作业要求参见 https://edu.cnblogs.com/campus/nenu/2018fall/homework/2126
Git:https://git.coding.net/zhaomeizeng/wc.git
一.功能实现
功能一
(1) 首先对文件的处理需要先输入,利用open函数逐行读取文件内容,本次使用只用了两个参数,文件名和读取方式,open(filename,’r’)
infile = open(filename,'r')
(2) 难点:未用punctuation之前出现过去除符号不全的现象 分词,open读取是多行的所以利用for对每行操作,行操作:分词,通过调用punctuation和line共同判断标点是否在行中,有则用空格替换用replace()方法,因为分词的方法spilte()通过空格分词。
def replaces(line): for ch in line: if ch in punctuation: line = line.replace(ch, " ") return line
(3)重点:需要理清头绪细致掌握,
对处理好的每行进行操作:字典的键值对属性十分使用这种统计,所以创建字典在for对每行(列表)的统计中for每个单词,存入字典。
对字典的操作:首先计算total,重复计算的可以统计键的个数,非重复的可以各个值相加;统计是个最多的次,利用sort函数,需要先将字典转化为列表list(word_counts.items()),此列表也是成对存在,但是名在前,数在后,需要先反转数对[x,y] for [y,x] in pairs,然后sort()依据x进行从小到大的排列,所以输出是就要从后往前输出。
def countLine(line, word_Counts): # 用空格替换标点符号,避免造成乱码导致错误 line = replaces(line) '''使用函数替换标点,使用自定义函数''' words = line.split() '''以空格分割成单词''' for word in words: if word in word_Counts: word_Counts[word] += 1 else: word_Counts[word] = 1
items = [[x, y] for (y, x) in pairs] items.sort()
结果
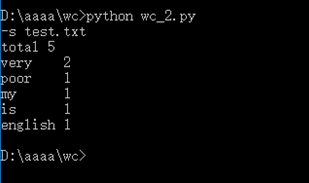
***在看到老师的指导要求后尝试转换成.exe文件,但是遭遇错误。查询后得知可能是pyinstaller 目前可能不支持我所用的python3.7,
所以没有调试成功,正在加紧调试,为不晚交作业只能先以现代码为基础完成作业。
功能二
难点:对于文件的操作这是第一次实现还是比较有难度的,从os到open学了很长时间。
相比功能一改动的是total的统计,从遍历字典的键变成遍历字典的values并累积相加。
infile = open(filename, 'r') # 以只读方式打开文件,r表模式 total = 0 words = [] data = [] '''建立列表''' # 建立用于计算词频的空字典 word_Counts = {} for line in infile: countLine(line.lower(), word_Counts) # 这里line.lower()的作用是将大写替换成小写,方便统计词频 # 从字典中获取数据对,转换为列表,会变成【(a,1),(b,2)]形式,括号内分别为0,1 for value in word_Counts.values(): total = total + value pairs = list(word_Counts.items()) # # 列表中的数据对交换位置,数据对排序 items = [[x, y] for (y, x) in pairs] items.sort() # 因为sort()函数是从小到大排列,所以range是从最后一项开始取 #total = len(pairs) print("total " + str(total)) # 此for统计总数,通过访问各键的值 if len(items) - 11 <0: lenth = -1 else: lenth = len(items) -11 for i in range(len(items) - 1,lenth, -1): # range函数(start,stop,step) print(items[i][1] + " " + str(items[i][0])) # 对数值对样式的列表处理 data.append(items[i][0]) words.append(items[i][1])
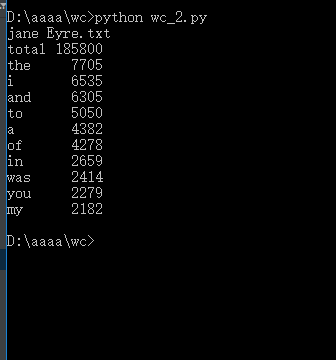
功能三
(1) 难点在于目录下文件的读取。
通过os对目录进行读取,将文件置于一个列表下,再依次执行,因为没有将文件转换成.exe,所以需要指定文件的绝对路径,由输入的dir和自行读取的文件名组成,利用os的jion函数。其余的就是对于功能讷讷个二统计一个文件的功能调用。
path = input() dirs = os.listdir(path) # 输出所有文件和文件夹 for filename in dirs: print(filename) filename = os.path.join(path, filename) mains(filename)
结果
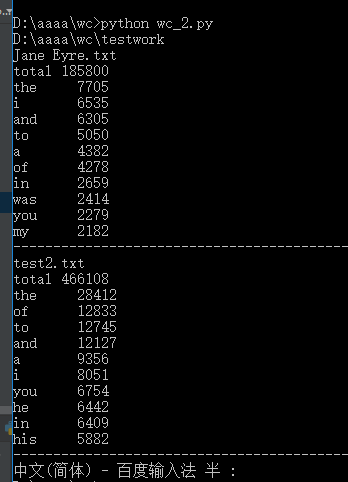
功能四
对于功能四查询学习良久还是不能理解学会,没有实现。
二.psp
实现与测试psp
|
阶段 |
预计时间 |
实际时间 |
原因 |
|
功能一 |
120 |
244 |
在做分析时以为使用python强大的函数可以轻松实现,但上手才知道并非如此,语言掌握不牢,函数不熟悉,只能边学边写 |
|
测试功能一 |
30 |
15 |
没有框架,边学边写,错误太多了 |
|
功能二 |
60 |
77 |
以功能一为蓝本 |
|
测试功能二 |
30 |
25 |
比较顺利,没崩溃 |
|
功能三 |
30 |
167 |
以为目录操作比较简单,但是遇到地址问题,查了好久 |
|
测试功能三 |
30 |
15 |
比较顺利,没崩溃 |
|
功能四 |
120 |
至今 |
没学明白这是什么,只是写了个统计输入的字段的程序,并不符合要求 |
确实遇到了很多的困难吧,从硬件到程序,真正认识到自己学的还是 太差了,对各种函数的运用根本不熟练,还要边写边写。
然后还有不少意外,编程环境崩了两次,自己都意想不到,以后还是要好好使用电脑多多清理垃圾,整理文件。
全程被蹂躏,最后也没实现好。
指导自己的实践能力差,这次也是见识到有多差了。