前言
计算机软件技术发展到现在,软件架构的演进无不朝着让开发者能够更加轻松快捷地构建大型复杂应用的方向发展。容器技术最初是为了解决运行环境的不一致问题而产生的,随着不断地发展,围绕容器技术衍生出来越来越多的新方向。
最近几年,云计算领域不断地出现很多新的软件架构模式,其中有一些很热门的概念名词如:云原生、函数计算、Serverless、ServiceMesh等等,而本文将初窥一下ServiceMesh的面纱。下面结合自己的理解尽量以通俗的话进行叙述。
背景和定义
微服务及服务治理
在微服务之前的软件开发中,往往通过一个应用的方式将所有的模块都包括进去,并一起编译、打包、部署、运维。这种方式存在很多问题,由于单个应用包含的东西太多,其中某个模块出现问题或者需要更新那么整个应用就需要重新部署。这种方式给开发和运维带来了很大的麻烦。随着应用的逐渐复杂,单个应用涉及的东西就会越来越多,慢慢地大家发现了其中很多的缺点,开始对服务进行划分,将一个大的应用按照不同的维度进行划分从而产生很多个小的应用,各应用之间会形成一个调用关系,每个小的应用由不同的开发负责,大家各自部署和运维,这样微服务就出现了。
由于微服务中各应用部署在不同的机器上,服务之间需要进行通信和协调,相比单个应用来说会麻烦很多。在同一个应用内不同方法之间的调用由于在相同的内存中,在代码编译打包时已经进行了链接,因此调用是可寻址且快速的。微服务下不同服务之间的调用涉及到不同进程或者机器之间的通信,一般需要通过第三方中间件的方式作为中介和协调,由于种种这些,面向微服务出现了很多中间件包括服务治理的框架。通过服务治理工具可以管理其接入的所有应用,使得服务之间的通信和协调更加简单高效。
容器及容器编排
最初容器技术是为了解决应用运行环境不一致的问题而出现的,避免在本地环境或者测试环境能够跑通,等发到生产环境却出现问题。通过容器将程序及其依赖一起打包到镜像中去,将程序的镜像在任何安装并运行了容器软件的机器上启动若干的容器,每个容器就是应用运行时的实例,这些实例一般拥有完全相同的运行环境和参数。使得不管在任何机器上应用都可以表现出一样的效果。这给开发、测试、运维带来了极大的便利,不再需要为不同机器上构建相同的运行环境而头大。且镜像可以Push到镜像仓库,这使得应用可以进行很方便的迁移和部署。Docker就是一个应用广泛的容器技术。目前越来越多的应用以微服务的方式并通过容器进行部署,给了软件开发极大的活力。
与微服务和服务治理的关系类似,越来越多的应用通过容器进行部署,使得集群上的容器数量急剧增加,通过人工的管理和运维这些容器已经变得很艰难且低效,为了解决诸多容器及容器之间的关系出现了很多编排工具,容器编排工具能够管理容器的整个生命周期。如Docker官方出的docker-compose和docker swarm,这两个工具能实现批量容器的启动和编排,但功能较为简单,不足以支撑大型的容器集群。Google基于内部大量的容器管理经验,开源出了Kubernetes项目,Kubernetes(K8S)是针对Google集群上每周亿级别的容器而设计的,具有很强大的容器编排能力和丰富的功能。K8S通过定义了很多资源,这些资源以声明式的方式进行创建,可以通过JSON或者YAML文件表示一个资源,K8S支持多种容器,但主流的是Docker容器,K8S提供了容器接入的相关标准,只要容器实现了该标准就可以被K8S所编排。由于K8S的功能较多,不在此一一叙述,有兴趣可以参考官方文档或者ATA上搜索相关文章。
当某个公司的应用已经完全微服务化后,选择以容器的方式部署应用,此时可以在集群上部署K8S,通过K8S提供的能力进行应用容器的管理,运维可以也可以面向K8S进行工作。由于K8S是目前使用最广泛的容器编排工具,因此成为了容器编排的一个标准了,目前集团内部也有自己的容器和容器编排工具。
面向以K8S为代表的容器管理方式衍生出了一些新的技术。
云原生
最近两年云原生被炒的很火,可以在各处看到很多大佬对云原生的高谈阔论,下面直接抛出CNCF对云原生的定义:
云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API。
这些技术能够构建容错性好、易于管理和便于观察的松耦合系统。结合可靠的自动化手段,云原生技术使工程师能够轻松地对系统作出频繁和可预测的重大变更。
在我看来,通过微服务的方式开发应用,以容器进行部署,使用K8S等容器编排工具进行容器集群的管理,使得开发运维都面向K8S,这就是云原生。云原生可以方便的构建应用,并对应用进行完整的监控,以及在应用针对不同流量时能进行快速的扩容和缩容。如下图:
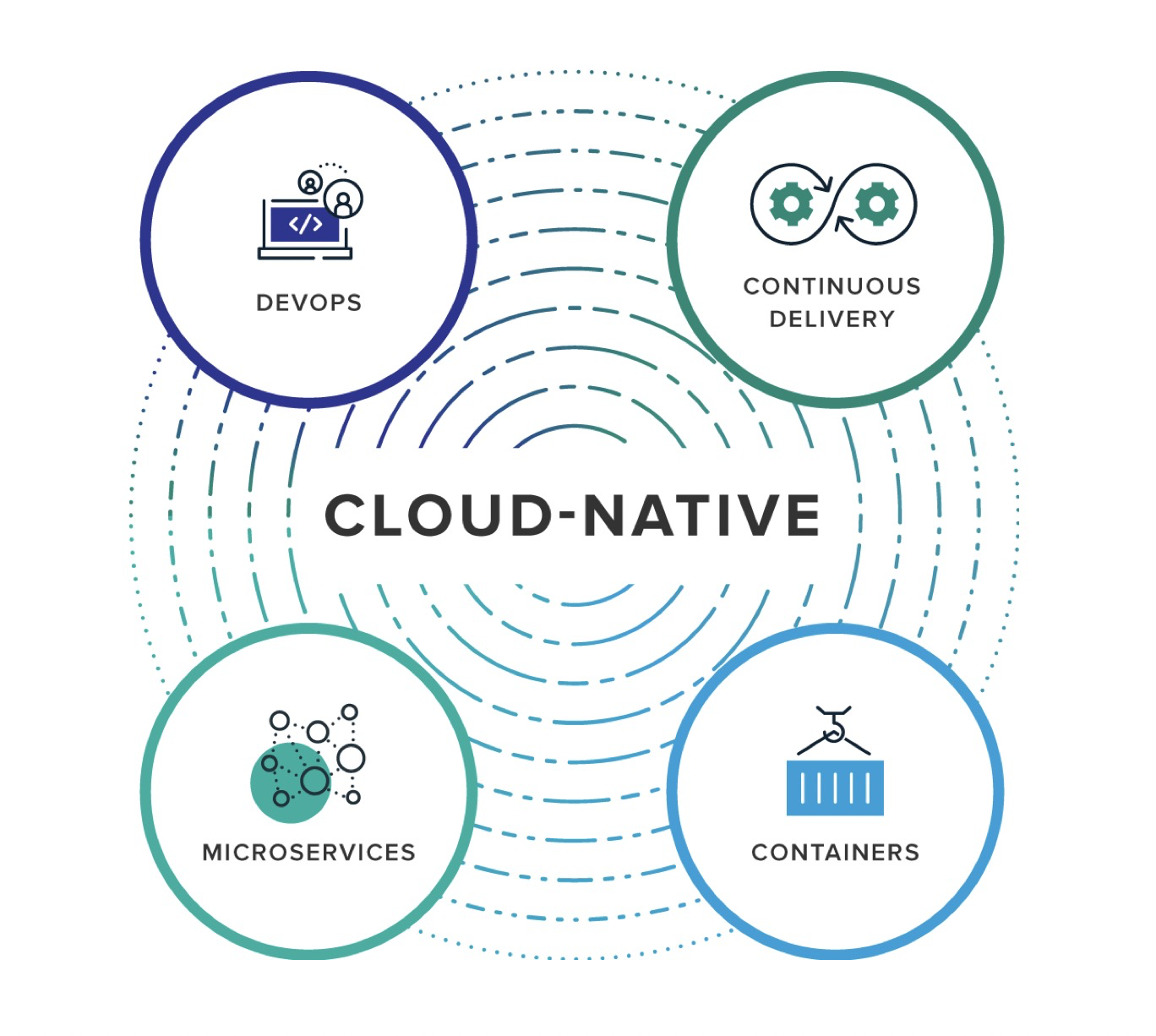
云原生主要包括四个部分:
- 微服务
- 容器
- 持续集成和交付
- DevOps
PS:总是觉得云原生这个叫法太抽象了,很难让人通过名字想到这是个啥东西。
ServiceMesh的定义
前面讲了微服务、容器、容器编排、云原生等,其实就是为了得出什么是ServiceMesh,自己总结了一下:SeviceMesh是云原生下的微服务治理方案。
当我们通过微服务的方式将应用以容器的形式部署在K8S上后,服务之间调用和治理其实有新的方案,可以不需要依赖传统的微服务治理框架。ServiceMesh通过对每个应用在其Pod中启动一个Sidecar(边车)实现对应用的透明代理,所有出入应用的流量都先经过该应用的Sidecar,服务之间的调用转变成了Sidecar之间的调用,服务的治理转变成了对Sidecar的治理。在ServiceMesh中Sidecar是透明的,开发无感知的,之前一直觉得奇怪,总觉得一个应用要让别人发现它从而调用它,总得引入一些库然后进行主动的服务注册,不然啥都不做,别人咋知道这个应用的存在,为什么在ServiceMesh中就可以省去这些,做到对开发者完全地透明呢?这个的实现依赖于容器编排工具,通过K8S进行应用的持续集成和交付时,在启动应用Pod后,其实已经通过Yaml文件的形式向K8S注册了自己的服务以及声明了服务之间的关系,ServiceMesh通过和K8S进行通信获取集群上所有的服务信息,通过K8S这个中间者实现了对开发者的透明。如下图所示,是ServiceMesh的一个基本结构,包括数据平面和控制平面。
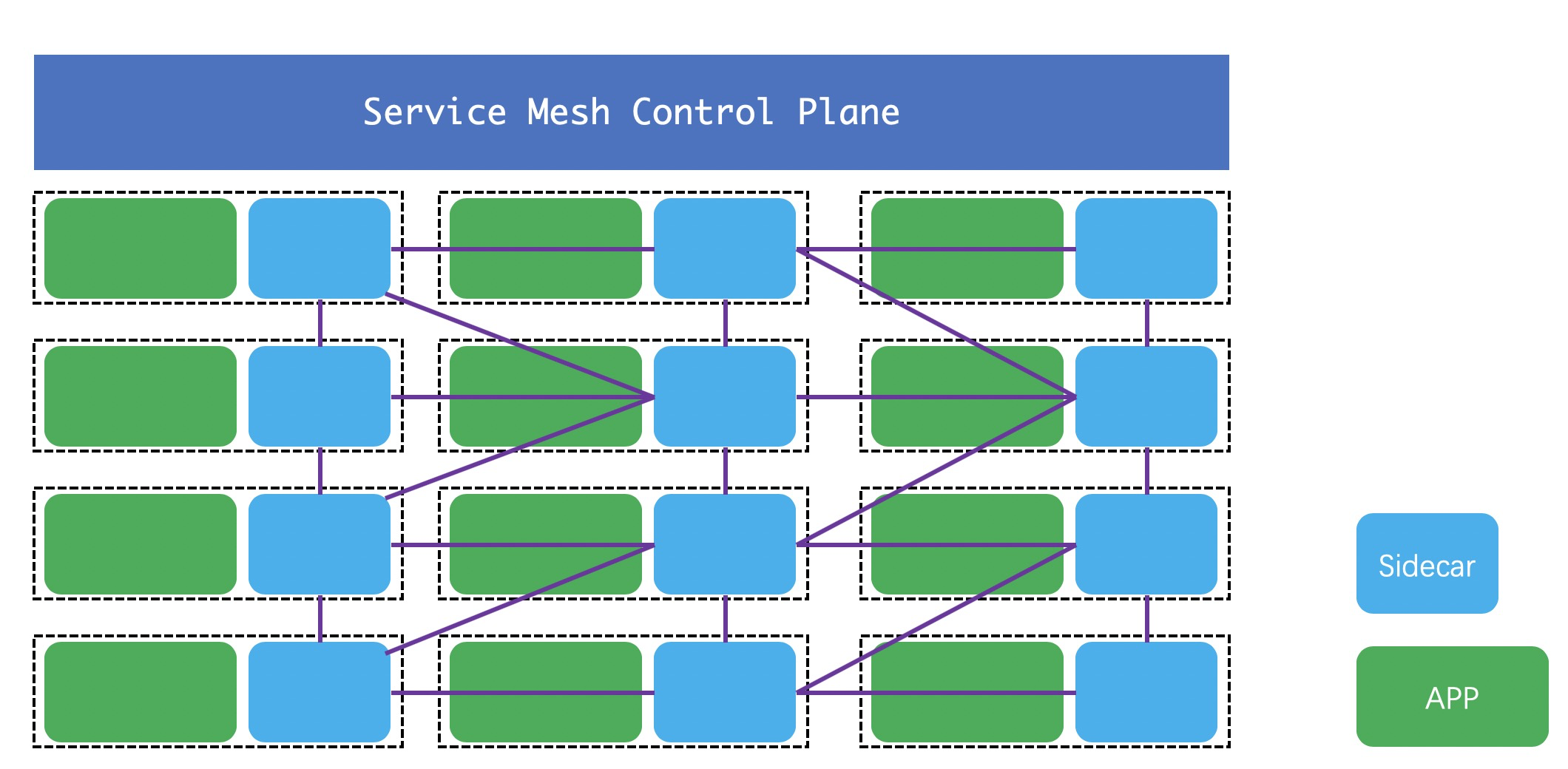
这种方式存在很多好处,我们可以发现在这种模式下应用的语言其实不会对整个服务治理过程有什么影响,对于ServiceMesh来说,它只关心Pod或者说是Pod中的容器实例,并不需要在乎容器中应用的实现语言是啥,Sidecar和其负责的容器在同一个Pod中。这样ServiceMesh就可以实现跨语言,这也是目前很多传统的服务治理框架的一大缺点,而且采用传统的服务治理,需要对应用引入大量的依赖,这样就会造成依赖之间的各种冲突,集团通过Pandora对应用的各种依赖进行隔离。再者传统的服务治理门槛较高,需要开发者对整个架构有一定的了解,且发现问题排查较为麻烦。这也造成了开发和运维之间的界限不清,在ServiceMesh中开发只需要交付代码,运维可以基于K8S去维护整个容器集群。
发展现状
通过目前查阅的资料来看,ServiceMesh一词最早出现在2016年,最近两年被炒的很火,蚂蚁金服已经有了自己的一套完整的ServiceMesh服务框架--SofaMesh,集团很多团队也在进行相应的跟进。
从历史发展的路线来看,程序的开发方式经历了很多的变化,但总的方向是变得越来越简单了,现在我们在集团内进行开发,可以很简单的构建一个支撑较大QPS的服务,这得益于集团的整个技术体系的完整和丰富以及强大的技术积淀。
我们下面来看看应用开发到底经历了啥?
发展历史
主机直接阶段

如上图,这一阶段应该是最古老的阶段,两台机器通过网线直接连接,一个应用包含了你能想到的所有的功能,包括两台机器的连接管理,这时还没有网络的概念,毕竟只能和通过网线直接连接在一起的机器进行通信。
网络层的出现
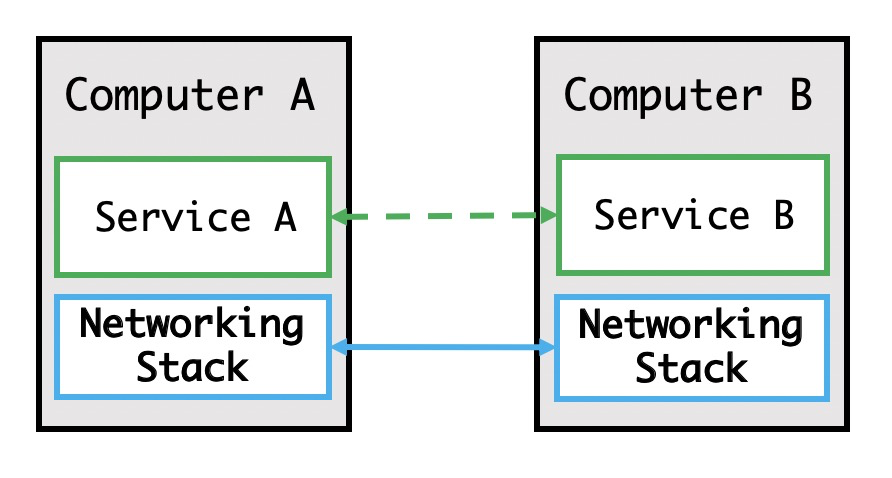
如上图,随着技术的发展,网络层出现了,机器可以和通过网络连接的其他所有机器进行通信,不再限制于必须要网线直连两台机器。
集成到应用程序内部的流量控制

如上图,由于每个应用所在环境和机器配置不一样,接受流量的能力也不相同,当A应用发送的流量大于了B应用的接受能力时,那么无法接收的数据包必定会被丢弃,这时就需要对流量进行控制,最开始流量的控制需要应用自己去实现,网络层只负责接收应用下发的数据包并进行传输。
流量控制转移到网络层
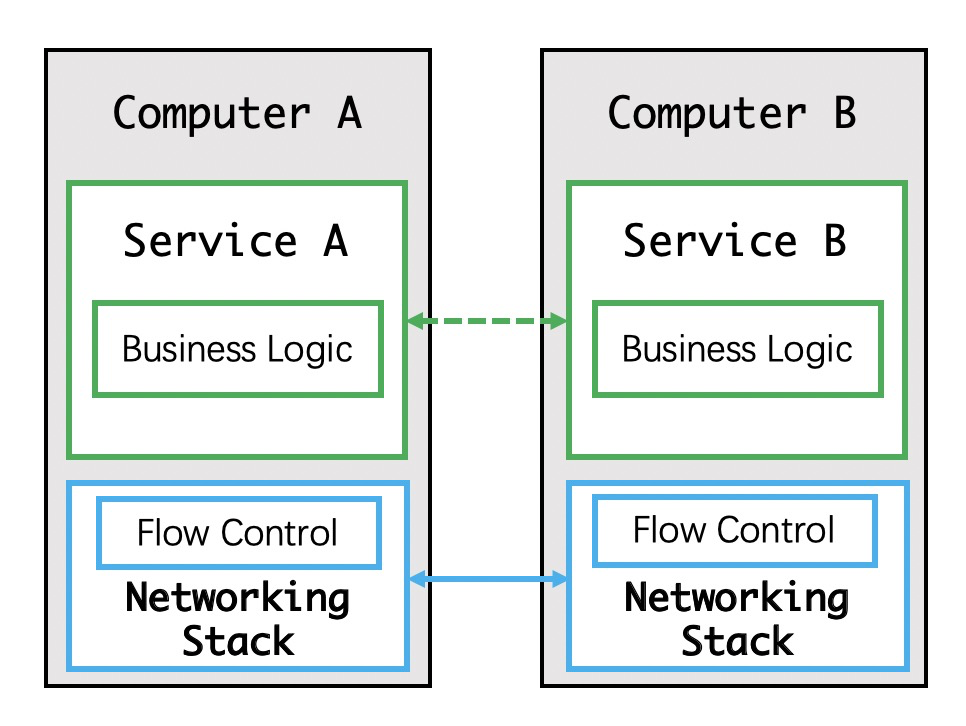
如上图,慢慢地大家发应用中的网络流量控制是可以转移到网络层的,所以网络层中的流量控制出现了,我想大概就是指TCP的流量控制吧,这样还能保证可靠的网络通信。
应用程序的中集成服务发现和断路器
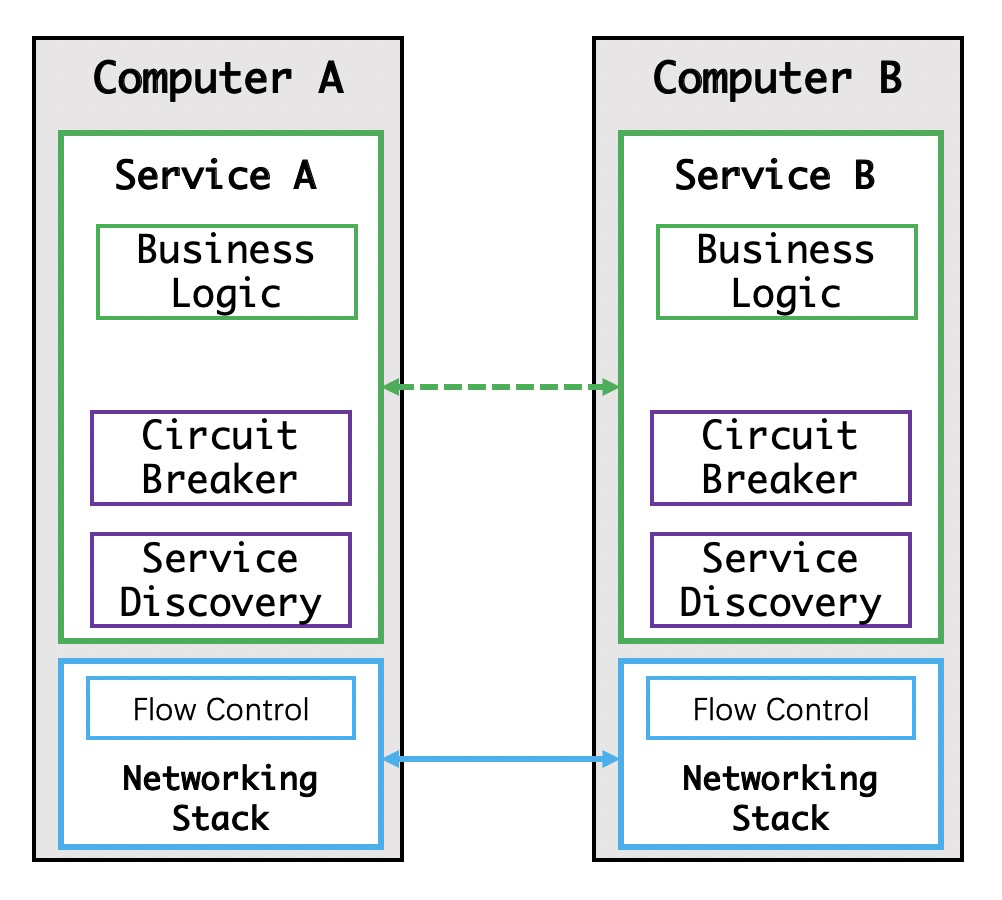
如上图,开发者通过在自己的代码模块中实现服务发现和断路器。
专门用于服务发现和断路器的软件包/库

如上图,开发者通过引用第三方依赖去实现服务发现和断路器。
出现了专门用于服务发现和断路器的开源软件
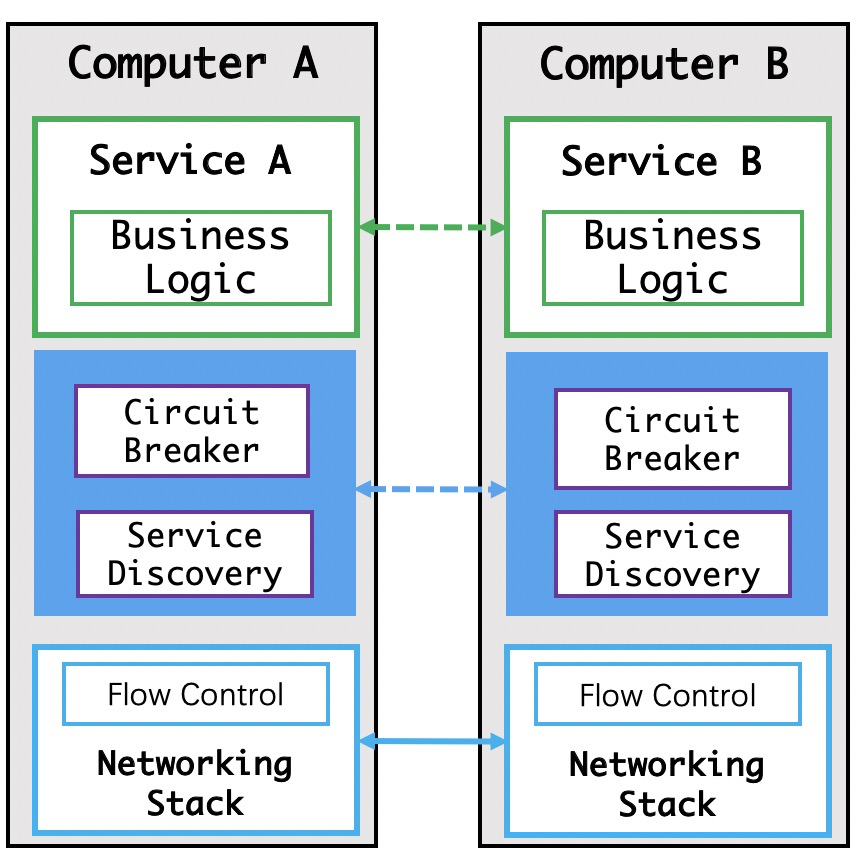
如上图,基于各种中间件去实现服务发现和断路器。
ServiceMesh出现
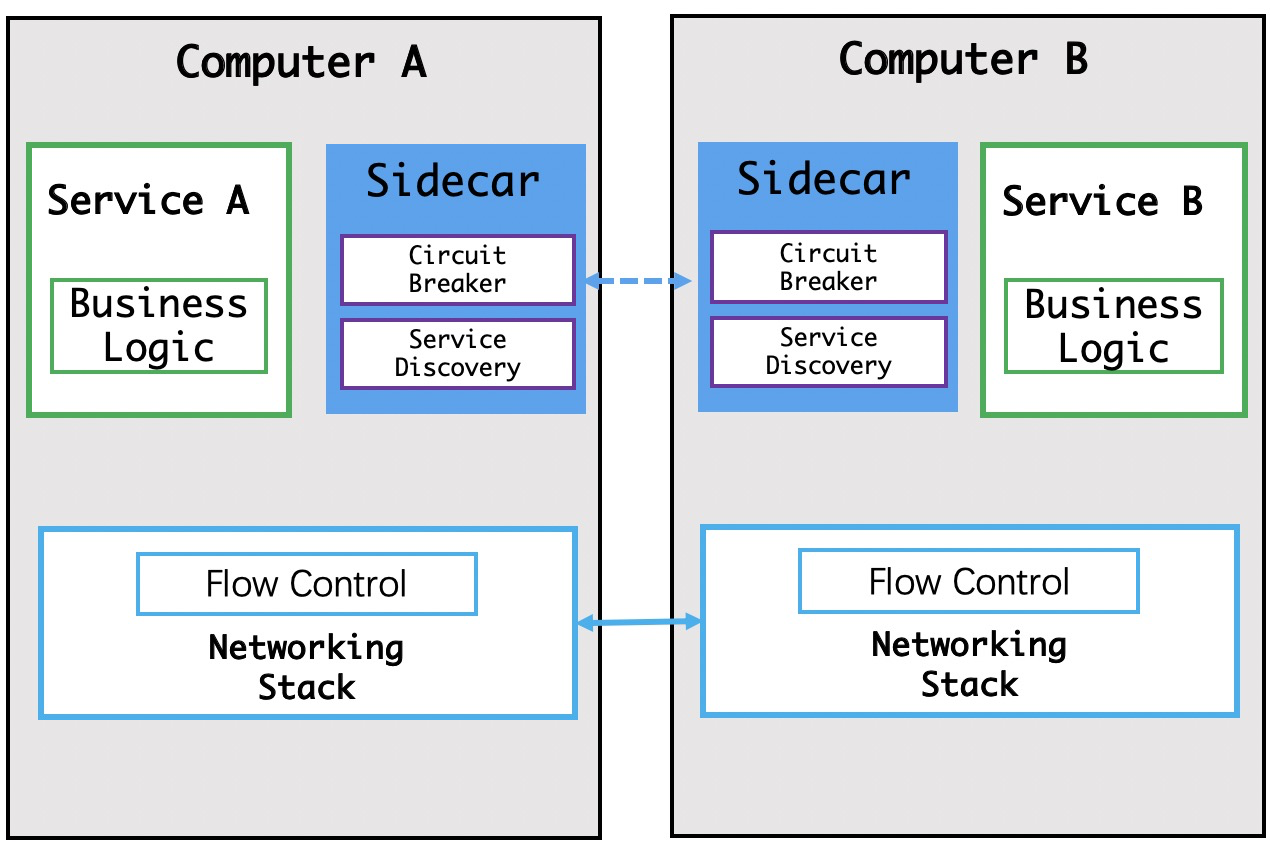
最终到了现在,ServiceMesh大法诞生,进一步解放了生产力,提高了软件整个生命周期的效率。
ServiceMesh市场竞争
虽然直到2017年底,ServiceMesh才开始较大规模被世人了解,这场微服务市场之争也才显现,但是其实ServiceMesh这股微服务的新势力,早在 2016年初就开始萌芽:
2016年1月,离开Twitter的基础设施工程师William Morgan和Oliver Gould,在github上发布了Linkerd 0.0.7版本,业界第一个ServiceMesh项目就此诞生。Linkerd基于Twitter的Finagle开源项目,大量重用了Finagle的类库,但是实现了通用性,成为了业界第一个ServiceMesh项目。而Envoy是第二个ServiceMesh项目,两者的开发时间差不多,在2017年都相继成为CNCF项目。2017年5月24日,Istio 0.1 release版本发布,Google和IBM高调宣讲,社区反响热烈,很多公司在这时就纷纷站队表示支持Istio。Linkerd的风光瞬间被盖过,从意气风发的少年一夜之间变成过气网红。当然,从产品成熟度上来说,linkerd作为业界仅有的两个生产级ServiceMesh实现之一,暂时还可以在Istio成熟前继续保持市场。但是,随着Istio的稳步推进和日益成熟,外加第二代ServiceMesh的天然优势,Istio取代第一代的Linkerd只是个时间问题。自从在2016年决定委身于Istio之后,Envoy就开始了一条波澜不惊的平稳发展之路,和Linkerd的跌宕起伏完全不同。在功能方面,由于定位在数据平面,因此Envoy无需考虑太多,很多工作在Istio的控制平面完成就好,Envoy从此专心于将数据平面做好,完善各种细节。在市场方面,Envoy和Linkerd性质不同,不存在生存和发展的战略选择,也没有正面对抗生死大敌的巨大压力。
从Google和IBM联手决定推出Istio开始,Istio就注定永远处于风头浪尖,无论成败,Istio面世之后,赞誉不断,尤其是ServiceMesh技术的爱好者,可以说是为之一振:以新一代ServiceMesh之名横空出世的Istio,对比Linkerd,优势明显。同时产品路线图上有一大堆令人眼花缭乱的功能。假以时日,如果Istio能顺利地完成开发,稳定可靠,那么这会是一个非常美好、值得憧憬的大事件,

Istio介绍
Istio是目前最热的ServiceMesh开源项目,Istio主要分为两个部分:数据平面和控制平面。Istio实现了云原生下的微服务治理,能实现服务发现,流量控制,监控安全等。Istio通过在一个Pod里启动一个应用和Sidecar方式实现透明代理。Istio是一个拓展性较高的框架,其不仅可以支持K8S,还可以支持其他如Mesos等资源调度器。如下图所示,为Istio的整体架构:

- 逻辑上分为数据平面(上图中的上半部分)和控制平面(上图中的下半部分)。
- 数据平面由一组以 Sidecar 方式部署的智能代理(Envoy)组成。这些代理可以调节和控制微服务及 Mixer 之间所有的网络通信。
- 控制平面负责管理和配置代理来路由流量。此外控制平面配置 Mixer 以实施策略和收集遥测数据。
- Pilot是整个架构中的抽象层,将对接K8S等资源调度器的步骤进行抽象并以适配器的形式展现,并和用户以及Sidecar交互。
- Galley负责资源配置为验证。
- Citadel用于生成身份,及密钥和证书管理
- 核心功能包括流量控制、安全控制、可观测性、多平台支持、可定制化。
Mixer
Mixer同样是一个可拓展的模块,其负责遥感数据的采集以及集成了一些后端服务(BAAS),Sidecar会不断向Mixer报告自己的流量情况,Mixer对流量情况进行汇总,以可视化的形式展现,此外Sidecar可以调用Mixer提供的一些后端服务能力,例如鉴权、登录、日志等等,Mixer通过适配器的方式对接各种后端服务。
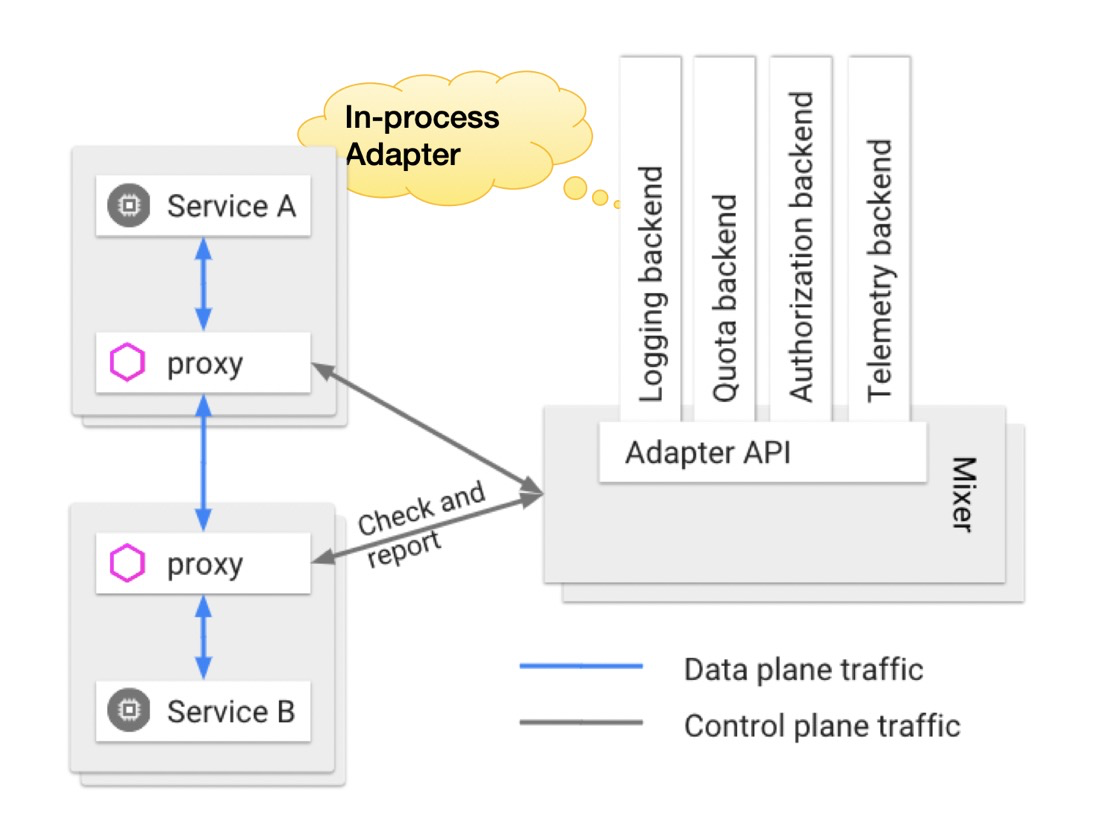
In-process Adapter形式
之前版本的Isito采用这种将后端服务适配器集成在Mixer内部的形式,这种方式会有一个问题,就是某个后端服务适配器出现问题即会影响整个Mixer模块,但由于适配器和Mixer集成在一起,在同一个进程内,方法的调用会很快。

Out-of-process Adapter形式
目前版本的Istio将Adapter移到Mixer外部,这样可以实现Mixer与Adapter的解耦,当Adapter出现问题并不会影响Mixer,但这种方式同样也存在问题,即Adapter在Mixer外,是两个不同的进程,二者之间的调用是通过RPC的方式,这种方式比同进程内部的方法调用会慢很多,因此性能会受到影响。
Pilot
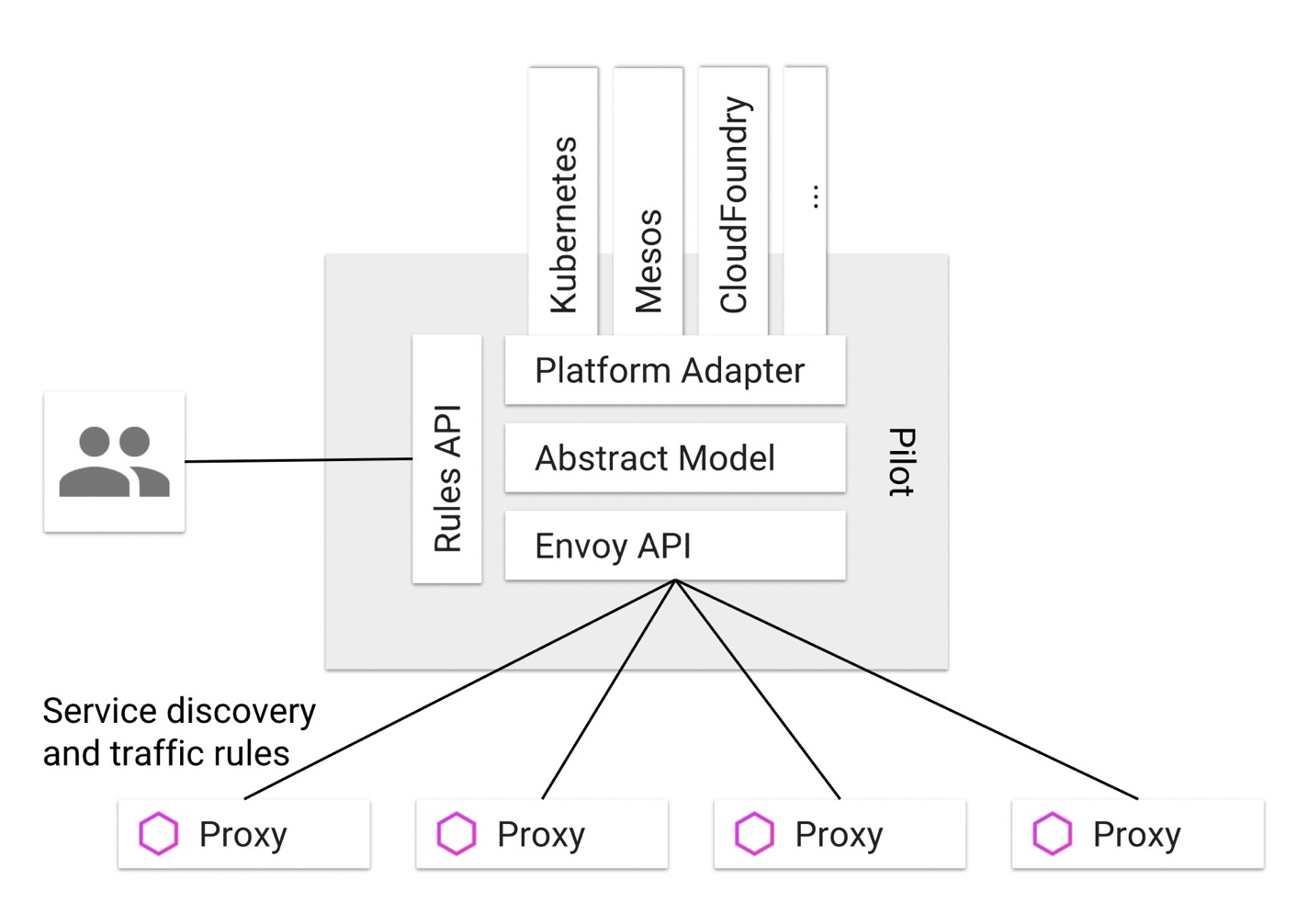
- Envoy API负责和Envoy的通讯, 主要是发送服务发现信息和流量控制规则给Envoy。
- Abstract Model 是 Pilot 定义的服务的抽象模型, 以从特定平台细节中解耦, 为跨平台提供基础。
- Platform Adapter则是这个抽象模型的实现版本, 用于对接外部的不同平台如k8s/mesos等。
- Rules API提供接口给外部调用以管理 Pilot, 包括命令行工具Istioctl以及未来可能出现的第三方管理界面。
Galley
Galley 原来仅负责进行配置验证, 1.1 后升级为整个控制面的配置管理中心, 除了继续提供配置验证功能外, Galley还负责配置的管理和分发, Galley 使用 网格配置协议(Mesh Configuration Protocol) 和其他组件进行配置的交互.
Istio 创造了50多个CRD, 其复杂度可见一斑, 所以有人说面向k8s编程近似于面向yaml编程.早期的Galley 仅仅负责对配置进行运行时验证, Istio 控制面各个组件各自去list/watch 各自关注的配置。越来越多且复杂的配置给Istio用户带来了诸多不便, 主要体现在:
- 配置的缺乏统一管理, 组件各自订阅, 缺乏统一回滚机制, 配置问题难以定位。
- 配置可复用度低, 比如在1.1之前, 每个Mixer adpater 就需要定义个新的CRD。
- 配置的隔离, ACL 控制, 一致性, 抽象程度, 序列化等等问题都还不太令人满意
随着Istio功能的演进, 可预见的Istio CRD数量还会继续增加, 社区计划将Galley 强化为Istio配置控制层, Galley 除了继续提供配置验证功能外, 还将提供配置管理流水线, 包括输入, 转换, 分发, 以及适合Istio控制面的配置分发协议(MCP)。
Citadel
将服务拆分为微服务之后,在带来各种好处的同时,在安全方面也带来了比单体时代更多的需求,毕竟不同功能模块之间的调用方式从原来单体架构中的方法调用变成了微服务之间的远程调用:
- 加密:为了不泄露信息,为了抵御中间人攻击,需要对服务间通讯进行加密。
- 访问控制:不是每个服务都容许被任意访问,因此需要提供灵活的访问控制,如双向 TLS 和细粒度的访问策略。
- 审计:如果需要审核系统中哪些用户做了什么,则需要提供审计功能。
Citadel 是 Istio 中负责安全性的组件,但是 Citadel 需要和其他多个组件配合才能完成工作:
- Citadel:用于密钥管理和证书管理,下发到Envoy等负责通讯转发的组件。
- Envoy:使用从Citadel下发而来的密钥和证书,实现服务间通讯的安全,注意在应用和Envoy之间是走Localhost,通常不用加密。
- Pilot:将授权策略和安全命名信息分发给Envoy。
- Mixer:负责管理授权,完成审计等。
Istio支持的安全类功能有:
- 流量加密:加密服务间的通讯流量。
- 身份认证:通过内置身份和凭证管理可以提供强大的服务间和最终用户身份验证,包括传输身份认证和来源身份认证,支持双向TLS。
- 授权和鉴权:提供基于角色的访问控制(RBAC),提供命名空间级别,服务级别和方法级别的访问控制。
作者信息:彭家浩,花名毅忻,阿里巴巴淘系技术部开发工程师,热爱云计算。
附加信息
笔者工作于阿里巴巴淘系技术部开放平台和聚石塔团队,一个即专注技术也专注业务的团队,我们真诚地希望能有更多对云计算、云原生等方面有激情的小伙伴加入我们!期待!
招聘详情点击这里。
笔者邮箱:jiahao.jiahaopeng@alibaba-inc.com
本文作者:彭家浩
本文为云栖社区原创内容,未经允许不得转载。