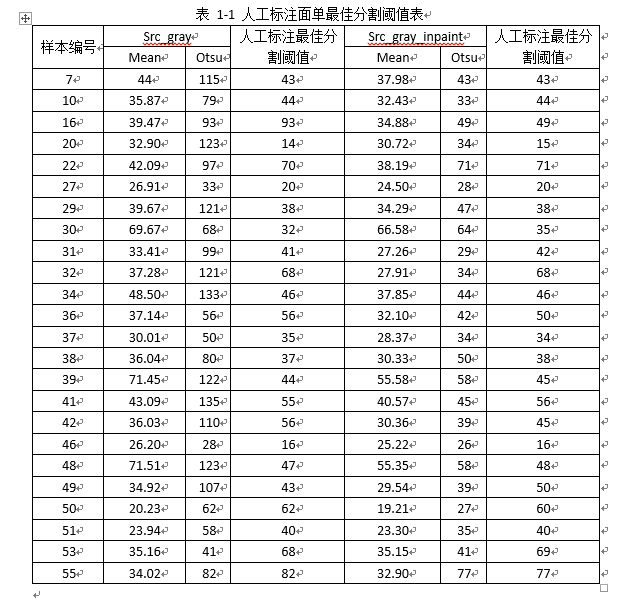
1. 漏定位的面单样本训练+测试统计
- 人工标注面单最佳分割阈值表
- 线性回归模型
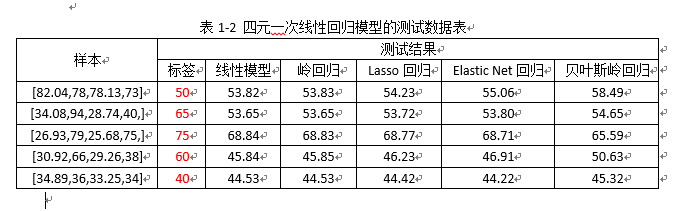
表1-2 注:
1)100个人工标注的样本训练,每个样本包含4个特征(依次:原样本灰度图的灰度均值和全局Otsu值,强光修复后灰度图像的灰度均值及全局Otsu值);
2)测试的数据是从训练样本中随机挑选的5组样本,目的是观测线性回归模型的训练拟合效果;
(这里没有从训练样本之外的数据中挑选样本,来测试验证其泛化性能)
3)从表中可以看出,各种拟合方式的结果相差不大,但是与标签(实际值)有一定差距,说明训练模型欠拟合,有待改进或提高;
解决方案: a. 改进回归模型拟合的方式,比如:提供拟合方程为高次幂(见表1-3分析);
b. 扩大训练的样本规模(见表1-4分析);
c. 改进样本的训练特征(待测试分析)。
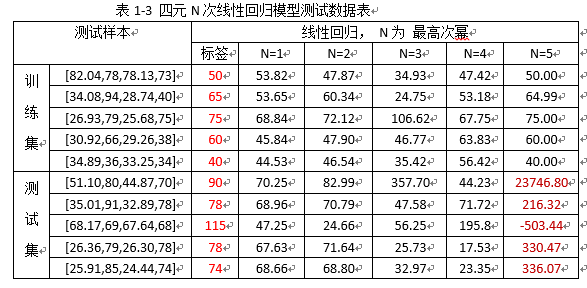
表1-3 注:
1)上述训练的样本仍是100组;
2)观测“训练集”下的测试样本,当N=5时,线性回归模型的测试结果与标签基本保持一致;但是,此时若用“测试集”下的样本,来测试拟合的模型,其结果与实际标签相差甚远,说明训练模型已经过拟合了;
3)训练数据集及测试代码如下.
Train_data.csv


49.986721,50,48.862217,49,34 23.480339,63,22.087894,23,45 47.97068,121,38.859943,44,74 61.894985,117,48.692921,56,90 52.253571,61,49.11853,55,73 19.852621,74,19.222271,72,72 20.845728,62,19.947214,57,56 44.538506,115,37.98954,43,43 13.515056,31,12.830379,28,55 23.994682,69,21.488462,59,85 35.872845,79,32.430157,33,44 29.536407,72,28.510805,64,90 45.398739,128,39.323338,40,35 29.679146,34,27.898521,31,62 84.080841,87,77.693764,74,73 46.169239,134,42.523769,47,38 39.475365,93,34.886265,49,49 59.247337,60,57.82312,58,16 30.091749,92,26.634928,67,68 21.239315,64,20.726948,61,61 32.904915,124,30.729103,34,15 70.833916,64,68.500946,61,54 42.092319,97,38.191372,71,71 16.85672,21,16.744583,21,35 39.519398,99,31.689426,43,52 19.60574,30,17.920612,25,46 30.031826,92,26.656433,67,67 26.915159,33,24.503157,28,20 21.294516,82,19.798532,74,74 39.678482,121,34.299995,47,38 69.679398,68,66.585281,64,35 33.415878,99,27.269951,29,42 37.286701,121,27.919937,34,68 22.043592,51,21.266073,48,48 48.50737,133,37.857922,44,46 34.138905,75,34.10067,74,74 37.146286,56,32.108444,43,50 30.016088,51,28.376884,34,34 36.044006,80,30.333361,50,38 71.459511,122,55.584164,58,45 22.01244,84,20.370054,74,74 53.094749,135,40.457184,46,56 36.035366,110,30.367359,39,45 35.164429,74,35.164429,74,74 31.496492,34,30.231068,32,55 34.097385,36,32.628937,33,50 26.203951,28,25.222651,26,16 52.870003,57,48.843529,52,110 71.513496,123,55.356491,58,48 34.929268,107,29.545202,39,50 20.235893,62,19.217731,27,60 23.946028,58,23.30785,35,40 19.356678,58,18.866066,54,54 35.159679,41,35.159081,41,69 38.879154,131,31.500521,37,37 34.023487,82,32.900944,77,77 30.402153,71,28.825174,66,66 36.666336,100,33.766953,37,81 31.849125,96,27.252998,35,57 14.701057,66,13.695985,59,58 24.746655,37,22.891354,30,35 15.988938,57,15.686599,55,56 64.210938,124,49.422485,53,58 38.794212,113,33.314041,39,74 13.345396,57,13.345396,57,56 41.711437,124,31.613926,37,110 38.293716,79,37.682972,76,76 28.073799,75,24.945026,34,46 24.975405,38,22.897106,29,40 36.917492,116,29.782568,39,56 56.393402,69,56.080254,68,44 49.489582,71,46.603695,64,26 11.233971,51,10.257475,26,45 75.045959,82,69.606705,72,72 57.210033,65,55.995747,62,46 47.267517,117,36.350822,44,95 13.978129,62,13.61613,59,58 19.296797,54,19.054842,53,53 13.23297,60,13.115759,59,58 37.072403,116,30.066593,40,55 22.710648,37,21.312677,34,34 77.6241,76,73.901886,71,35 68.972183,80,59.639511,65,115 14.73587,64,14.347698,62,62 27.683052,82,26.073189,73,14 8.845615,23,8.736045,22,40 50.006321,120,38.885624,48,45 61.246403,67,59.450649,63,72 27.532454,88,24.988146,74,74 46.767673,115,36.288193,46,105 59.823963,66,58.650486,64,25 38.470818,117,31.213203,41,60 53.724159,108,46.329811,48,55 13.401003,61,13.132825,60,58 46.456448,126,38.748985,43,43 82.047318,78,78.135925,73,50 34.080803,94,28.746769,40,65 26.933811,79,25.688793,75,75 30.923611,66,29.268738,38,60 34.891171,36,33.256649,34,40
MLP_PolyNormialFeatures.py
1 import matplotlib.pyplot as plt 2 import numpy as np 3 from numpy import genfromtxt 4 from sklearn import linear_model 5 from sklearn.preprocessing import PolynomialFeatures 6 7 dataPath = r"delivery_analyze.csv" 8 deliveryData = genfromtxt(dataPath, delimiter=',') 9 10 print("data") 11 print(deliveryData) 12 13 X = deliveryData[:, :-1] 14 Y = deliveryData[:, -1] 15 16 # print("X:") 17 # print(X) 18 # print("Y: ") 19 # print(Y.shape) 20 21 poly_reg = PolynomialFeatures(degree=2) #degree=2表示二次多项式 22 X_poly = poly_reg.fit_transform(X) 23 lin_reg_2 = linear_model.LinearRegression() 24 lin_reg_2.fit(X_poly, Y) 25 26 27 # # 查看回归系数 28 # print('Coefficients:', lin_reg_2.coef_) 29 # # 查看截距项 30 # print('intercept:', lin_reg_2.intercept_) 31 32 test_datas = [[82.047318,78,78.135925,73], 33 [34.080803,94,28.746769,40], 34 [26.933811,79,25.688793,75], 35 [30.923611,66,29.268738,38], 36 [34.891171,36,33.256649,34], 37 [51.101326,80,44.875404,70], 38 [35.011463,91,32.894814,78], 39 [68.176659,69,67.649818,68], 40 [26.362432,79,26.302559,78], 41 [25.918451,85,24.443407,74]] 42 43 for data in test_datas: 44 X_pred = data 45 X_pred = np.array(X_pred).reshape(1, -1) 46 Y_pred = lin_reg_2.predict(poly_reg.fit_transform(X_pred)) 47 48 print(Y_pred)
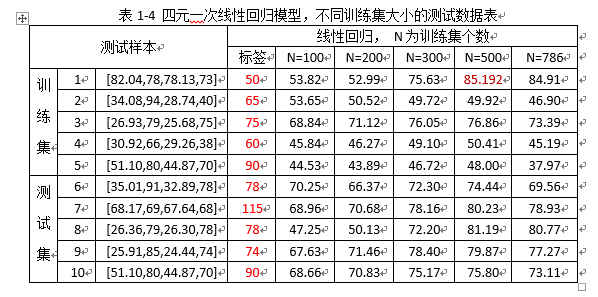

图1-1 训练集的样本测试结果变化图

图1-2 测试集的样本测试结果变化图
结合表1-4,及图1-1、1-2 分析:
随着训练样本规模N的变大,预测的结果逐渐趋于稳定,说明模型逐渐趋于饱和;但是拟合预测的结果与实际的标签数据有一定误差:
1)训练集样本的测试结果中,比如第1行数据,当N=786时,预测的结果为84.91,而样本的标签值是50,相差24.91;
2)测试集样本的测试结果中,比如第7行数据,当N=786时,预测的结果为78.93,而样本的标签值为115,误差为34.07.
总结,随着训练样本规模的增大,线性回归模型并没有解决训练模型欠拟合的问题。
- 非线性回归模型
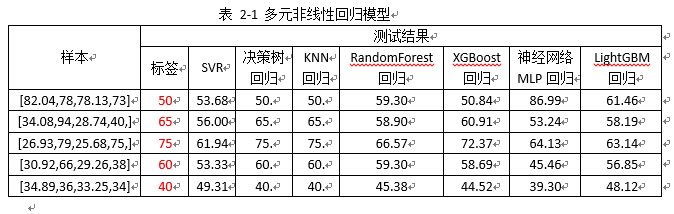
表2-1,注:
1)训练数据仍然是100组样本,测试的样本来自训练数据中;
2) 非线性回归模型方式,只有决策树回归、KNN回归两种方式的拟合结果与标签保持一致,其他的方式都存在较大误差;
3)针对其他(除决策树回归、KNN回归)以外回归模型的欠拟合问题,解决方案:
a. 增大训练样本规模(见表2-2分析);
b. 改变训练网络模型的参数(待测试分析)。
4)针对决策树回归、KNN回归,需验证其模型的泛化性能(见表2-3和2-4分析)。

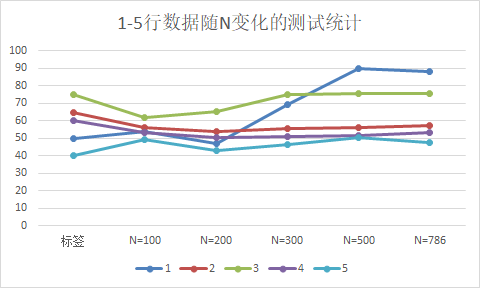
图 2-1 SVR下,训练集下的数据测试随N变化预测结果
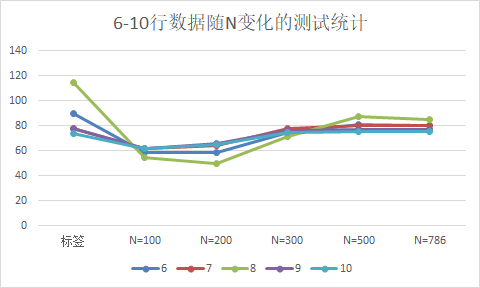
图 2-2 SVR下,测试集下的数据测试随N变化预测结果
随着训练样本规模N的变大,预测的结果逐渐趋于稳定,说明模型逐渐趋于饱和;但是拟合预测的结果与实际的标签数据有一定误差:
1)训练集样本的测试结果中,比如第1行数据,当N=786时,预测的结果为88.33,而样本的标签值是50,相差38.33;
2)测试集样本的测试结果中,比如第7行数据,当N=786时,预测的结果为84.79,而样本的标签值为115,误差为30.21.
总结,随着训练样本规模的增大,SVR(非线性回归模型)并没有解决训练模型欠拟合的问题。
注:RandomForest回归、XGBoost回归、神经网络MLP回归、LightGBM回归的结论同SVR回归;
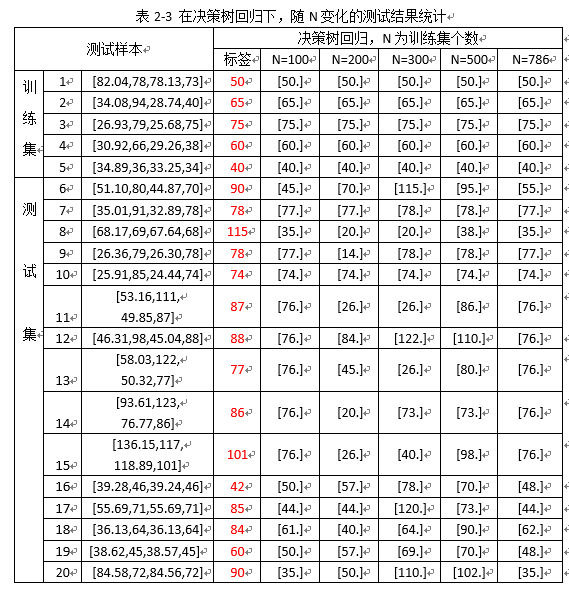
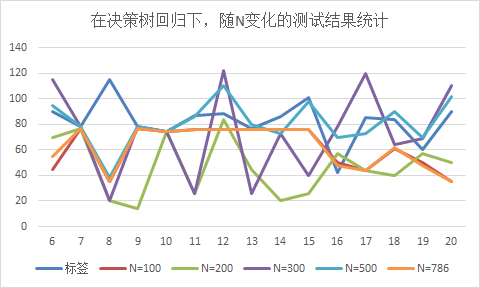
图2-3 决策树回归下,测试集下的数据测试随N变化预测结果(竖着看随N变化结果)
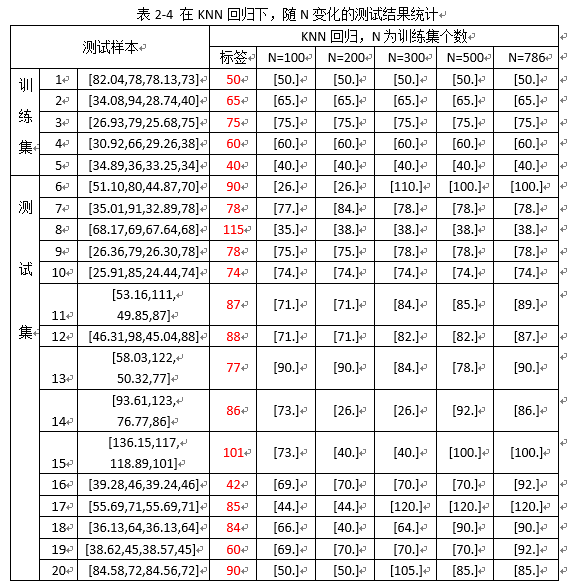
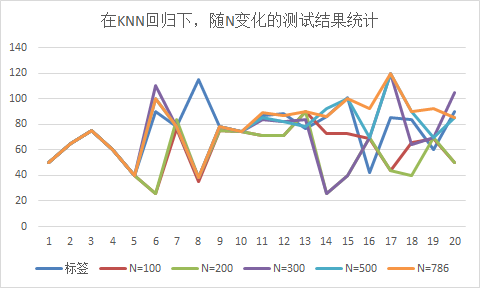
图2-4 KNN回归下,测试集下的数据测试随N变化预测结果(竖着看随N变化结果)
综合表2-3,2-4和图2-3,2-4,发现:
1)随着训练样本N的增多,训练集中挑选的测试样本都拟合预测正确;
2)测试集中挑选的15个样本测试,预测结果随训练样本N的增多,预测结果正确的个数有所提高(由(N=100时的3个)提高到(N=786时的10个))。
注:预测的结果与标签在(±6个误差范围内),认为预测结果正确;
- 总结
1. 多元线性回归模型欠拟合的问题实验总结:
1) 提高拟合方程的参数的次幂,训练样本可到达完美拟合效果(预测结果与标签一致),但是测试集的性能较差,训练模型出现过拟合现象;
2)增大训练样本的规模,训练数据的样本预测结果趋于稳定时(即训练模型趋于饱和时),预测结果与其对应的标签仍存在较大误差,模型仍存在欠拟合现象。
3)怀疑:漏定位面单的条码样本本身就受光照曝光、对比度不均等影响,导致出现特例的情况(即,计算训练的4个特征与标签,不符合大多数样本应该遵循的分布规律,也就是样本本身属于“噪声”的情况,应该从训练样本中予以清除);
下一步验证:a. 挑选能正常定位面单的样本,人工标记训练(排除“噪声”样本的干扰),看是否能正确拟合,并满足测试集样本的测试效果;
b. 重新设计特征与标签,进行拟合训练验证。
2. 多元非线性回归模型实验总结:
1)KNN回归和决策树回归拟合的模型,不论训练数据规模如何变化(N>100),利用训练集中样本去预测,都能和标签结果保持一致;但是测试集的样本预测,随着训练样本规模N的增多,拟合结果在允许误差范围内的正确个数,逐渐增多;
2)其他模型(诸如:SVR回归、RandomForest回归、XGBoost回归、神经网络MLP回归、LightGBM回归),随着训练样本N的增多,仍然存在欠拟合的现象;
3) 下一步工作:可考虑继续增大训练样本的规模,验证KNN回归和决策树回归的拟合性能。