SSD算法原理综述:
参考:http://www.360doc.com/content/20/0104/21/99071_884171814.shtml
https://blog.csdn.net/qq_41368247/article/details/88027340?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weight&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.edu_weight
1. 数据预处理
PyTorch对于数据的加载与处理提供了一些标准类, 可以很灵活地实现各种功能。 SSD对于数据的预处理, 尤其是数据增强做了丰富的处理, 也实现了非常优越的性能, 因此将这部分单独拿出来细讲。
1.1 加载PASCAL数据集
PyTorch加载数据集主要有3步:
(1) 继承Dataset类, 重写__len__()和__getitem__()函数并实例化,这样就可以方便地进行数据集的迭代。
(2) 为了满足实际训练要求、 增强数据的丰富性, 还要选择合适的数据增强方法, 这部分内容将在下一节细讲。
(3) 继承DataLoader类, 添加batch和多线程等功能。
在训练脚本train.py中, 加载数据集的示例代码如下:

1.2 数据增强
SSD做了丰富的数据增强策略, 这部分为模型的mAP带来了8.8%的提升, 尤其是对于小物体和遮挡物体等难点, 数据增强起到了非常重要的作用。
SSD的数据增强整体流程如图5.2所示, 总体上包括光学变换与几何变换两个过程。 光学变换包括亮度和对比度等随机调整, 可以调整图像像素值的大小, 并不会改变图像尺寸; 几何变换包括扩展、 裁剪和镜像等操作, 主要负责进行尺度上的变化, 最后再进行去均值操作。 大部分操作都是随机的过程, 尽可能保证数据的丰富性。
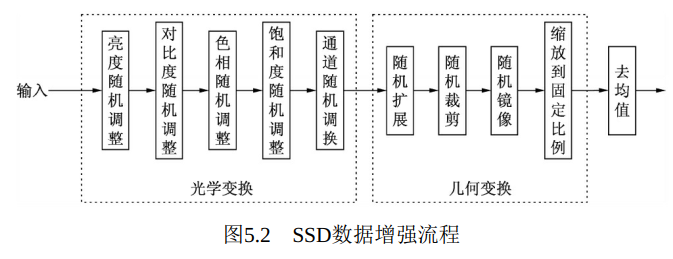
数据增强的总体流程代码如下, 源文件见utils/augmentations.py


接下来是对比度、 色相与饱和度的随机调整。 色相的随机调整与亮度很类似, 都是随机地加一个数, 而对比度与饱和度则是随机乘一个数。 另外, 对色相与饱和度的调整是在HSV色域空间进行的。 由于此三者与亮度很相似, 代码不再单独给出。
关于以上三者的调整顺序, SSD也给了一个随机处理, 即有一半的概率对比度在另外两者之前, 另一半概率则是对比度在另外两者之后。光学变换的最后一项是添加随机的光照噪声, 具体做法是随机交换RGB三个通道的值, 具体实现如RandomLightingNoise()类所示。

1.3 几何变换
在几何变换中, 首先进行的是尺度的随机扩展。 扩展的具体过程是随机选择一个在[1,4)区间的数作为扩展比例, 将原图像放在扩展后图像的右下角, 其他区域填入每个通道的均值, 即[104,117,123], 如图5.3所示。

代码实现时, 首先利用random函数保证有一半的概率进行扩展, 后随机选择一个位于[1,4)区间的比例值, 新建一个图像, 将均值与原图像素值依次赋予新图, 最后再将对应的边框也进行平移, 即完成了扩展流程。


随机扩展后, 紧接着进行随机裁剪。 SSD的裁剪策略是从图像中随机裁剪出一块, 需要保证该图像块至少与一个物体边框有重叠, 重叠的比例从{0.1、 0.3、 0.7、 0.9}中随机选取, 同时至少有一个物体的中心点落在该图像块中。
这种随机裁剪的好处在于, 首先每一个图形块都要有物体, 可以过滤掉不包含明显真实物体的图像; 同时, 不同的重叠比例也极大地丰富了训练集, 尤其是针对物体遮挡的情况。 由于处理步骤较多, 在此不再针对裁剪进行代码说明。
裁剪后进行的是随机的图像镜像, 通常是图像的左右翻转, 这是一种简单又极为实用的图像增强手段, 在多个物体检测算法中都会用到。

在完成镜像后, 最后一步几何变换是固定缩放, 默认使用了300×300的输入大小。 这里300×300的固定输入大小是经过精心设计的可以恰好满足后续特征图的检测尺度, 例如最后一层的特征图大小为1×1, 负责检测的尺度则为0.9。 原论文作者也给出了另外一个更精确的500×500输入的版本。
经过上述光学与几何两个变换后, 最后一步是常见的去均值处理,具体操作是减去每个通道的均值, 具体代码如下:

2. 网络架构
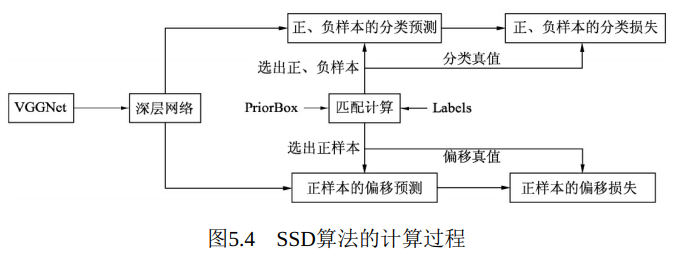
SSD使用VGGNet作为基础Backbone, 然后为了提取更高语义的特征, 在VGGNet后又增加了多个卷积层, 最后利用多个特征图进行边框的特征提取。 得到深层网络后, SSD的计算过程如图5.4所示。
2.1 基础VGG结构
首先, 利用人工设置的一系列PriorBox与标签里的边框进行匹配,并根据重叠程度筛选出正、 负样本, 得到分类与偏移的真值, 这一步类似于Faster RCNN中的匹配过程。 筛选出正、 负样本后, 从深层网络中拿出对应的样本的分类预测值与偏移预测值, 与真值计算分类和偏移的损失。
针对SSD的基础网络, 有以下两点需要注意:
·原始的VGG 16的池化层统一大小为2×2, 步长为2, 而在SSD中,Conv 5后接的Maxpooling层池化大小为3, 步长为1, 这样做可以在增加感受野的同时, 维持特征图的尺寸不变。
·Conv 6中使用了空洞数为6的空洞卷积, 其padding也为6, 这样做同样也是为了增加感受野的同时保持参数量与特征图尺寸的不变。
利用PyTorch构造该基础网络时, 只需要在官方VGG 16的基础上进行一些修改即可。 SSD的基础网络代码主要在ssd.py中, 具体如下:


2.2 深度卷积层
在VGG 16的基础上, SSD进一步增加了4个深度卷积层, 用于更高语义信息的提取, 如图5.6所示。 可以看出, Conv 8的通道数为512, 而Conv 9、 Conv 10与Conv 11的通道数都为256。 从Conv 7到Conv 11, 这5个卷积后输出特征图的尺寸依次为19×19、 10×10、 5×5、 3×3和1×1。

为了降低参数量, 在此使用了1×1卷积先降低通道数为该层输出通道数的一半, 再利用3×3卷积进行特征提取。
利用PyTorch可以很方便地实现该深度卷积层, 源代码文件为ssd.py, 具体如下:


2.3 PriorBox与边框特征提取网络
与Faster RCNN的Anchor类似, SSD采用了PriorBox来进行区域生成。 不同的是, Faster RCNN首先在第一个阶段对固定的Anchor进行了位置修正与筛选, 得到感兴趣区域后, 在第二个阶段再对该区域进行分类与回归, 而SSD直接将固定大小宽高的PriorBox作为先验的感兴趣区域, 利用一个阶段完成了分类与回归。
PriorBox本质上是在原图上的一系列矩形框, 如图5.7所示。 某个特征图上的一个点根据下采样率可以得到在原图的坐标, SSD先验性地提供了以该坐标为中心的4个或6个不同大小的PriorBox, 然后利用特征图的特征去预测这4个PriorBox的类别与位置偏移量。
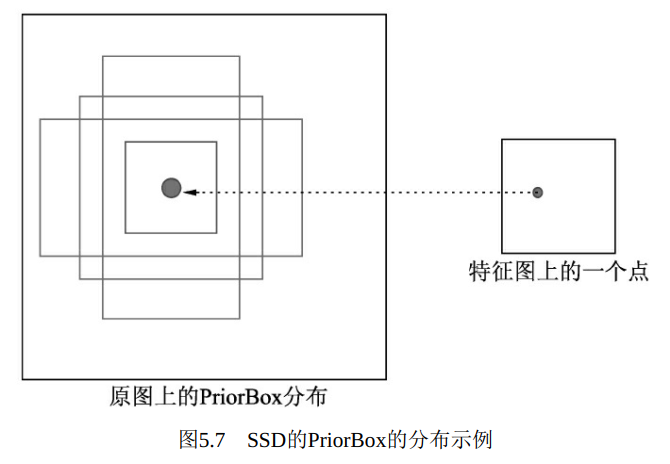
在Faster RCNN中, 所有Anchors对应的特征都来源于同一个特征图, 而该层特征的感受野相同, 很难处理被检测物体的尺度变化较大的情况, 多个大小宽高的Anchors能起到的作用也有限。
从前几章的讲解可以得出, 在深度卷积网络中, 浅层的特征图拥有较小的感受野, 深层的特征图拥有较大的感受野, 因此SSD充分利用了这个特性, 使用了多层特征图来做物体检测, 浅层的特征图检测小物体, 深层的特征图检测大物体, 如图5.8所示。

从图5.8中可以看出, SSD使用了第4、 7、 8、 9、 10和11这6个卷积层得到的特征图, 这6个特征图尺寸越来越小, 而其对应的感受野越来越大。 6个特征图上的每一个点分别对应4、 6、 6、 6、 4、 4个PriorBox。接下来分别利用3×3的卷积, 即可得到每一个PriorBox对应的类别与位置预测量。
举个例子, 第8个卷积层得到的特征图大小为10×10×512, 每个点对应6个PriorBox, 一共有600个PriorBox。 由于采用的PASCAL VOC数据
集的物体类别为21类, 因此3×3卷积后得到的类别特征维度为6×21=126, 位置特征维度为6×4=24。
如何确定每一个特征图PriorBox的具体大小呢? 由于越深的特征图拥有的感受野越大, 因此其对应的PriorBox也应越来越大, SSD采用了公式(5-1) 来计算每一个特征图对应的PriorBox的尺度。

公式中K的取值为1、 2、 3、 4、 5、 6, 分别对应着SSD中的第4、7、 8、 9、 10、 11个卷积层。 Sk代表这一层对应的尺度, Smin为0.2,Smax为0.9, 分别表示最浅层与最深层对应的尺度与原图大小的比例, 即第4个卷积层得到的特征图对应的尺度为0.2, 第11个卷积层得到的特征图对应的尺度为0.9。
基于每一层的基础尺度Sk, 对于第1、 5、 6个特征图, 每个点对应了4个PriorBox, 因此其宽高分别为{Sk,Sk}、 、 与, 而对于第2、 3、 4个特征图, 每个点对应了6个PriorBox, 则
在上述4个宽高值上再增加 和 这两种比例的框。
下面利用代码详细介绍如何生成每一层所需的PriorBox, 代码位于layers/functions/prior_box.py中。

有了多层的特征图, 利用3×3卷积即可完成如图5.7所示的提取过程。 下面为所有边框特征提取的PyTorch实现。 代码文件为ssd.py


综上所述, 这一小节一方面生成了共计8732个PriorBox的位置信息, 同时也利用卷积网络提取了这8732个PriorBox的特征。
3. 总体网络计算过程
上一节讲解了SSD的PriorBox与特征提取网络。 为了更好地梳理网络的前向过程, 本节将从代码角度讲述SSD网络的整个前向过程, 以便让读者理解起来更加清晰。 代码文件为ssd.py。

4. 匹配与损失求解
上一节的卷积网络得到了所有PriorBox的预测值与边框位置, 为了得到最终的结果, 还需要进行边框的匹配及损失计算。
SSD的这部分网络后处理可以分为4步: 首先按照一定的原则, 对所有的PriorBox赋予正、 负样本的标签, 并确定对应的真实物体标签,以方便后续损失的计算; 有了对应的真值后, 即可计算框的定位损失,这部分只需要正样本即可; 同时, 为了克服正、 负样本的不均衡, 进行难样本挖掘, 筛选出数量是正样本3倍的负样本; 最后, 计算筛选出的正、 负样本的类别损失, 完成整个网络向前计算的全过程。
4.1 预选框与真实框的匹配
在求得8732个PriorBox坐标及对应的类别、 位置预测后, 首先要做的就是为每一个PriorBox贴标签, 筛选出符合条件的正样本与负样本,以便进行后续的损失计算。 判断依据与Faster RCNN相同, 都是通过预测与真值的IoU值来判断。
SSD处理匹配过程时遵循以下4个原则:
·在判断正、 负样本时, IoU阈值设置为0.5, 即一个PriorBox与所有真实框的最大IoU小于0.5时, 判断该框为负样本。
·判断对应关系时, 将PriorBox与其拥有最大IoU的真实框作为其位置标签。
·与真实框有最大IoU的PriorBox, 即使该IoU不是此PriorBox与所有真实框IoU中最大的IoU, 也要将该Box对应到真实框上, 这是为了保证真实框的Recall。
·在预测边框位置时, SSD与Faster RCNN相同, 都是预测相对于预选框的偏移量, 因此在求得匹配关系后还需要进行偏移量计算, 具体公式参照4.4.2节.
具体的匹配过程在layers/box_utils.py中, 主要是下面的match函数。


4.2 定位损失的计算
在完成匹配后, 由于有了正、 负样本及每一个样本对应的真实框,因此可以进行定位的损失计算。 与Faster RCNN相同, SSD使用了smoothL10函数作为定位损失函数, 并且只对正样本计算。 具体公式可参见4.4.5节。

4.3 难样本挖掘
在完成正、 负样本匹配后, 由于一般情况下一张图片的物体数量不会超过100, 因此会存在大量的负样本。 如果这些负样本都考虑则在损失反传时, 正样本能起到的作用就微乎其微了, 因此需要进行难样本的挖掘。 这里的难样本是针对负样本而言的。
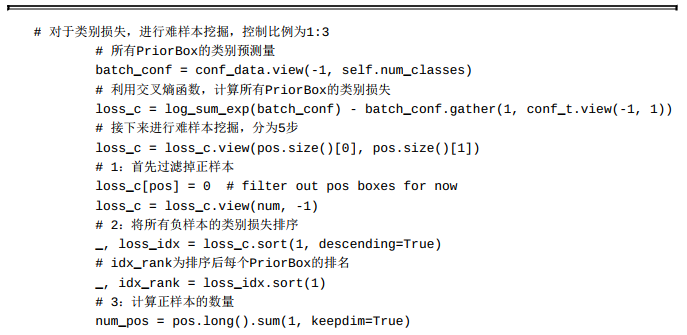
Faster RCNN通过限制正负样本的数量来保持正、 负样本均衡, 而在SSD中, 则是保证正、 负样本的比例来实现样本均衡。 具体做法是在计算出所有负样本的损失后进行排序, 选取损失较大的那一部分进行计算, 舍弃剩下的负样本, 数量为正样本的3倍。
具体实现如代码所示。 在计算完所有边框的类别交叉熵损失后, 难样本挖掘过程主要分为5步: 首先过滤掉正样本; 然后将负样本的损失排序; 接着计算正样本的数量; 进而得到负样本的数量; 最后根据损失大小得到留下的负样本索引。 源代码文件见layers/modules/multibox_loss.py。

4.4 类别损失计算
在得到筛选后的正、 负样本后, 即可进行类别的损失计算。 SSD在此使用了交叉熵损失函数, 并且正、 负样本全部参与计算。 交叉熵损失函数可参见4.4.5节。
