使用 MaxCompute之前,唱吧使用自建体系来存储处理各端收集来的日志数据,包括请求访问记录、埋点数据、服务器业务数据等。初期这套基于开源组件的体系有力支撑了数据统计、业务报表、风控等业务需求。但随着每天处理数据量的增长,积累的历史数据越来越多,来自其他部门同事的需求越来越复杂,自建体系逐渐暴露出了能力上的短板。同时期,唱吧开始尝试阿里云提供的ECS、OSS等云服务,大数据部门也开始使用 MaxCompute来弥补自建体系的不足。
在内部ELK实现的基础上,从自建机房向MaxCompute进行数据同步工作是比较简单的,实践中我们主要采取两种方式:一是利用阿里云提供的datahub组件,直接对接logstash;二是把待同步数据落地到文件,然后使用tunnel命令行工具上传至MaxCompute的对应表中。
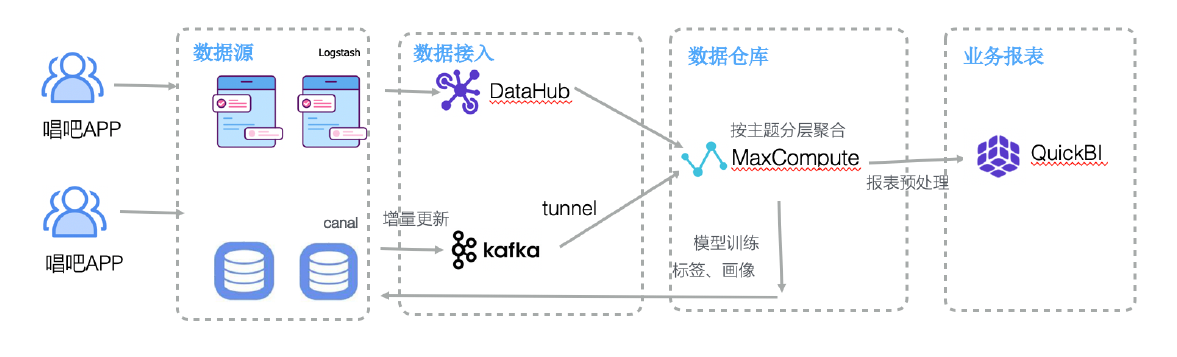
数据进入MaxCompute后,我们按照数据的主题和使用场景构造了三层结构:原始数据层ODS、中间数据层MDS、报表数据层DM。ODS层中保存直接同步的数据,在此基础上加工整理到的原始表,例如增量同步的原mysql表,经过风控清洗的访问日志表等。MDS层存放原始层数据聚合、抽象加工过的结果,这一层的数据表更可读、读取计算时更经济,一般情况下要求其他部门的同事使用这一层的数据。DM层是处理理的最终结果,支持QuickBI直接读取进行报表展示,同时也支持同步回自建机房,供其他业务使用。
目前除了某些对实时要求比较高的场景还使用自建体系外,MaxCompute承担了唱吧全部的离线计算工作。每天有近千个任务定时运行,处理TB级别的数据,生成上百个数据报表在QuickBI进行展示。可视化的管理理界面和基于SQL的计算方式大大降低了使用门槛,提升了效率。除此之外,推荐和风控业务也都利用了MaxCompute的计算能力,实现了对需求的快速跟进和迭代。MaxCompute云服务和自建体系的结合,让我们能充分满足业务需求,在效率成本和灵活性上取得了很好的平衡。
下一步,对于MaxCompute我们有几个方向上的计划:
一是利用机器学习能力,进一步挖掘数据的价值。
二是对那些历史比较久的冷数据,利用MaxCompute的外表功能,定期转移至OSS等服务中,保证可读的基础上降低成本。
三是评估阿里云的实时计算服务,作为自建体系的补充。
本文作者:马星显 (唱吧大数据负责人)
本文为云栖社区原创内容,未经允许不得转载。