2019大数据技术公开课第一季《技术人生专访》来袭,本季将带领开发者们探讨大数据技术,分享不同国家的工作体验。本文整理自阿里巴巴计算平台事业部高级技术专家吴刚的专访,将为大家介绍Apache ORC开源项目、主流的开源列存格式ORC和Parquet的区别以及MaxCompute选择ORC的原因。此外,吴还将分享他是如何一步步成为Apache开源项目的Committer和PMC的。
以下内容根据演讲视频以及PPT整理而成。
个人简介

吴刚,阿里巴巴计算平台事业部高级技术专家 ,Apache顶级开源项目ORC的PMC ,目前主要负责MaxCompute平台存储线 相关工作。之前就职于Uber总部,从事Spark和Hive等相关工作。
一、Apache ORC项目介绍以及阿里巴巴对于ORC项目的贡献
Apache ORC Project
正如Apache ORC项目官网所介绍的,Apache ORC是Hadoop生态系统中最快、最小的列式存储文件格式。Apache ORC主打的三个特性包括支持ACID,也就是支持事务,支持内置索引以及支持各种复杂类型。

ORC Adopter
Apache ORC有很多的采用者,比如大家所熟知的Spark、Presto、Hive、Hadoop等开源软件。此外,在2017年,阿里巴巴MaxCompute技术团队也开始参与到Apache ORC项目的工作中,并将ORC作为MaxCompute内置的文件存储格式之一。

Timeline
Apache ORC项目的大致发展历程如下图所示。在2013年初的时候,Hortonworks开始在来替代RCFile文件格式 ,经过了两个版本的迭代,ORC孵化成为了Apache顶级项目,并且顺利地从Hive中脱离出来成为一个单独的项目。在2017年1月,阿里云MaxCompute团队开始向ORC社区持续地贡献代码,并且使得ORC成为MaxCompute内置的文件格式之一。

Contribution from Alibaba
阿里巴巴MaxCompute技术团队为Apache ORC项目做出了大量贡献,比如研发了一个完整的C++的ORC Writer,修复了一些极为重要的Bug,并且大大提升了ORC的性能。阿里巴巴MaxCompute技术团队总共向Apache ORC项目提交了30多个Patch,总计1万5千多行代码,并且目前阿里仍然在持续地向ORC贡献代码。阿里巴巴的技术团队中共有3个ORC项目贡献者,1个PMC和1个Committer。在2017年的Hadoop Summit上,ORC也专门用一页PPT来点名表扬阿里巴巴对于ORC项目的贡献。

二、阿里云MaxCompute为何选择ORC?
Row-based VS. Column-based
对于文件存储而言,有两种主流的方式,即按行存储以及按列存储。所谓按行存储就是把每一行数据依次存储在一起,先存储第一行的数据再存储第二行的数据,以此类推。而所谓按列存储就是把表中的数据按照列存储在一起,先存储第一列的数据,再存储第二列的数据。而在大数据场景之下,往往只需要获取部分列的数据,那么使用列存就可以只读取少量数据,这样可以节省大量磁盘和网络I/O的消耗。此外,因为相同列的数据属性非常相似,冗余度非常高,列式存储可以增大数据压缩率,进而大大节省磁盘空间。因此,MaxCompute最终选择了列存。

A Quick Look at ORC
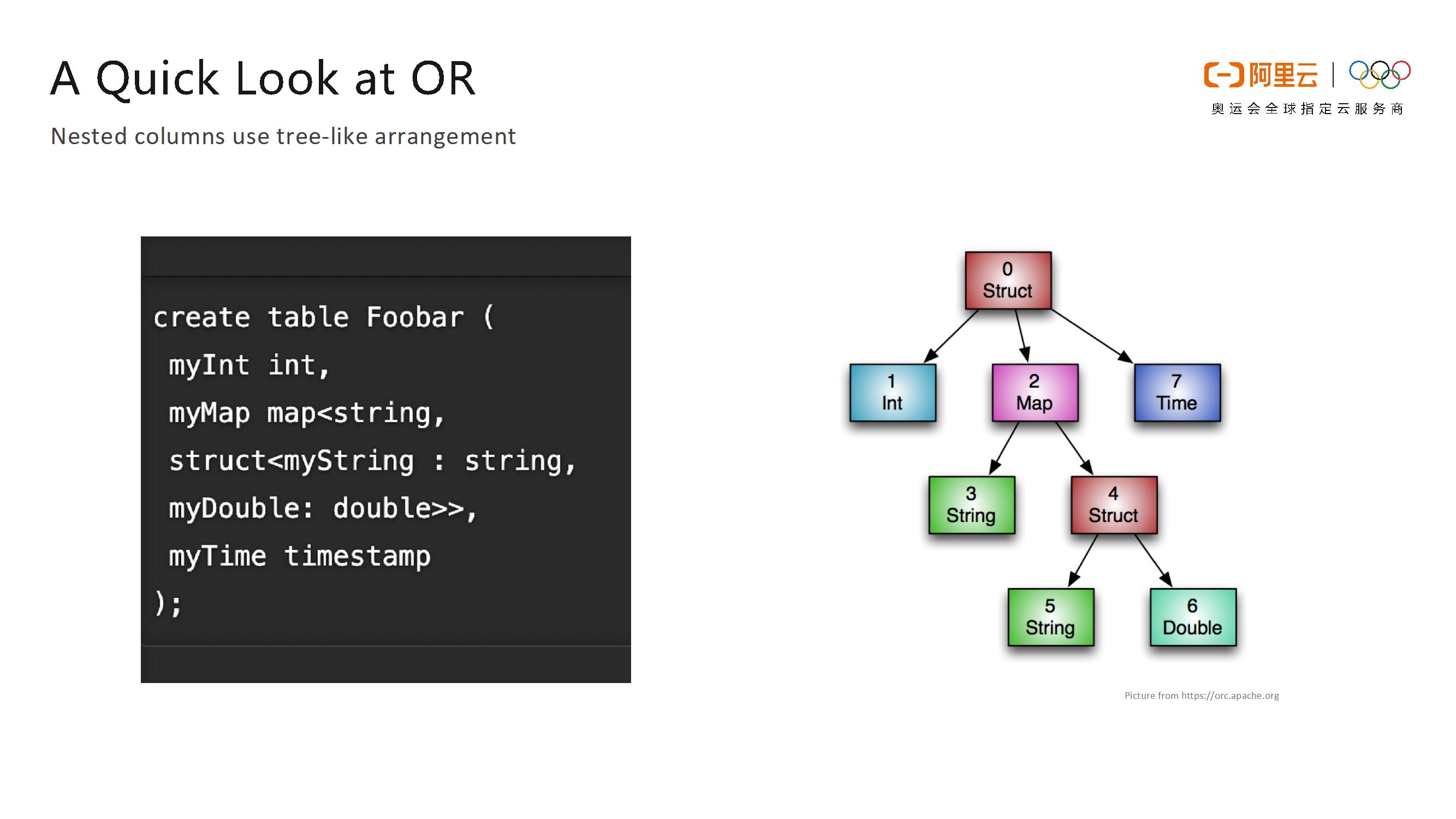
ORC在类型系统上的建模是一个树形结构,对于一些诸如Struct这样的复杂类型会有一个或者多个孩子节点,而Map类型有两个孩子节点,即key和value,List类型就只有一个孩子节点,其他的普通类型则就是一个叶子节点。如下图所示,左侧的表结构就能够被形象地转化成右侧的树型结构,简单并且直观。
ORC主要有两个优化指标,其一 为查询速度。ORC将文件切分成大小相近的块,在块内部使用列式存储,也就是将相同列的数据存储到一起。针对于这些数据,ORC提供轻量的索引支持,包括数据块的最小值、最大值、计数和空值等,基于这些统计信息,可以非常方便地过滤掉不需要读取的数据,以此减少数据的传输。此外,ORC还支持列裁剪 (Column Projection),如果查询中只需要读取部分列,那么Reader只需要返回所需的列数据,进一步减小了需要读取的数据量。

ORC的第二个优化指标就是存储效率。ORC采用了通用的压缩算法,比如开源的zStandard、zlib、snappy、LZO等来提高文件压缩率。同时,ORC也采用了轻量的编码算法,比如run-length encoding、dictionary等。
How about Apache Parquet
在开源软件领域中,与 Apache ORC 对标的就是Apache Parquet。Parquet是由 Cloudera 和 Twitter 共同开发的,其灵感来源于 Google 发表的Dremel的论文。Parquet 的思想和 ORC 非常相近,也是将文件拆分成大小相近的块,并在块里面使用列式存储,并且对于开源系统的支持与 ORC 也相差无几,也能够支持 Spark、Presto 等,并且也使用了列式存储和通用的压缩以及编码算法,也能够提供轻量级索引以及统计信息。

相比ORC,Parquet主要有两点不同。第一点就是Parquet能够更好地支持嵌套类型,Parquet能够通过使用definition和repetition levels方式来标识复杂类型的层数等信息,不过这样的设计却非常复杂,就连Google的论文中也使用整整一页来介绍这个算法,但在实际中,大部分数据并没有使用非常深的嵌套,这像是一个“杀鸡用牛刀”的方法。此外,Parquet的编码类型比ORC也更多一些,其支持plain、bit-packing以及浮点数等编码方式,所以Parquet在某些数据类型的压缩率上比ORC更高。

Benchmark: ORC VS Parquet
- Datasets
基于Github日志数据和纽约市出租车数据这两个开源数据集,Hadoop开源社区进行了ORC和Parquet
的性能对比 ,并得到了一些统计数据。

- Storage Cost
下图比较了ORC、Parquet以及JSON等文件存储方式的性能效率。在Taxi Size的这张表中可以看出,Parquet和ORC存储性能非常相近。

下图展示了Github项目数据集下的存储效率比较,从中可以看出ORC比Parquet的压缩率更高一些,压缩后数据量变得更小。

因此,综上所述,在存储效率方面,ORC和Parquet压缩效率不相上下,在部分数据上ORC优势更大。
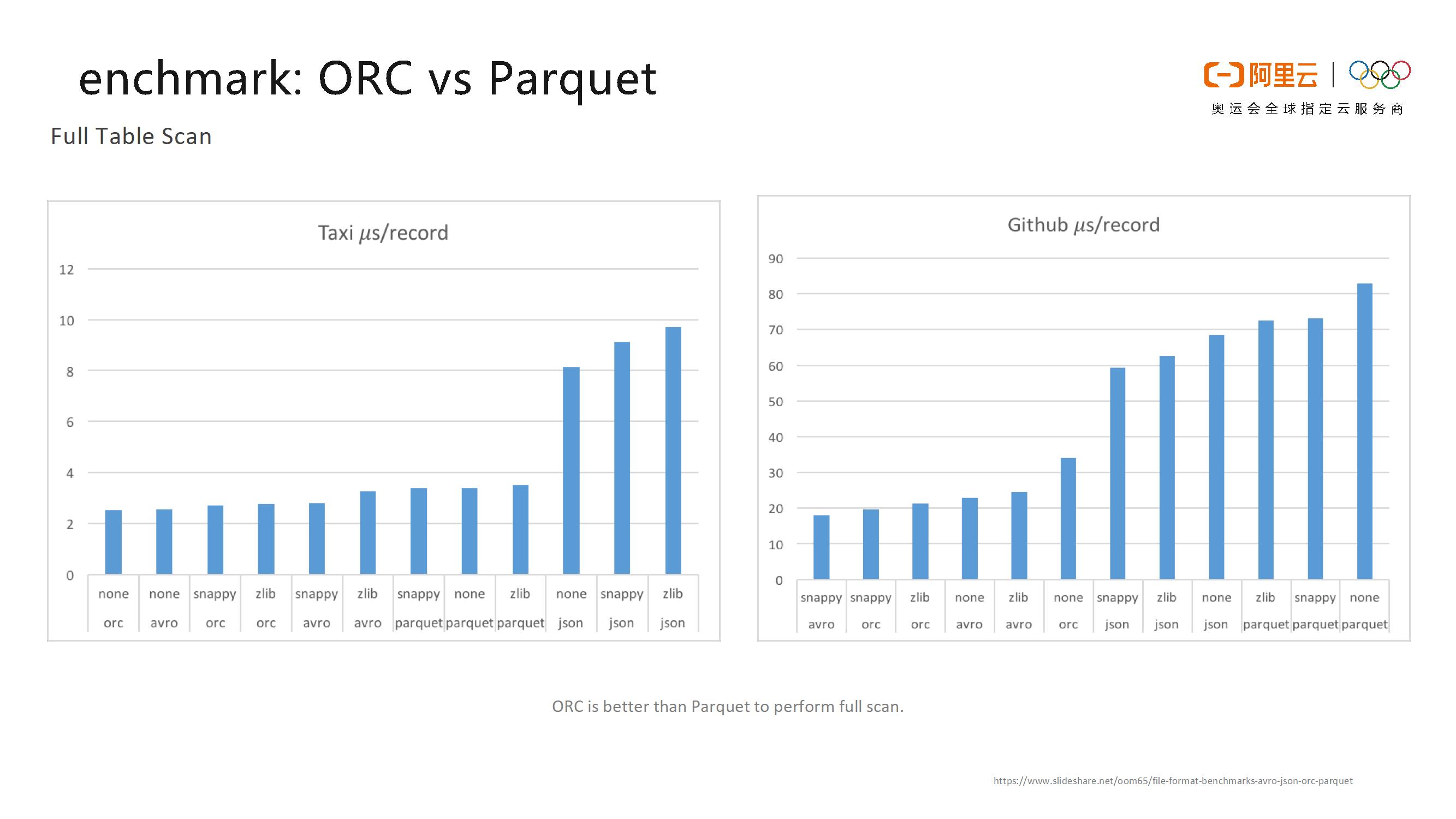
- Full Table Scan
如下所示列出了ORC和Parquet对于两个数据集的读表效率对比情况。总体而言,ORC都比Parquet要更快一些。基于以上比较,MaxCompute最终选择了ORC,因为其不仅设计更为简单,并且读表性能更高。
AliORC = Alibaba ORC
通过上述Benchmark的比较,MaxCompute基于对于性能的考量选择了ORC。而在其他方面,相比于Parquet,ORC也有一些优势,比如前面提到的设计更为简单、代码质量更佳、语言无关性 、能够高效地支持多种开源项目。 并且由于ORC研发团队相对更为集中,创始人对于项目具有较强的掌控力,因此阿里巴巴提出的任何需求和想法都可以获得快速响应和比较有力的支持,进而成为社区的领导者。

三、AliORC和开源ORC有何不同?
AliORC is More Than Apache ORC
AliORC是基于开源Apache ORC的深度优化的文件格式。AliORC的首要目标还是和开源的ORC完全兼容,这样才能更加方便于用户的使用。AliORC主要从两个方面对于开源的ORC进行了优化,一方面,AliORC提供了更多的扩展特性,比如对于Clustered Index和C++ Arrow的支持以及谓词下推等。另一方面,AliORC还进行了性能优化,实现了异步预读、I/O模式管理以及自适应字典编码等。

AliORC Optimization
- Async Prefetch
这里选取几个AliORC对于开源的ORC优化的具体特性进行分享。首先就是Async Prefetch (异步预读)。传统读文件的方式一般是从底层文件系统先拿到原始数据,然后进行解压和解码,这两步操作分别是I/O密集型和CPU密集型任务,并且两者没有任何并行性,因此就加长了整体的端到端时间,但实际上并无必要,并且造成了资源的浪费。AliORC实现了从文件系统读数据和解压解码操作的并行处理,这样就将所有的读盘操作变成了异步的,也就是提前将读取数据的请求全部发送出去,当真正需要数据的时候就去检查之前的异步请求是否返回了数据,如果数据已经返回,则可以立即进行解压和解码操作,而不需要等待读盘,这样就可以极大地提高并行度,并降低读取文件的所需时间。
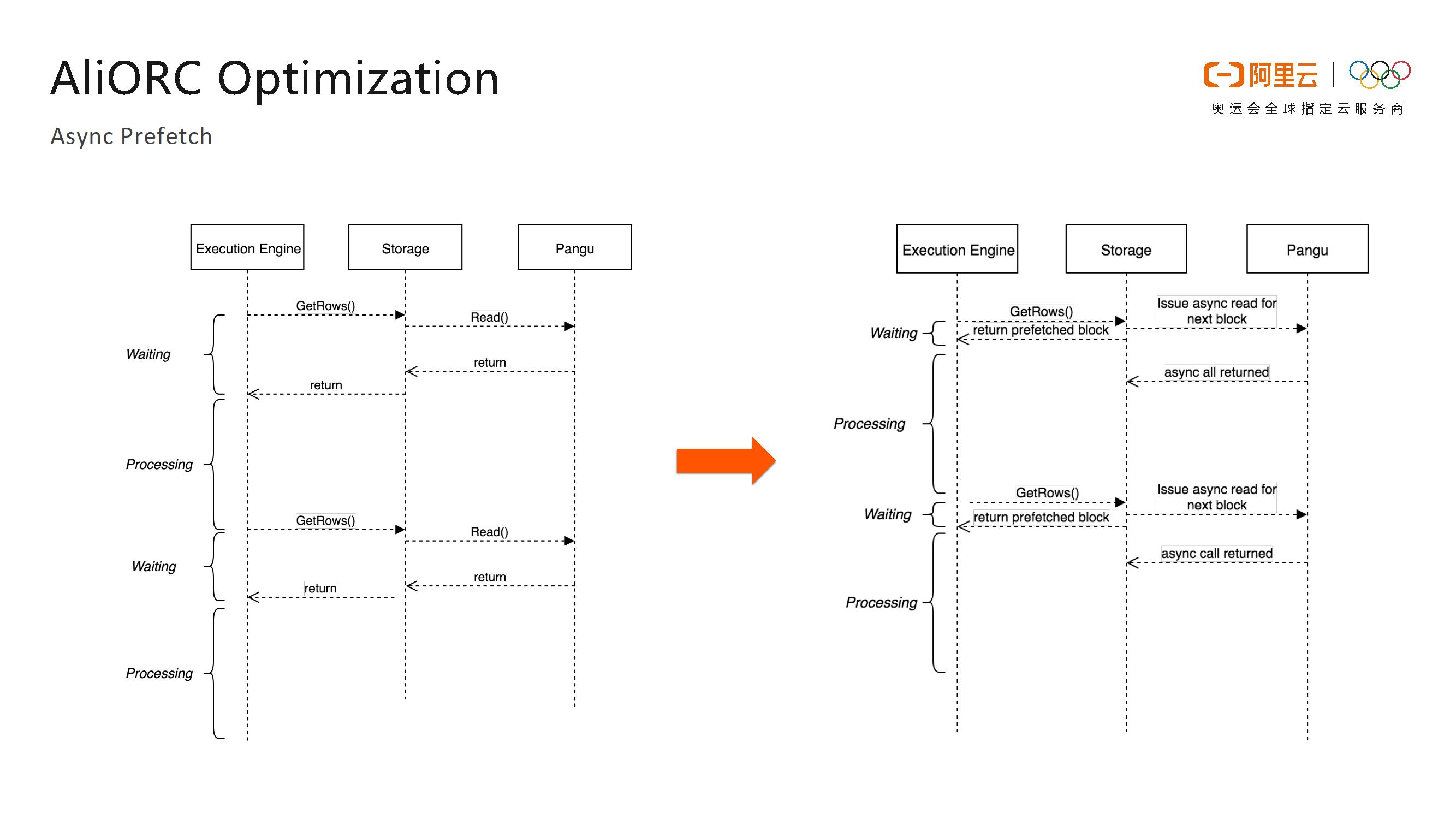
如下图所示的就是打开了异步预读优化前后的性能对比。开启异步预读之前,读取一个文件需要14秒,而在打开异步预读之后则只需要3秒,读取速度提升了数倍。因为将所有的读请求都变成了异步的,当异步请求返回较慢时还是会变成同步请求。从右侧饼图可以看出,实际情况下80%以上的异步请求都是有效的。

- Small I/O Elimination
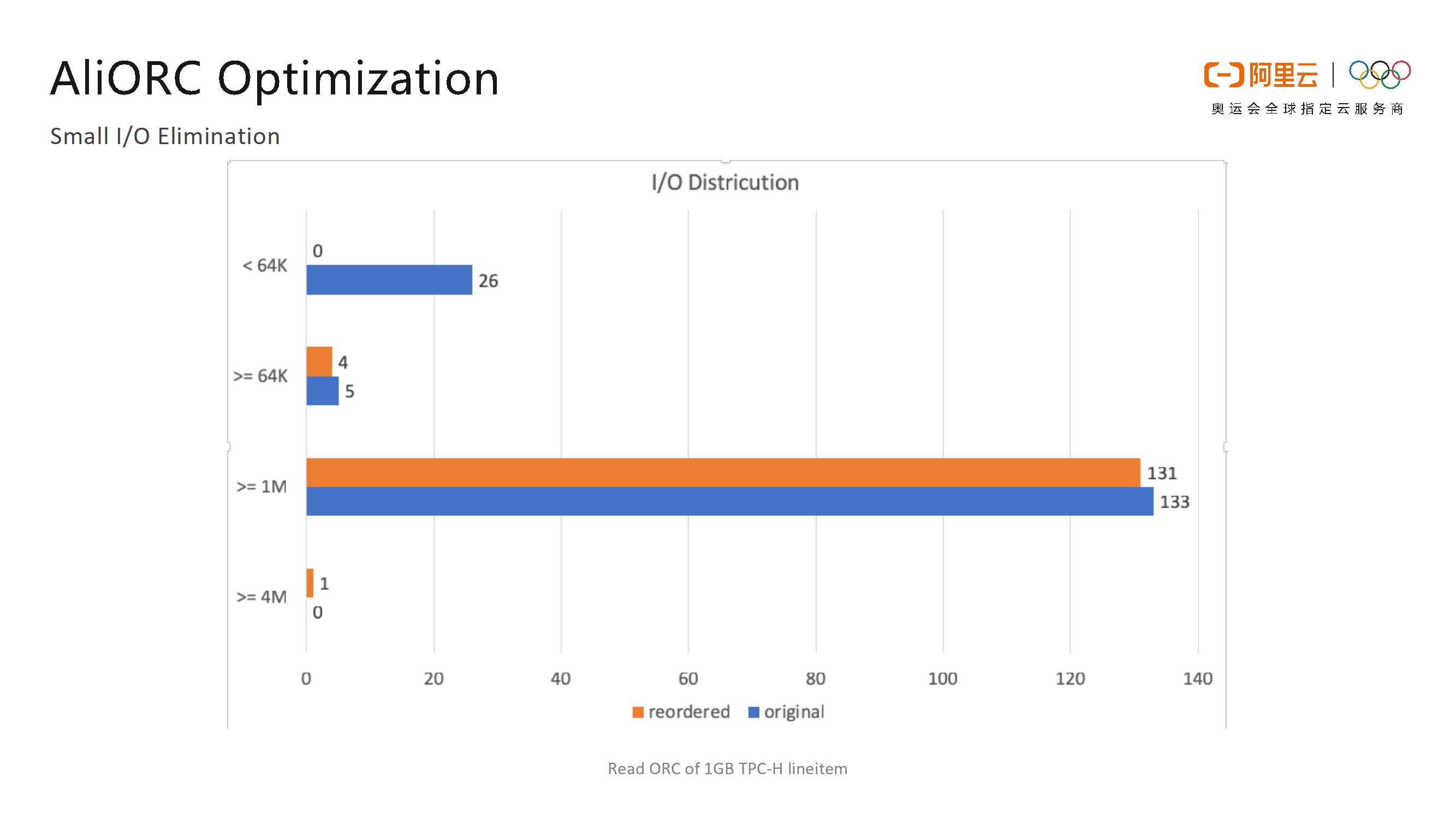
AliORC的第二个优化点就是对于小I/O的消除。在ORC文件中,不同列的文件大小是完全不同的,但是每次读盘都是以列为单位进行数据读取的。这样一来,对于数据量比较小的列而言,读取时的网络I/O开销非常大。为了消除这些小的I/O开销,AliORC在Writer部分针对不同列的数据量进行了排序,在reader端将小数据量的列放在一起形成一个大I/O块,这样不仅减少了小I/O数量,还大大地提升了并行度。

如下图所示的是AliORC打开Small I/O Elimination前后的对比情况。蓝色部分表示的就是打开Small I/O Elimination之前的I/O分布情况,橙色的部分则是表示打开之后的I/O分布情况。可以看到,打开Small I/O Elimination之前,小于64K的I/O有26个,而在打开之后,小于64K的I/O为零,因此Small I/O Elimination的优化效果还是非常显著的。
- Memory Management for streams in each column
AliORC的第三个优化点就是在内存管理 。在开源版本的ORC实现中,Writer的每列数据都使用了一个很大的Buffer去保存压缩后的数据,默认大小为1M,其目的在于 Buffer设置得越大,压缩率越高。但是正如前面所说的,不同列的数据量不同,某些列根本用不到1M大小的Buffer,因此就会造成极大的内存浪费。避免内存浪费的简单方法就是在一开始的时候只给很小的数据块作为Buffer,并且按需分配,如果需要写的数据更多,那么就通过类似C++std::vector的resize 方式提供更大的数据块。原本实现方式中,resize一次就需要进行一次O(N)的操作,将原始数据从老的Buffer拷贝到新的Buffer中去,这样对于性能而言是不可接受的。因此,AliORC开发了新的内存管理结构,分配64K的Block,但是Block与Block之间不是连续的,这虽然会造成很多代码的改动,但是这一改动却是值得的。因为在很多场景下,原来的resize方式需要消耗很多内存,有可能造成内存耗尽,进而导致任务无法完成,而新的方式可以在这种场景下大大降低内存的峰值,效果非常明显。

- Seek Read
AliORC的第四个优化点就是Seek Read方面的优化。这部分解释略微复杂,因此这里以一个例子进行概括。Seek Read原来的问题在于压缩块比较大,每个压缩块中包含很多个Block。在图中,每一万行数据叫做一个Row Group。在Seek Read的场景下,可能会Seek Read到文件中间的某一段,其可能是包含在某一个压缩块中间的,比如图中第7个Row Group被包含在第2个Block中。常规Seek的操作就是先跳转第2个Block的头部,然后进行解压,将第7个Row Group之前的数据先解压出来,再真正地跳转到第7个Row Group处。但是图中绿色的部分数据并不是我们所需要的,因此这一段的数据量就被白白解压了,浪费掉很多计算资源。因此,AliORC的想法就是就是【在写文件的时候】将压缩块Block和Row Group的边界进行对齐,因此Seek到任何的Row Group都不需要进行不必要的解压操作。

如图所示的是进行Seek Read优化前后的效果对比。蓝色部分是优化之前的情况,橙色部分代表优化之后的情况。可以发现,有了对于Seek Read的优化,解压所需的时间和数据量都降低了5倍左右。

- Adapting Dictionary Encoding
字典编码就是针对重复度比较高的字段首先整理出来一个字典,然后使用字典中的序号来代替原来的数据进行编码,相当于将字符串类型数据的编码转化成整型数据的编码,这样可以大大减少数据量。但是ORC编码存在一些问题,首先,不是所有的字符串都适合字典编码,而在原来的数据中,每一列都是默认打开字典编码的,而当文件结束时再判断列是否适合字典编码,如果不适合,再回退到非字典编码。由于回退操作相当于需要重写字符串类型数据,因此开销会非常大。AliORC所做的优化就是通过一个自适应的算法提早决定某一列是否需要使用字典编码,这样就可以节省很多的计算资源。开源的ORC中通过标准库中的std::unordered_map来实现字典编码,但是它的实现方式并不适合MaxCompute的数据,而Google开源的dense_hash_map库可以带来10%的写性能提升,因此AliORC采用了这种实现方式。最后,开源的ORC标准中要求对于字典类型进行排序,但实际上是没有任何必要的,剔除掉该限制可以使得Writer端的性能提高3%。

- Range Alignment for Range Partition
这部分主要是对于Range Partition的优化。如下图右侧的DDL所示,想要将一张表按照某些列进行RANGE CLUSTERED并对这些列的数据进行排序,比如将这些数据存储到4个桶中,分别存储0到1、2到3、4到8以及9到无穷大的数据。这样做的优势在于,在具体实现过程中,每个桶都使用了一个ORC文件,在ORC文件尾部存储了一个类似于B+Tree的索引。当需要进行查询的时候,如果查询的Filter和Range Key相关,就可以直接利用该索引来排除不需要读取的数据,进而大大减少所需要获取的数据量。

对于Range Partition而言,AliORC具有一个很强大的功能,叫做Range对齐。这里解释一下,假设需要Join两张Range Partition的表,它们的Join Key就是Range Partition Key。如下图所示,表A有三个Range,表B有两个Range。在普通表的情况下,这两个表进行Join会产生大量的Shuffle,需要将相同的数据Shuffle到同一个Worker上进行Join操作,而Join操作又是非常消耗内存和CPU资源的。而有了Range Partition之后,就可以将Range的信息进行对齐,将A表的三个桶和B表的两个桶进行对齐,产生如下图所示的三个蓝色区间。之后就可以确定蓝色区间之外的数据是不可能产生Join结果,因此Worker根本不需要读取那些数据。

完成优化之后,每个Worker只需要打开蓝色区域的数据进行Join操作即可。这样就可以使得Join操作能够在本地Worker中完成,而不需要进行Shuffle,进而大大降低了数据传输量,提高了端到端的效率。
四、AliORC为用户带来的价值
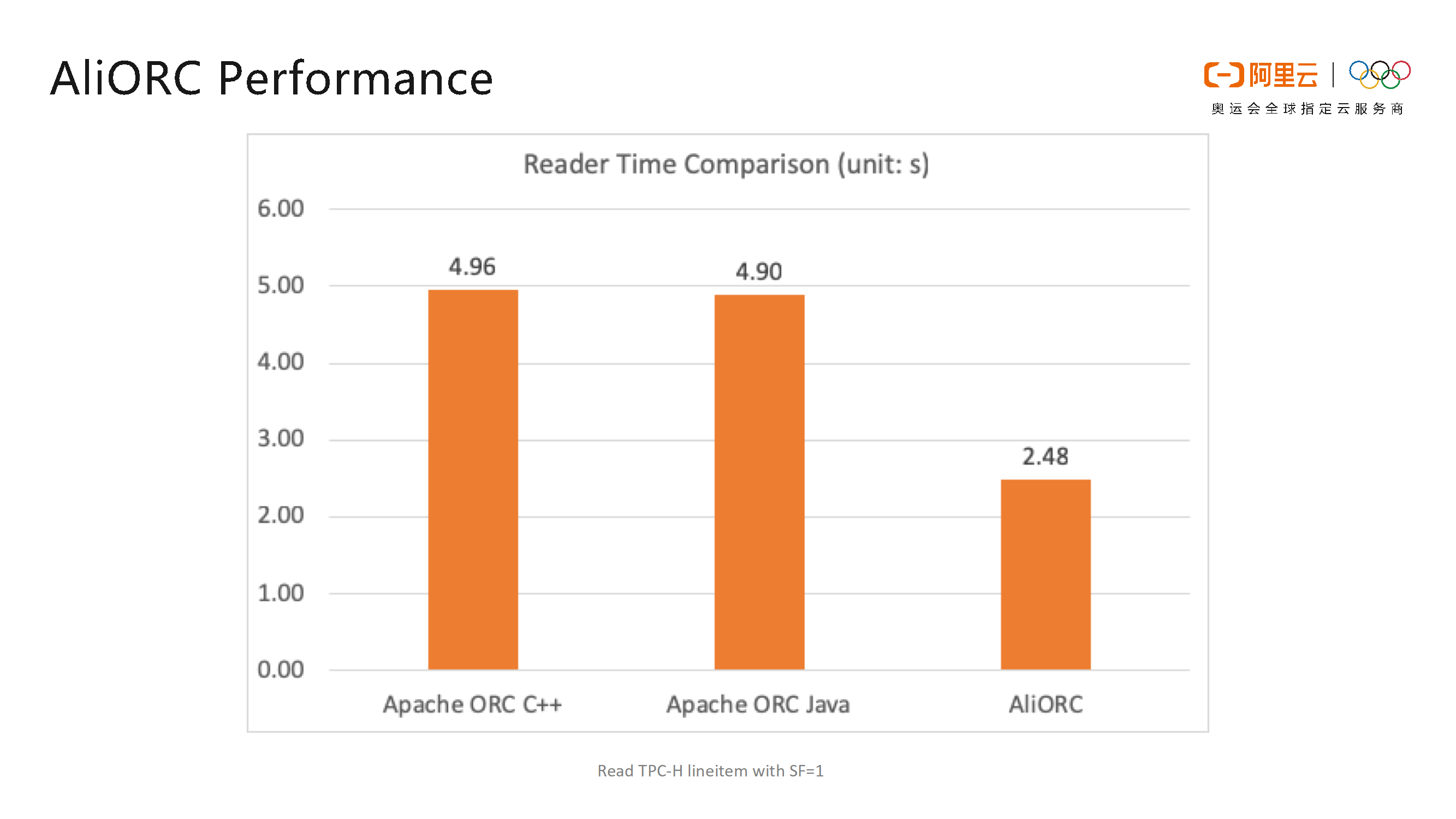
如下图所示的是在阿里巴巴内部测试中AliORC和开源的C++版本ORC以及Java版本ORC的读取时间比较。从图中可以看出AliORC的读取速度比开源ORC要快一倍。
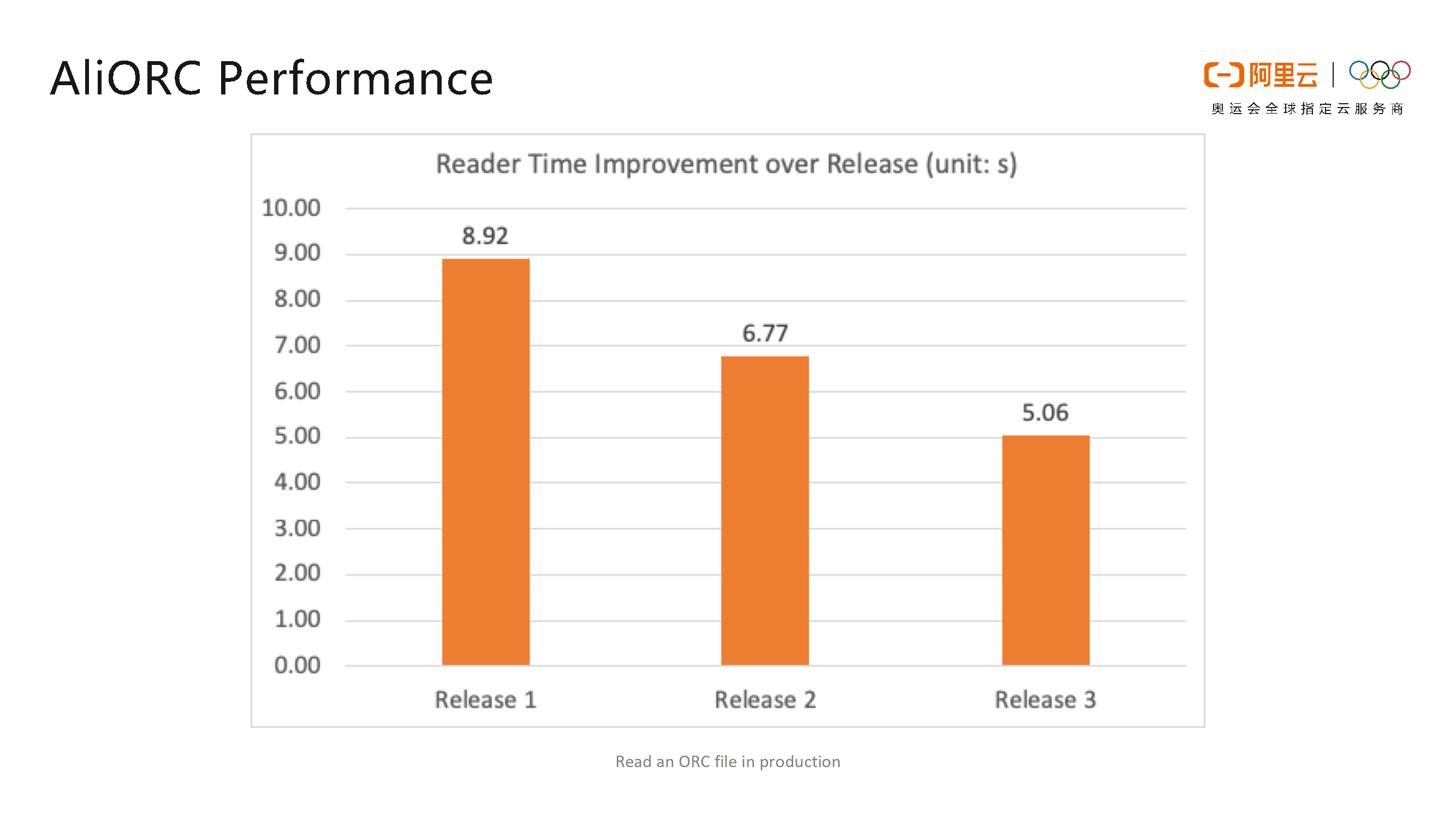
截止2019年5月,在阿里巴巴内部也迭代了3个版本,从下图可以看出,每个版本之间也有接近30%的性能提升,并且还在持续优化当中。目前,AliORC还处于内部使用阶段,尚未在公有云上进行发布,后续也会将AliORC开放出来,让大家共享技术红利。
五、浅谈阿里云MaxCompute相比同类产品的优势
首先,MaxCompute是开箱即用的,也就是说用户无需额外的设置,直接启动MaxCompute服务就可以在其上运行任务了。而使用Hive或者Spark等开源软件可能会存在很多Bug,而对于问题的排查也异常困难,开源社区的修复周期也非常漫长。当用户使用MaxCompute时遇到问题,能够很快地得到反馈并且完成修复。
其次,MaxCompute的使用成本比较低,可以实现按量付费。而使用Hive或者Spark往往需要自建数据中心,这样的做法非常繁琐,建设数据中心不仅需要支付机器成本,还需要自己进行运维。
再次,使用开源的Hive或者Spark,对于技术人员而言,门槛也比较高。因为需要招募一些非常了解Hive和Spark的工程师才能进行维护。而公司自己开发的一些特性往往会和开源版本产生冲突,每次都需要对于冲突进行解决。而当开源版本的软件每次升级之后,就需要将新版本代码下载下来之后再将自己的开发的特性重新加进去,过程异常繁琐。而使用MaxCompute之后,这些工作无需用户关心,阿里巴巴会帮助客户处理这些问题。
对于稳定性而言,MaxCompute做的也非常好。其抗住了历年双11的流量洪峰,而直接使用Hadoop生态系统很难支持很大的体量的任务,往往需要各种深度定制优化。
MaxCompute另外一个优势在于性能,MaxCompute是第一个跑过100TB数据量的TPCx-BB的Benchmark的平台,这是Spark至今没有达到的成就。
此外,开源产品往往不够重视中国市场。Cloudera、Databricks等公司的主要目标客户还是在美国,往往更倾向于根据美国客户需求进行开发,而对于中国市场的支持不够好。MaxCompute则紧跟中国客户的需要,同时也更加适合中国市场。
最后一点就是只有在MaxCompute里面才能使用AliORC这样的文件格式,这也是独有的优势。
总结而言,相比于开源软件,MaxCompute具有需求响应更加及时、成本更低、技术门槛更低、稳定性更高、性能更好、更加适合中国市场等特性。
六、为何选择加入MaxCompute团队
从个人角度而言,我更加看好大数据领域。虽然对于一项技术而言,黄金期往往只有10年,而对于大数据技术而言,已经经历了10年,但我相信大数据技术并不会衰落。尤其是在人工智能技术的加持下,大数据技术仍然有很多需要解决的问题,其技术仍然没有达到的完美。此外,阿里的MaxCompute团队更是人才济济,北京、杭州、西雅图等团队都具有强大的技术实力,能够学习到很多。最后一点,对于开源大数据产品而言,基本上都是国外的天下,而MaxCompute是完全国产自研的平台,加入MaxCompute团队让自己非常骄傲,能够有机会为国产软件尽一份力量。
七、如何走上大数据技术之路的
我走上大数据技术这条路也是机缘巧合的,之前在学校里面所学习的内容与大数据完全没有关系,第一份工作也是视频编码相关的工作,后来在Uber转向大数据相关的岗位。在进入Uber之前,Hadoop组还处于组建的早期,基本上还没有人真正使用Hadoop,大家都是自己搭建一些服务来运行任务。当进入Uber的Hadoop组之后,跟着团队从0到1地学习了Scala、Spark等,从最开始了解如何使用Spark到了解Spark源码,然后慢慢地搭建起大数据平台,接触大数据领域。进入阿里巴巴之后,通过MaxCompute能够从需求、设计、开发、测试以及最后的优化等全部阶段来了解大数据产品,这也是比较宝贵的经历。
八、在阿里巴巴美国办公室的工作体验
在阿里的美国部门其实和在阿里国内的部门差别并不大,可能在西雅图的办公室人数并不是很多,但是“麻雀虽小,五脏俱全”。西雅图办公室各个BU的成员都非常优秀,能够和不同技术方向的同事碰撞出不同的思维火花。并且在阿里巴巴的美国办公室,每年有很多对外交流的机会,也可以组织很多开源的分享。
九、如何成为第一位华人ORC的PMC
这其实是因为MaxCompute团队需要ORC这款产品,而当时开源的C++版本的ORC只有Reader,却没有Writer,因此就需要自行开发C++版本的ORC的Writer。当MaxCompute团队完成之后就希望集合开源的力量将C++版本的ORC的Writer做好,因此将代码贡献回了开源社区,并且得到了开源社区的认可。基于这些工作量,ORC的开源社区给了MaxCompute团队两个Committer名额。成为Committer之后,责任也就更大了,不仅自己需要写代码,还需要和社区一起成长,review其他成员的代码,讨论短期和长期的问题。ORC社区对于自己和MaxCompute团队的工作较为认可,因此授予了PMC的职位。对个人而言,ORC开源的工作也代表了阿里巴巴对于开源的态度,不仅需要在数量上足够多,还需要保证质量足够好。
十、寄语
只要你对于开源感兴趣并乐于持续地贡献,无论拥有什么样的背景和基础,所有的付出最终都会被认可。
本文作者:KB小秘书
本文为云栖社区原创内容,未经允许不得转载。