视图: 也就是一个虚拟表(不是真实存在的),它的本质就是根据SQL语句获取动态的数据集,并为其命名。用户使用时只需要使用命名的视图即可获取结果集,并可以当做表来使用。它的作用就是方便查询操作,减少复杂的SQL语句,增强可读性,更加安全。
①创建视图
-- 创建视图 -- 格式 create view 视图名称 as SQL语句 create view user_view as select name,age,gender from userinfo
userinfo的表:
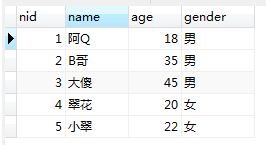
生成的视图user_view:
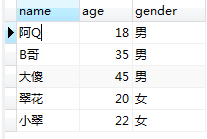
②删除视图:
格式:drop view 视图名称
drop view user_view
③修改视图:
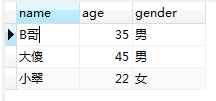
-- 修改视图 -- 格式 alter view 视图名称 as SQL语句 alter view user_view as select name,age,gender from userinfo where age > 20
修改后的视图user_view:
索引:是表的目录,在查找内容之前可以先在目录中查找索引位置,以此快速定位查询数据,对于索引,会保存在额外的文件中。是专门用于帮助用户快速查询数据的一种数据结构,类似于字典中的目录,查找字典内容时可以根据目录查找到数据库的存放位置,然后直接获取即可
①特点
a:由数据库中一列或多列组合而成,作用就是提高对表中数据的查询速度
b:创建和维护索引需要耗费时间,会减慢写入速度
②索引分类
a:普通索引--仅加速查询,数据列可以重复,不做约束
b:唯一索引--加速查找,约束列数据不能重复,可以有null
c:主键索引--加速查找,约束列数据不能重复,不能为null
d:组合索引--多列可以创建一个索引文件,联合唯一,加速查找,约束列数据不能重复,不能为null
e:全文索引--对文本的内容进行分词,进行搜索
③创建索引
-- 创建索引 -- 格式 -- 创建表的时候创建 CREATE TABLE tb_name )( 字段名称 字段类型 [ 完整性约束条件 ], [ UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY [ 索引名称 ] (字段名称 [(长度) ]) [ ASC | DESC ] ); -- 已存在表创建 1,CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称 ON 表名{字段名称[(长度)] [ASC|DESC]} 2,ALTER TABLE tb_name ADD [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称(字段名称[(长度)] [ASC|DESC]); -- 删除索引 DROP INDEX 索引名称 ON tb_name
触发器:是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,比数据库本身标准功能有更精细更复杂的数据控制能力。
④普通索引
-- 普通索引 create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name(name) ) -- 查看索引 show index from tb1
⑤唯一索引
-- 创建唯一索引 create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, unique ix_name (name) )
⑥主键索引
create table tb1( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, extra text, index ix_name (name) )
存储过程:简单地说就是一组SQL语句集,功能强大,可以实现一些比较复杂的逻辑功能。
①优点:
a:通过把处理封装在容易使用的单元中,简化复杂操作
b:由于不要求反复建立一些列处理步骤,这保证了数据的完整性,如果开发人员和应用程序都使用同一存储过程,则所使用的代码是相同的。还有 就是防止错误,需要执行的步骤越多,出错的可能性越大。防止错误保证了数据的一致性。
c:简化对变动的管理,如果表名,列名或业务逻辑有变化,只需要更改存储过程的代码,使用它的人员不会改自己的代码了
d:提高性能,因为使用存储过程比使用单条语句要快
e:存在一些职能用在单个请求的MySql元素和特性,存储过程可以使用它们来编写功能更强更灵活的代码
总结起来就是:简单,安全,高性能
②缺点:
a:不同的数据库,语法差别大,移植困难,换了数据库,需要重写编写
b:不好管理,把过多的业务逻辑写在存储过程不好维护,不利于分层管理,容易混乱,一般存储过程适用于个别对性能要求较高的业务
③创
-- 创建 -- 如果存储过程存在,则先删除 drop procedure if exists p1; -- delimiter 替换默认的输入结束符 delimiter // -- procedure create procedure p1() begin select * from course; end// delimiter ; -- 通过call来执行 call p1()
对于存储过程,可以接收三个参数:
in:仅用于传入参数用
out:仅用于返回值用
inout:既可以传入又可以当做返回值
drop procedure if exists p1; delimiter // create procedure p1( in i1 int, in i2 int, inout i3 int, out r1 int ) begin declare temp1 int; declare temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end// delimiter ; -- 执行过程 -- @表示变量 set @t1 = 4; set @t2 = 0; call p1(1,2,@t1,@t2); -- 返回值就是inout 和 out对应的结果 select @t1,@t2;
注:存储过程的作用就是获取两类数据--普通值和结果集,它可以执行多个sql语句,结果集只能是一个,也就是说,在存储过程中,如果有多个select只会拿一个
触发器:是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,比数据库本身标准功能有更精细更复杂的数据控制能力。
函数:http://www.cnblogs.com/kissdodog/p/4168721.html
自定义函数:
-- 自定义函数 drop function if exists f1; delimiter \ create function f1( i1 int, i2 int ) returns int begin declare num int; set num = i1 + i2; return(num); end; \ delimiter; -- 在查询中使用 select f1(11,nid) as "result",name from tb;
与存储过程的区别:不能获取结果集,不允许写sql语句,通过returns返回,而存储过程可以写sql语句,通过out或inout返回