数据约束
1.1 默认值
CREATE TABLE student(
id INT,
NAME VARCHAR(20),
address VARCHAR(20) DEFAULT '广州天河' -- 默认值
);
DROP TABLE student;
-- 当字段没有插入值的时候,mysql自动给该字段分配默认值
INSERT INTO student(id,NAME) VALUES(1,'张三');
-- 注意:默认值的字段允许为null或其他非默认值的值
INSERT INTO student(id,NAME,address) VALUE(2,'李四',NULL);
INSERT INTO student(id,NAME,address) VALUE(3,'王五','广州番禺');
1.2 非空
-- 需求: gender字段必须有值(不为null)
DROP TABLE student;
CREATE TABLE student(
id INT,
NAME VARCHAR(20),
gender VARCHAR(2) NOT NULL -- 非空
);
-- 非空字段必须赋值(如果使用mysql的话会将非空字段默认赋值为一个空字符串)
INSERT INTO student(id,NAME) VALUES(1,'李四');
-- 非空字段不可以插入NULL;
INSERT INTO student(id,NAME,gender) VALUES(1,'李四',NULL);
1.3 唯一
作用: 对字段的值不能重复
注意:
1)唯一字段可以插入null
2)唯一字段可以插入多个null
CREATE TABLE student(
id INT UNIQUE, -- 唯一
NAME VARCHAR(20)
);
INSERT INTO student(id,NAME) VALUES(1,'zs');
INSERT INTO student(id,NAME) VALUES(1,'lisi'); -- ERROR 1062 (23000): Duplicate entry '1' for key 'id'
INSERT INTO student(id,NAME) VALUES(2,'lisi');
1.4 主键(非空+唯一)
作用: 非空+唯一
注意:
1)通常情况下,每张表都会设置一个主键字段。用于标记表中的每条记录的唯一性。
2)建议不要选择表的包含业务含义的字段作为主键,建议给每张表独立设计一个非业务含义的 id字段。
DROP TABLE student;
CREATE TABLE student(
id INT PRIMARY KEY, -- 主键
NAME VARCHAR(20)
);
INSERT INTO student(id,NAME) VALUES(1,'张三');
INSERT INTO student(id,NAME) VALUES(2,'张三');
-- INSERT INTO student(id,NAME) VALUES(1,'李四'); -- 违反唯一约束: Duplicate entry '1' for key 'PRIMARY'
-- insert into student(name) value('李四'); -- 违反非空约束: ERROR 1048 (23000): Column 'id' cannot be null
1.5 自增长
CREATE TABLE student(
id INT(4) ZEROFILL PRIMARY KEY AUTO_INCREMENT, -- 自增长,从0开始; ZEROFILL将4位数补充0,如0001
NAME VARCHAR(20)
);
-- 自增长字段可以不赋值,自动递增
INSERT INTO student(NAME) VALUES('张三');
INSERT INTO student(NAME) VALUES('李四');
INSERT INTO student(NAME) VALUES('王五');
SELECT * FROM student;
-- 不能影响自增长约束
DELETE FROM student;
-- 可以影响自增长约束
TRUNCATE TABLE student;
1.6 外键约束
作用:约束两种表的数据
出现两种表的情况:
解决数据冗余高问题: 独立出一张表
例如: 员工表 和 部门表
问题出现:
比如,现在部门表只有三个部门,那么在插入员工表数据的时候,员工表的部门ID字段就不可以插入比部门表的数量多!!!!!
使用外键约束:约束插入员工表的部门ID字段值
解决办法: 在员工表的部门ID字段添加一个外键约束
注意:
1)被约束的表称为副表,约束别人的表称为主表,外键设置在副表上的!!!
2)主表的参考字段通用为主键!
3)添加数据: 先添加主表,再添加副表
4)修改数据: 先修改副表,再修改主表
5)删除数据: 先删除副表,再删除主表
当有了外键约束的时候,必须先修改或删除副表中的所有关联数据,才能修改或删除主表!但是,我们希望直接修改或删除主表数据,从而影响副表数据。可以使用级联操作实现!!!
级联修改: ON UPDATE CASCADE
级联删除: ON DELETE CASCADE
设计原则: 建议设计的表尽量遵守三大范式。
第一范式: 要求表的每个字段必须是不可分割的独立单元
student : name -- 违反第一范式
张小名|狗娃
sutdent : name old_name --符合第一范式
张小名 狗娃
第二范式: 在第一范式的基础上,要求每张表只表达一个意思。表的每个字段都和表的主键有依赖。
employee(员工): 员工编号 员工姓名 部门名称 订单名称 --违反第二范式
员工表:员工编号 员工姓名 部门名称
订单表: 订单编号 订单名称 -- 符合第二范式
第三范式: 在第二范式基础,要求每张表的主键之外的其他字段都只能和主键有直接决定依赖关系。
员工表: 员工编号(主键) 员工姓名 部门编号 部门名 --符合第二范式,违反第三范式 (数据冗余高)
员工表:员工编号(主键) 员工姓名 部门编号 --符合第三范式(降低数据冗余)
部门表:部门编号 部门名
关联查询(多表查询)
数据库准备:
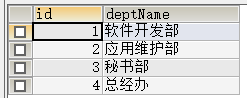
create table `dept` (
`id` double ,
`deptName` varchar (60)
);
insert into `dept` (`id`, `deptName`) values('1','软件开发部');
insert into `dept` (`id`, `deptName`) values('2','应用维护部');
insert into `dept` (`id`, `deptName`) values('3','秘书部');
insert into `dept` (`id`, `deptName`) values('4','总经办');
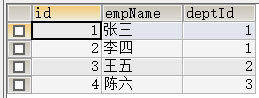
create table `employee` (
`id` double ,
`empName` varchar (60),
`deptId` double
);
insert into `employee` (`id`, `empName`, `deptId`) values('1','张三','1');
insert into `employee` (`id`, `empName`, `deptId`) values('2','李四','1');
insert into `employee` (`id`, `empName`, `deptId`) values('3','王五','2');
insert into `employee` (`id`, `empName`, `deptId`) values('4','陈六','3');
**************二、关联查询(多表查询)****************-
需求:查询员工及其所在部门(显示员工姓名,部门名称)
2.1 交叉连接查询(不推荐。产生笛卡尔乘积现象:4 * 4=16,有些是重复记录)
SELECT empName,deptName FROM employee,dept;
--需求:查询员工及其所在部门(显示员工姓名,部门名称)
-- 多表查询规则:1)确定查询哪些表 2)确定哪些哪些字段 3)表与表之间连接条件 (规律:连接条件数量是表数量-1)
2.2 内连接查询:只有满足条件的结果才会显示(使用最频繁)
SELECT empName,deptName -- 2)确定哪些哪些字段
FROM employee,dept -- 1)确定查询哪些表
WHERE employee.deptId=dept.id -- 3)表与表之间连接条件
--内连接的另一种语法
SELECT empName,deptName
FROM employee INNER JOIN dept
ON employee.deptId=dept.id;
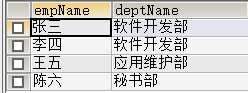
-- 使用别名
SELECT e.empName,d.deptName
FROM employee e
INNER JOIN dept d
ON e.deptId=d.id;
结果:
需求: 查询每个部门的员工
预期结果:
-- 软件开发部 张三
-- 软件开发部 李四
-- 应用维护部 王五
-- 秘书部 陈六
-- 总经办 null
2.2 左[外]连接查询: 使用左边表的数据去匹配右边表的数据,如果符合连接条件的结果则显示,如果不符合连接条件则显示null
-- (注意:左外连接:左表的数据一定会完成显示!)
SELECT d.deptName,e.empName
FROM dept d
LEFT OUTER JOIN employee e
ON d.id=e.deptId;
2.3 右[外]连接查询: 使用右边表的数据去匹配左边表的数据,如果符合连接条件的结果则显示,如果不符合连接条件则显示null
-- (注意:右外连接:右表的数据一定会完成显示!)
SELECT d.deptName,e.empName
FROM employee e
RIGHT OUTER JOIN dept d
ON d.id=e.deptId;
结果: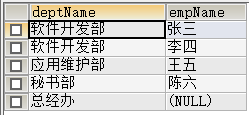
2.4 自连接查询
-- 需求:查询员工及其上司
-- 预期结果:
-- 张三 null
-- 李四 张三
-- 王五 李四
-- 陈六 王五
SELECT e.empName,b.empName
FROM employee e
LEFT OUTER JOIN employee b
ON e.bossId=b.id;
存储过程
5.1 什么是存储过程
存储过程,带有逻辑的sql语句
之前的sql没有条件判断,没有循环
存储过程带上流程控制语句(if while)
5.2 存储过程特点
1)执行效率非常快!存储过程是在数据库的服务器端执行的!!!
2)移植性很差!不同数据库的存储过程是不能移植。
5.3 存储过程语法
-- 创建存储过程
DELIMITER $ -- 声明存储过程的结束符
CREATE PROCEDURE pro_test() --存储过程名称(参数列表)
BEGIN -- 开始
-- 可以写多个sql语句; -- sql语句+流程控制
SELECT * FROM employee;
END $ -- 结束 结束符
-- 执行存储过程
CALL pro_test(); -- CALL 存储过程名称(参数);
参数:
IN: 表示输入参数,可以携带数据带存储过程中
OUT: 表示输出参数,可以从存储过程中返回结果
INOUT: 表示输入输出参数,既可以输入功能,也可以输出功能
-- **************三、存储过程*******************-
-- 声明结束符
-- 创建存储过程
DELIMITER $
CREATE PROCEDURE pro_test()
BEGIN
-- 可以写多个sql语句;
SELECT * FROM employee;
END $
-- 执行存储过程
CALL pro_test();
-- 3.1 带有输入参数的存储过程
-- 需求:传入一个员工的id,查询员工信息
DELIMITER $
CREATE PROCEDURE pro_findById(IN eid INT) -- IN: 输入参数
BEGIN
SELECT * FROM employee WHERE id=eid;
END $
-- 调用
CALL pro_findById(4);
-- 3.2 带有输出参数的存储过程
DELIMITER $
CREATE PROCEDURE pro_testOut(OUT str VARCHAR(20)) -- OUT:输出参数
BEGIN
-- 给参数赋值
SET str='helljava';
END $
-- 删除存储过程
DROP PROCEDURE pro_testOut;
-- 调用
-- 如何接受返回参数的值??
-- ***mysql的变量******
-- 全局变量(内置变量):mysql数据库内置的变量 (所有连接都起作用)
-- 查看所有全局变量: show variables
-- 查看某个全局变量: select @@变量名
-- 修改全局变量: set 变量名=新值
-- character_set_client: mysql服务器的接收数据的编码
-- character_set_results:mysql服务器输出数据的编码
-- 会话变量: 只存在于当前客户端与数据库服务器端的一次连接当中。如果连接断开,那么会话变量全部丢失!
-- 定义会话变量: set @变量=值
-- 查看会话变量: select @变量
-- 局部变量: 在存储过程中使用的变量就叫局部变量。只要存储过程执行完毕,局部变量就丢失!!
-- 1)定义一个会话变量name, 2)使用name会话变量接收存储过程的返回值
CALL pro_testOut(@NAME);
-- 查看变量值
SELECT @NAME;
-- 3.3 带有输入输出参数的存储过程
DELIMITER $
CREATE PROCEDURE pro_testInOut(INOUT n INT) -- INOUT: 输入输出参数
BEGIN
-- 查看变量
SELECT n;
SET n =500;
END $
-- 调用
SET @n=10;
CALL pro_testInOut(@n);
SELECT @n;
-- 3.4 带有条件判断的存储过程
-- 需求:输入一个整数,如果1,则返回“星期一”,如果2,返回“星期二”,如果3,返回“星期三”。其他数字,返回“错误输入”;
DELIMITER $
CREATE PROCEDURE pro_testIf(IN num INT,OUT str VARCHAR(20))
BEGIN
IF num=1 THEN
SET str='星期一';
ELSEIF num=2 THEN
SET str='星期二';
ELSEIF num=3 THEN
SET str='星期三';
ELSE
SET str='输入错误';
END IF;
END $
CALL pro_testIf(4,@str);
SELECT @str;
-- 3.5 带有循环功能的存储过程
-- 需求: 输入一个整数,求和。例如,输入100,统计1-100的和
DELIMITER $
CREATE PROCEDURE pro_testWhile(IN num INT,OUT result INT)
BEGIN
-- 定义一个局部变量
DECLARE i INT DEFAULT 1;
DECLARE vsum INT DEFAULT 0;
WHILE i<=num DO
SET vsum = vsum+i;
SET i=i+1;
END WHILE;
SET result=vsum;
END $
DROP PROCEDURE pro_testWhile;
CALL pro_testWhile(100,@result);
SELECT @result;
USE day16;
6.1 触发器作用
当操作了某张表时,希望同时触发一些动作/行为,可以使用触发器完成!!
例如: 当向员工表插入一条记录时,希望同时往日志表插入数据
-- 需求: 当向员工表插入一条记录时,希望mysql自动同时往日志表插入数据
-- 创建触发器(添加)
CREATE TRIGGER tri_empAdd AFTER INSERT ON employee FOR EACH ROW -- 当往员工表插入一条记录时
INSERT INTO test_log(content) VALUES('员工表插入了一条记录');
-- 插入数据
INSERT INTO employee(id,empName,deptId) VALUES(7,'扎古斯',1);
INSERT INTO employee(id,empName,deptId) VALUES(8,'扎古斯2',1);
-- 创建触发器(修改)
CREATE TRIGGER tri_empUpd AFTER UPDATE ON employee FOR EACH ROW -- 当往员工表修改一条记录时
INSERT INTO test_log(content) VALUES('员工表修改了一条记录');
-- 修改
UPDATE employee SET empName='eric' WHERE id=7;
-- 创建触发器(删除)
CREATE TRIGGER tri_empDel AFTER DELETE ON employee FOR EACH ROW -- 当往员工表删除一条记录时
INSERT INTO test_log(content) VALUES('员工表删除了一条记录');
-- 删除
DELETE FROM employee WHERE id=7;
7 mysql权限问题
-- ***********五、mysql权限问题****************
-- mysql数据库权限问题:root :拥有所有权限(可以干任何事情)
-- 权限账户,只拥有部分权限(CURD)例如,只能操作某个数据库的某张表
-- 如何修改mysql的用户密码?
-- password: md5加密函数(单向加密)
SELECT PASSWORD('root'); -- *81F5E21E35407D884A6CD4A731AEBFB6AF209E1B
-- mysql数据库,用户配置 : user表
USE mysql;
SELECT * FROM USER;
-- 修改密码
UPDATE USER SET PASSWORD=PASSWORD('123456') WHERE USER='root';
-- 分配权限账户
GRANT SELECT ON day16.employee TO 'eric'@'localhost' IDENTIFIED BY '123456';
GRANT DELETE ON day16.employee TO 'eric'@'localhost' IDENTIFIED BY '123456';