1. 深入理解感受野
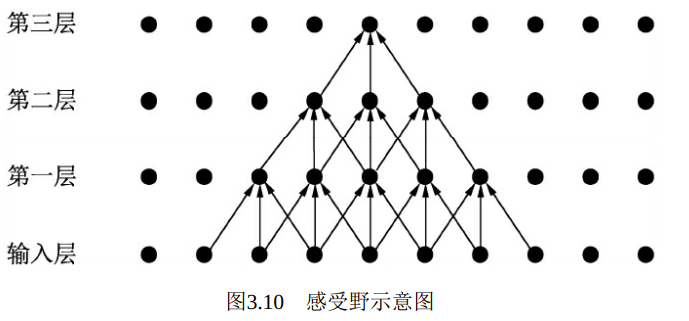
感受野(Receptive Field) 是指特征图上的某个点能看到的输入图像的区域, 即特征图上的点是由输入图像中感受野大小区域的计算得到的。 举个简单的例子, 如图3.10所示为一个三层卷积网络, 每一层的卷积核为3×3, 步长为1, 可以看到第一层对应的感受野是3×3, 第二层是5×5, 第三层则是7×7。
卷积层和池化层都会影响感受野, 而激活函数层通常对于感受野没有影响。 对于一般的卷积神经网络, 感受野可式(3-9) 和式(3-10)计算得出。

其中, RFl+1与RFl分别代表第l+1层与第l层的感受野, k代表第l+1层卷积核的大小, Sl代表前l层的步长之积。 注意, 当前层的步长并不影响当前层的感受野。
通过上述公式求取出的感受野通常很大, 而实际的有效感受野(Effective Receptive Field) 往往小于理论感受野。 从图3.10也可以看出, 虽然第三层的感受野是7×7, 但是输入层中边缘点的使用次数明显比中间点要少, 因此做出的贡献不同。 经过多层的卷积堆叠之后, 输入层对于特征图点做出的贡献分布呈高斯分布形状。
理解感受野是理解卷积神经网络工作的基础, 尤其是对于使用Anchor作为强先验区域的物体检测算法, 如Faster RCNN和SSD, 如何设置Anchor的大小, Anchor应该对应在特征图的哪一层, 都应当考虑感
受野。 通常来讲, Anchor的大小应该与感受野相匹配, 尤其是有效的感受野, 过大或过小都不好。
在卷积网络中, 有时还需要计算特征图的大小, 一般可以按照式(3-11) 进行计算 。

其中, nin与nout分别为输入特征图与输出特征图的尺寸, p代表这一层的padding大小, k代表这一层的卷积核大小, s为步长 。
2. 详解空洞卷积(Dilated Convolution)
空洞卷积最初是为解决图像分割的问题而提出的。 常见的图像分割算法通常使用池化层来增大感受野, 同时也缩小了特征图尺寸, 然后再利用上采样还原图像尺寸。 特征图缩小再放大的过程造成了精度上的损失, 因此需要有一种操作可以在增加感受野的同时保持特征图的尺寸不变, 从而替代池化与上采样操作, 在这种需求下, 空洞卷积就诞生了。
在近几年的物体检测发展中, 空洞卷积也发挥了重要的作用。 因为虽然物体检测不要求逐像素地检测, 但是保持特征图的尺寸较大, 对于小物体的检测及物体的定位来说也是至关重要的。
空洞卷积, 顾名思义就是卷积核中间带有一些洞, 跳过一些元素进行卷积。 在此以3×3卷积为例, 其中, 图3.11a是普通的卷积过程, 在卷积核紧密排列在特征图上滑动计算, 而图3.11b代表了空洞数为2的空洞卷积, 可以看到, 在特征图上每2行或者2列选取元素与卷积核卷积。 类似地, 图3.11c代表了空洞数为3的空洞卷积。 
在代码实现时, 空洞卷积有一个额外的超参数dilation rate, 表示空洞数, 普通卷积dilation rate默认为1, 图3.11中的b与c的dilation rate分别为2与3。
在图3.11中, 同样的一个3×3卷积, 却可以起到5×5、 7×7等卷积的效果。 可以看出, 空洞卷积在不增加参数量的前提下, 增大了感受野。假设空洞卷积的卷积核大小为k, 空洞数为d, 则其等效卷积核大小k'计算如式(3-12) 所示。

在计算感受野时, 只需要将原来的卷积核大小k更换为k'即可。
空洞卷积的优点显而易见, 在不引入额外参数的前提下可以任意扩大感受野, 同时保持特征图的分辨率不变。 这一点在分割与检测任务中十分有用, 感受野的扩大可以检测大物体, 而特征图分辨率不变使得物体定位更加精准。
PyTorch对于空洞卷积也提供了方便的实现接口, 在卷积时传入dilation参数即可。 具体如下:


1 import torch 2 from torch import nn 3 # 定义普通卷积, 默认dilation为1 4 conv1 = nn.Conv2d(3, 256, 3, stride=1, padding=1, dilation=1) 5 print(conv1) 6 >> conv2d(3, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) 7 8 # 定义普通卷积, 默认dilation为1 9 conv2 = nn.Conv2d(3, 256, 3,stride=1, padding=1, dilation=2) 10 print(conv2) 11 >> Conv2d(3, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), dilation=(2, 2))
当然, 空洞卷积也有自己的一些缺陷, 主要表现在以下3个方面:
·网格效应(Gridding Effect) : 由于空洞卷积是一种稀疏的采样方式, 当多个空洞卷积叠加时, 有些像素根本没有被利到, 会损失信息的连续性与相关性, 进而影响分割、 检测等要求较高的任务
·远距离的信息没有相关性: 空洞卷积采取了稀疏的采样方式, 导致远距离卷积得到的结果之间缺乏相关性, 进而影响分类的结果。
·不同尺度物体的关系: 大的dilation rate对于大物体分割与检测有利, 但是对于小物体则有弊无利, 如何处理好多尺度问题的检测, 是空洞卷积设计的重点。
对于上述问题, 有多篇文章提出了不同的解决方法, 典型的有图森未来提出的HDC(Hybrid Dilated Convolution) 结构。 该结构的设计准则是堆叠卷积的dilation rate不能有大于1的公约数, 同时将dilation rate设置为类似于[1,2,5,1,2,5]这样的锯齿类结构。 此外各dilation rate之间还需要满足一个数学公式, 这样可以尽可能地覆盖所有空洞, 以解决网格效应与远距离信息的相关性问题, 具体细节可参考相关资料。