行操作.
所以如果想做接到操作,记住要先挪动光标,挪动到 你想要截断的位置,然后再进行截断,关于truncate(n) 如果给出了n,则开头进行截断如果不给,则从当前位置截断,后面的内容将会被删除.
***************************这个是必须会写的*********************************
修改文件以及另一种打开文件的方式
文件修改:只能将文件中的内容读取到内存中,将信息修改完毕,然后将源文件删除,将新文件的名字改成老文件的名字.
import os with open("小娃娃",mode = "r",endcoding = "utf-8")as f1, open("小娃娃",mode = "w",encoding = "ttf-8")as f2 : content = f1.read() new_countend = content.replace("冰糖葫芦","大白梨") f2.write(new_content) os.remove("小娃娃") #删除源文件 os.rename("小娃娃new","小娃娃") #重命名新文件 弊端:一次将所有的内容读取出来,内存溢出. 解决方法:一行一行的读取和操作
import os with open("小娃娃",mode = "r",endcoding = "utf-8")as f1, open("小娃娃",mode = "w",encoding = "ttf-8")as f2 : for line in f1 : new_countend = content.replace("冰糖葫芦","大白梨") f2.write(new_content) os.remove("小娃娃") #删除源文件 os.rename("小娃娃new","小娃娃") #重命名新文件
代码练习:
# 2,写函数,检查获取传入列表或元组对象的所有奇数位索引对应的元素,并将其作为新列表返回给调用者。 def func(lst): # function # return lst[1::2] result = [] for i in range(len(lst)): if i % 2 == 1: result.append(lst[i]) return result # 3, 写函数,判断用户传入的对象(字符串、列表、元组)长度是否大于5 def func(obj): # if len(obj) > 5: # return True # else: # return False return len(obj) > 5 # 4, 写函数,检查传入列表的长度,如果大于2,将列表的前两项内容返回给调用者 def func(lst): if len(lst) > 2: return lst[:2] # 5, 写函数,计算传入函数的字符串中, 数字、字母、空格 以及 其他内容的个数,并返回结果 isalpha() def func(s=""): shuzi = 0 zimu = 0 kongge = 0 qita = 0 for c in s: if c.isalpha(): zimu = zimu + 1 elif c.isdigit(): shuzi = shuzi + 1 elif c.isspace(): kongge = kongge + 1 else: qita = qita + 1 return shuzi, zimu, kongge, qita print(func("abcd1234@@@@ ")) # 6,写函数,接收两个数字参数,返回比较大的那个数字。 def func(a, b): # if a > b: # return a # else: # return b return a if a > b else b # 三目运算 # a = 100 # b = 20 # c = a if a > b else b print(c) # 7, 写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。 dic = {"k1": "v1v1", "k2": [11,22,33,44]} # PS:字典中的value只能是字符串或列表 def func(dic): for k, v in dic.items(): if len(v) > 2: v = v[:2] dic[k] = v return dic # 8, 8,写函数,此函数只接收一个参数且此参数必须是列表数据类型, # 此函数完成的功能是返回给调用者一个字典, # 此字典的键值对为此列表的索引及对应的元素。 # 例如传入的列表为:[11,22,33] 返回的字典为 {0:11,1:22,2:33}。 def func(lst): if type(lst) != list: print("扔出去一个异常") dic = {} for i in range(len(lst)): dic[i] = lst[i] return dic # 写函数,函数接收四个参数分别是:姓名,性别,年龄,学历。用户通过输入这四个内容, # 然后将这四个内容传入到函数中,此函数接收到这四个内容, # 将内容追加到一个student_msg文件中 def func(name, age, edu, gender="男"): f = open("student_msg", mode="a", encoding="utf-8") f.write(name+"_"+gender+"_"+age+"_"+edu+" ") f.flush() f.close() func("郑中基", "男", "50", "大本") func("张学友", "男", "60", "大本") while 1: tiwen = input("请问是否要输入学生信息输入任意内容继续,输入Q退出:") if tiwen.upper() == 'Q': break name = input("请输入你的姓名:") gender = input("请输入你的性别:") age = input("请输入你的年龄:") edu = input("请输入你的学历:") # gender = "男" if gender == "" else "女" func(name, age, edu, gender) # 11 写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作(升级题)。 import os def func(file_name, old, new): with open(file_name, mode="r", encoding="utf-8") as f1, open(file_name+"_副本", mode="w", encoding="utf-8") as f2: for line in f1: line = line.replace(old, new) f2.write(line) os.remove(file_name) os.rename(file_name+"_副本", file_name) # 12. 写一个函数完成三次登陆功能,再写一个函数完成注册功能. 用户信息写入到文件中 # def regist(username, password): # wusir # 1. 检查用户名是否重复 f = open("user_info", mode="r+", encoding="utf-8") for line in f: if line == "": # 防止空行影响程序运行 continue user_info_username = line.split("_")[0] if username == user_info_username: # 用户名重复了 return False else: # 2. 写入到文件中 f.write(username+"_"+password+" ") f.flush() f.close() return True name, psw = input("请输入你的用户名:"), input("请输入你的密码:") print(regist(name, psw)) def login(username, password): f = open("user_info", mode="r", encoding="UTF-8") for line in f: if line.strip() == username+"_"+password: f.close() return True else: f.close() return False for i in range(2, -1, -1): ret = login(input("请输入用户名:"), input("请输入密码:")) if ret: print("恭喜你. 登录成功") break else: print("用户名或密码错误, 还有%s次机会" % i)