ACK Serverless(Serverless Kubernetes)近期基于ECI(弹性容器实例)正式推出GPU容器实例支持,让用户以serverless的方式快速运行AI计算任务,极大降低AI平台运维的负担,显著提升整体计算效率。
AI计算离不开GPU已经是行业共识,然而从零开始搭建GPU集群环境是件相对复杂的任务,包括GPU规格购买、机器准备、驱动安装、容器环境安装等。GPU资源的serverless交付方式,充分的展现了serverless的核心优势,其向用户提供标准化而且“开箱即用”的资源供给能力,用户无需购买机器也无需登录到节点安装GPU驱动,极大降低了AI平台的部署复杂度,让客户关注在AI模型和应用本身而非基础设施的搭建和维护,让使用GPU/CPU资源就如同打开水龙头一样简单方便,同时按需计费的方式让客户按照计算任务进行消费, 避免包年包月带来的高成本和资源浪费。
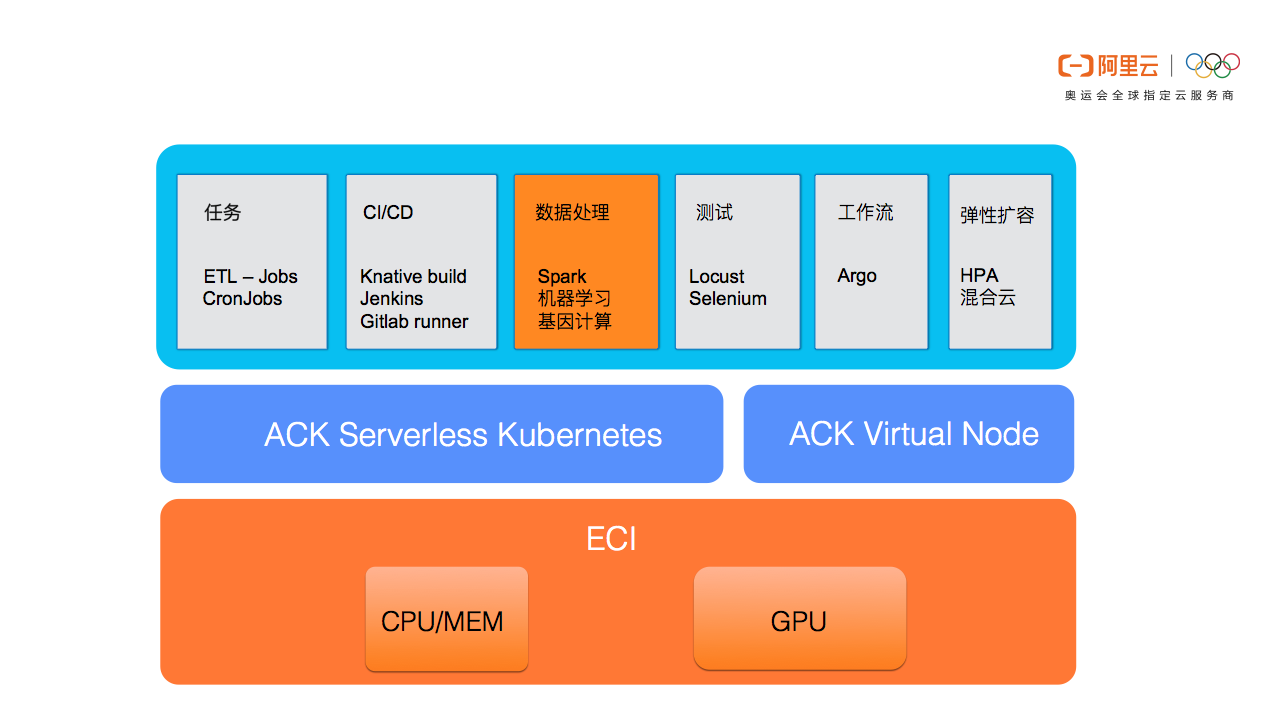
在ACK Serverless中创建挂载GPU的pod也非常简单,通过annotation指定所需GPU的类型,同时在resource.limits中指定GPU的个数即可(也可指定instance-type)。每个pod独占GPU,暂不支持vGPU,GPU实例的收费与ECS GPU类型收费一致,不产生额外费用,目前阿里云ECI提供如下几种规格的GPU类型:(详情请参考https://help.aliyun.com/document_detail/114581.html)
| vCPU | 内存(GiB) | GPU类型 | GPU count |
|---|---|---|---|
| 2 | 8.0 | P4 | 1 |
| 4 | 16.0 | P4 | 1 |
| 8 | 32.0 | P4 | 1 |
| 16 | 64.0 | P4 | 1 |
| 32 | 128.0 | P4 | 2 |
| 56 | 224.0 | P4 | 4 |
| 8 | 32.0 | V100 | 1 |
| 32 | 128.0 | V100 | 4 |
| 64 | 256.0 | V100 | 8 |
下面让我们通过一个简单的图片识别示例,展示如何在ACK Serverless中快速进行深度学习任务的计算。
创建Serverless Kubernetes集群

使用tensorflow进行图片识别

对于我们人类此图片的识别是极其简单不过的,然而对于机器而言则不是一件轻松的事情,其中依赖大量数据的输入和模型算法的训练,下面我们将基于已有的tensorflow模型对上个图片进行识别。
在这里我们选用了tensorflow的入门示例
镜像registry-vpc.cn-hangzhou.aliyuncs.com/ack-serverless/tensorflow是基于tensorflow官方镜像tensorflow/tensorflow:1.13.1-gpu-py3构建,在里面已经下载了示例所需models仓库:https://github.com/tensorflow/models
在serverless集群控制台基于模版创建或者使用kubectl部署如下yaml文件,pod中指定GPU类型为P4,GPU个数为1。
apiVersion: v1
kind: Pod
metadata:
name: tensorflow
annotations:
k8s.aliyun.com/eci-gpu-type : "P4"
spec:
containers:
- image: registry-vpc.cn-hangzhou.aliyuncs.com/ack-serverless/tensorflow
name: tensorflow
command:
- "sh"
- "-c"
- "python models/tutorials/image/imagenet/classify_image.py"
resources:
limits:
nvidia.com/gpu: "1"
restartPolicy: OnFailure
创建pod等待执行完成,查看pod日志:
# kubectl get pod -a
NAME READY STATUS RESTARTS AGE
tensorflow 0/1 Completed 0 6m
# kubectl logs tensorflow
>> Downloading inception-2015-12-05.WARNING:tensorflow:From models/tutorials/image/imagenet/classify_image.py:141: __init__ (from tensorflow.python.platform.gfile) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.gfile.GFile.
2019-05-05 09:43:30.591730: W tensorflow/core/framework/op_def_util.cc:355] Op BatchNormWithGlobalNormalization is deprecated. It will cease to work in GraphDef version 9. Use tf.nn.batch_normalization().
2019-05-05 09:43:30.806869: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2019-05-05 09:43:31.075142: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2019-05-05 09:43:31.075725: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x4525ce0 executing computations on platform CUDA. Devices:
2019-05-05 09:43:31.075785: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): Tesla P4, Compute Capability 6.1
2019-05-05 09:43:31.078667: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2494220000 Hz
2019-05-05 09:43:31.078953: I tensorflow/compiler/xla/service/service.cc:150] XLA service 0x4ad0660 executing computations on platform Host. Devices:
2019-05-05 09:43:31.078980: I tensorflow/compiler/xla/service/service.cc:158] StreamExecutor device (0): <undefined>, <undefined>
2019-05-05 09:43:31.079294: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: Tesla P4 major: 6 minor: 1 memoryClockRate(GHz): 1.1135
pciBusID: 0000:00:08.0
totalMemory: 7.43GiB freeMemory: 7.31GiB
2019-05-05 09:43:31.079327: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0
2019-05-05 09:43:31.081074: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2019-05-05 09:43:31.081104: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0
2019-05-05 09:43:31.081116: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N
2019-05-05 09:43:31.081379: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7116 MB memory) -> physical GPU (device: 0, name: Tesla P4, pci bus id: 0000:00:08.0, compute capability: 6.1)
2019-05-05 09:43:32.200163: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
>> Downloading inception-2015-12-05.tgz 100.0%
Successfully downloaded inception-2015-12-05.tgz 88931400 bytes.
giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)
indri, indris, Indri indri, Indri brevicaudatus (score = 0.00779)
lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens (score = 0.00296)
custard apple (score = 0.00147)
earthstar (score = 0.00117)pod的日志显示模型已经成功检测到图片为panda。可以看到在整个机器学习计算过程中,我们只是运行了一个pod,当pod变成terminated状态后任务完成,没有ecs环境准备,没有购买GPU机器,没有安装Nivida GPU驱动,没有安装docker软件,计算力如同水电一样按需使用。
最后
ACK中虚拟节点也同样基于ECI实现了GPU的支持,使用方式与ACK Serverless相同(但需要把pod指定调度到虚拟节点上,或者把pod创建在有virtual-node-affinity-injection=enabled label的namespace中),基于虚拟节点的方式可以更灵活的支持多种深度学习框架,如kubeflow、arena或其他自定义CRD。
示例如下:
apiVersion: v1
kind: Pod
metadata:
name: tensorflow
annotations:
k8s.aliyun.com/eci-gpu-type : "P4"
spec:
containers:
- image: registry-vpc.cn-hangzhou.aliyuncs.com/ack-serverless/tensorflow
name: tensorflow
command:
- "sh"
- "-c"
- "python models/tutorials/image/imagenet/classify_image.py"
resources:
limits:
nvidia.com/gpu: "1"
restartPolicy: OnFailure
nodeName: virtual-kubelet本文作者:贤维
本文为云栖社区原创内容,未经允许不得转载。